<오라클 성능 고도화 원리와 해법1> Ch01-04 Redo
오라클 성능 고도화 원리와 해법1 - Ch01 오라클 아키텍처 - 04 Redo
오라클은 데이터파일과 컨트롤 파일에 가해지는 모든 변경 사항을 하나의 Redo 로그 엔트리로서 Redo 로그에 기록한다. (물론 데이터 파일에 대한 변경은 캐시된 블록 버퍼를 통해 이루어진다.) Redo 로그는 Online Redo와 Archived Redo 로그로 구성된다.
Online Redo 로그는 Redo 로그 버퍼에 버퍼링된 로그 엔트리를 기록하는 파일로서, 최소 두 개 이상의 파일로 구성된다. 현재 사용 중인 Redo 로그 파일이 꽉 차면 다음 Redo 로그 파일로 로그 스위칭(log switching)이 발생하며, 계속 Redo 로그를 써나가다가 모든 Redo 로그 파일이 꽉 차면 다시 첫 번째 Redo 로그 파일부터 재사용하는 라운드 로빈(round-robin) 방식을 사용한다.
Archived Redo 로그는 Online Redo 로그가 재사용되기 전에 다른 위치로 백업해 둔 파일을 말한다.
Redo 로그는 아래 3가지 목적을 위해 사용된다.
- Database Recovery
- Cache Recovery (Instance Recovery 시 roll forward 단계)
- Fast Commit
첫째, Redo 로그는 물리적으로 디스크가 깨지는 등의 Media Fail 발생 시 데이터베이스를 복구하기 위해 사용되며, 이때는 Archived Redo 로그를 이용하게 된다. 이를 ‘Media Recovery’ 라고도 한다.
둘째, Redo 로그는 Cache Recovery를 위해 사용되며, 다른 말로 ‘Instance Recovery’ 라고도 한다. 모든 데이터베이스 시스템이 버퍼 캐시를 도입하는 것은 I/O 성능을 향상시키기 위함이지만, 버퍼 캐시는 휘발성이다. 따라서 캐시에 저장된 변경 사항이 디스크 상의 데이터 블록에 아직 기록되지 않은 상태에서 정전 등이 발생해 인스턴스가 비정상적으로 종료되면, 그때까지의 작업 내용을 모두 잃게 된다. 이러한 트랜잭션 데이터의 유실에 대비하기 위해 Redo 로그를 사용한다.
Instance Crash 발생 후 시스템을 재기동하면 우선 Online Redo 로그에 저장된 기록 사항들을 읽어들여 마지막 체크포인트(Checkpoint) 이후부터 사고 발생 직전까지 수행되었던 트랜잭션들을 재현한다 (-> roll forward 단계). 그러면 버퍼 캐시에만 수정하고 데이터 파일에는 반영되지 않았던 변경 사항들이 복구되며, 이는 트랜잭션의 커밋 여부를 불문하고 일단 버퍼 캐시를 시스템이 셧다운되기 이전 상태로 되돌리는 것이다.
Cache Recovery가 완료되면, 뒤에서 설명할 Undo 데이터를 이용해 시스템이 셧다운되는 시점에 아직 커밋되지 않았던 트랜잭션들을 모두 롤백하는, 이른바 ‘Transaction Recovery’가 진행된다(-> rollback 단계). 이렇게 roll forward와 rollback 단계를 모두 완료하고 나면 커밋되지 않은 기록 사항들은 모두 제거되어 데이터파일에는 커밋에 성공한 데이터만 남게 되며, 데이터베이스는 완전히 동기화된 상태가 된다.
마지막으로, Redo 로그는 Fast Commit을 위해 사용된다. 변경된 메모리 버퍼 블록을 디스크 상의 데이터 블록에 기록하는 작업은 Random 액세스 방식으로 이루어지기 때문에 느리다. 반면, 로그는 Append 방식으로 기록하므로 상대적으로 매우 빠르다. 따라서 트랜잭션 발생 시 건건이 데이터 파일에 기록하기보다 우선 변경 사항을 Append 방식으로 빠르게 로그 파일에 기록하고, 메모리 데이터 블록과 데이터 파일 간 동기화는 적절한 수단(DBWR, Checkpoint)을 이용해 나중에 배치(Batch) 방식으로 일괄 수행한다.
