<오라클 성능 고도화 원리와 해법1> Ch01-05 Undo
오라클 성능 고도화 원리와 해법1 - Ch01 오라클 아키텍처 - 05 Undo
과거에는 롤백(Rollback)이라는 용어를 주로 사용했지만, 9i부터 오라클 사는 공식 문서에 Undo라는 용어를 사용하고 있다.
9i부터 AUM(Automatic Undo Management) 기능이 도입되면서 그런 수동 작업이 불필요해져 Undo 세그먼트 개념을 많이 생소하게 느끼는 것 같다. Undo 세그먼트는 구조적으로 볼 때 데이터를 저장하는 일반 테이블 세그먼트와 별반 다르지 않다. 테이블 세그먼트와 마찬가지로 익스텐트(Extent) 단위로 확장되고, 빠른 읽기/쓰기를 위해 Undo 블록들을 버퍼 캐시에 캐싱하며, 데이터 유실을 방지하기 위해 그 변경 사항을 Redo 로그에 로깅하는 점도 같다.
다른 점이라면 Undo 세그먼트에 저장하는 내용인데, 각 트랜잭션별로 Undo 세그먼트를 할당해 주고(두 개 이상의 트랜잭션이 하나의 Undo 세그먼트를 할당받아 같이 사용할 수 있음) 그 트랜잭션이 발생시킨 테이블과 인덱스에 대한 변경사항들을 Undo 레코드 단위로 Undo 세그먼트 블록에 차곡차곡 기록한다.
[Automatic Undo Management]
9i에서는 AUM(Automatic Undo Management)이 도입되어 Undo 세그먼트마다 하나의 트랜잭션이 할당되는 것을 목표로 세그먼트 개수를 오라클이 자동 관리한다.
Undo 세그먼트에 저장된 정보는 아래 3가지 목적을 위해 사용한다.
- Transaction Rollback
- Transaction Recovery (Instance Recovery 시 rollback 단계)
- Read Consistency
첫째, 트랜잭션에 의한 변경 사항을 최종 커밋하지 않고 롤백하고자 할 때 Undo 데이터를 이용한다.
둘째, 앞서 Redo에서 설명했듯이 Instance Crash 발생 후 Redo를 이용해 Roll forward 단계가 완료되면 최종 커밋되지 않은 변경사항까지 모두 복구된다. 따라서 시스템이 셧다운된 시점에 아직 커밋되지 않았던 트랜잭션들을 모두 롤백해야 하는데, 이때 Undo 세그먼트에 저장된 Undo 데이터를 사용한다.
마지막으로, Undo 데이터는 읽기 일관성(Read Consistency)을 위해 사용되는데, 본서는 SQL 튜닝 원리를 설명하는 책이므로 이 부분이 가장 중요한 관심사항이다. DB2, SQL Server, Sybase 등은 Lock을 통해 읽기 일관성을 구현하지만, 오라클은 Undo 데이터를 이용해 읽기 일관성을 구현한다. 다음 절에서 아주 자세히 다룰 텐데, 오라클만의 독특한 읽기 일관성을 이해하려면 지금부터 설명하는 Undo 메커니즘에 대한 이해가 필수적이다.
(1) Undo 세그먼트 트랜잭션 테이블 슬롯
그림 1-12는 Undo 세그먼트를 간략히 표현한 것으로, Undo 세그먼트 중 첫 번째 익스텐트의, 그중에서도 첫 번째 블록에는 Undo 세그먼트 헤더(Header) 정보가 담긴다.