사용자의 갱신 내용이 메모리 상의 버퍼 블록에만 기록된 채 아직 디스크에 기록되지 않았지만, Redo 로그를 믿고 빠르게 커밋을 완료한다는 의미에서, 이런 메커니즘을 ‘Fast Commit’이라고 부른다. 적어도 커밋 정보가 로그에 기록되어 있기만 하다면 인스턴스 Crash가 발생하더라도 Redo 로그를 이용해 언제든 Recovery가 가능한 상태가 되므로 오라클은 안심하고 커밋을 완료할 수 있는 것이다.
Fast Commit은 오라클에만 있는 기능이 아니며, 빠르게 트랜잭션을 처리해야 하는 모든 DBMS의 공통적인 메커니즘이다. 그런데 Fast Commit을 구현하는 데 있어 오라클만의 특징적인 기능이 있는데, ‘Delayed 블록 클린아웃(Cleanout)’이 바로 그것이다. 완전한 커밋을 위해서는 Lock을 해제하는 일까지 완료해야 하는데, 다른 DBMS는 Lock 매니저를 통해 로우 Lock을 관리하기 때문에 커밋 시점에 빠르게 Lock 리소스를 해제할 수 있다.
반면 오라클은 별도의 Lock 매니저 없이 레코드의 속성으로서 로우 Lock을 구현(다음 절에서 설명하는 ‘Lock Byte’ 참조)했기 때문에 Lock을 해제하려면 갱신했던 블록들을 일일이 찾아야 한다. 따라서 Redo 로그에 기록하는 것만으로는 커밋을 빠르게 처리할 수 없는 구조다. 그래서 오라클은 ‘Delayed 블록 클린아웃(Cleanout)’이라는 추가적인 메커니즘을 사용한다. 커밋 시점에는 Undo 세그먼트 헤더의 트랜잭션 테이블에만 커밋 정보를 기록하고, 블록 클린아웃(갱신된 블록에 커밋 정보를 기록하고 Lock을 해제하는 작업)은 나중에 수행하도록 하는 것을 말하며, 이에 대해서는 8절에서 자세히 다룬다.
Redo 레코드를 기록할 때도 곧바로 Redo 로그 파일에 저장하는 것은 아니며 먼저 Redo 로그 버퍼에 기록한다. 즉, 데이터 블록 버퍼를 변경하기 전에 항상 Redo 로그 버퍼에 먼저 기록하고 일정 시점마다 LGWR 프로세스에 의해 Redo 로그 버퍼에 있는 내용을 Redo 로그 파일에 기록하는 것이다. LGWR가 Redo 로그 버퍼를 Redo 로그에 기록하는 시점은 다음과 같다.
① 3초마다 DBWR 프로세스로부터 신호를 받을 때 (DBWR은 Dirty 버퍼를 데이터 파일에 기록하기 전에 로그 버퍼 내용을 Redo 로그 파일에 기록하도록 LGWR에게 신호를 보냄) ② 로그 버퍼의 1/3이 차거나 기록된 Redo 레코드량이 1MB를 넘을 때 ③ 사용자가 커밋 또는 롤백 명령을 날릴 때
Fast Commit 메커니즘의 핵심은 3번이라고 할 수 있는데, 다시 말하지만 트랜잭션이 영속성을 보장받으려면 최소한 커밋 시점에는 Redo 정보가 메모리가 아닌 디스크 상에 안전하게 저장되었음이 확인되어야 한다(Log Force at Commit).
①과 ②는 대량의 트랜잭션이 발생해 이를 메모리에서 파일로 일괄 반영하려고 할 때 작업량이 한꺼번에 몰리는 것에 대비해 주기적으로 Dirty 버퍼를 해소하고 로그 버퍼를 비우도록 구현된 부차적인 기능이다. 부차적이라고는 하지만 그렇게 하지 않으면 ‘느린 Fast Commit’이 될 수 있기 때문에 중요하다.
①에서 DBWR가 Dirty 버퍼를 데이터 파일에 기록하기 전에 로그 버퍼에 먼저 Redo 로그를 기록하도록 하는 이유는 뭘까? 앞서 얘기했듯이 Instance Crash 발생 시 Redo 로그에 기록된 내용을 재현해 캐시 블록을 복구하고 최종적으로 커밋되지 않은 트랜잭션은 롤백하게 되는데, Redo 로그에는 없는 변경 내역이 이미 데이터 파일에 기록돼 있으면 사용자가 최종 커밋하지 않은 트랜잭션이 커밋된 결과를 초래하기 때문이다.
정리해보면, 버퍼 캐시에 있는 블록 버퍼를 갱신하기 전에 먼저 Redo 엔트리를 로그 버퍼에 기록해야 하며, DBWR가 버퍼 캐시로부터 Dirty 블록들을 디스크에 기록하기 전에 먼저 LGWR가 해당 Redo 엔트리를 모두 Redo 로그 파일에 기록했음이 보장되어야 한다. 이를 ‘Write Ahead Logging’이라고 한다.
Fast Commit 메커니즘을 그림 1-11을 보면서 정리해보자.
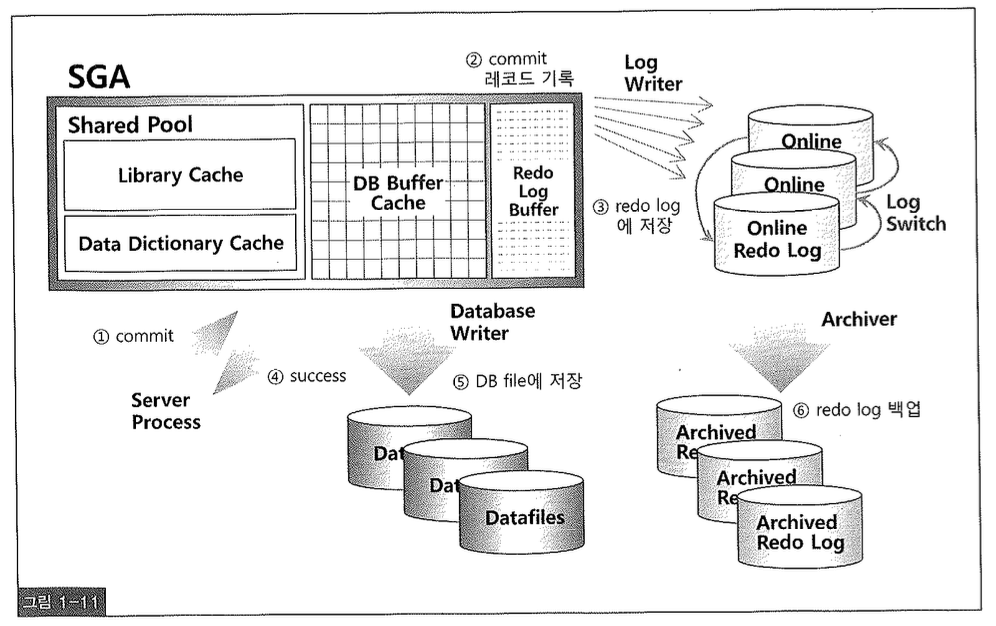
① 사용자가 커밋을 날리면 ② 서버 프로세스는 커밋 레코드를 Redo 로그 버퍼에 기록하고 ③ LGWR는 이것을 즉시 트랜잭션 로그 엔트리와 함께 redo 로그파일에 저장하고나서 ④ 커밋을 수행한 트랜잭션에 “Success code”를 리턴한다. 여기까지 완료되면 아직 사용자의 갱신 내용이 메모리 상의 데이터 버퍼에만 기록된 채 디스크에 기록되지 않았지만 Instance Crash가 발생해도 Redo 로그를 이용해 언제든 복구 가능한 상태가 되었으므로 오라클은 안심하고 커밋을 완료할 수 있는 것이다(Log Force at Commit).
시스템을 모니터링해보면 사용자가 커밋 또는 롤백할 때마다 log file sync 라는 대기(wait) 이벤트가 발생하는 것을 볼 수 있는데, 이는 LGWR 프로세스가 로그 버퍼 내용을 Redo 로그 파일에 기록할 때까지 서버 프로세스가 대기하는 현상 때문에 발생한다.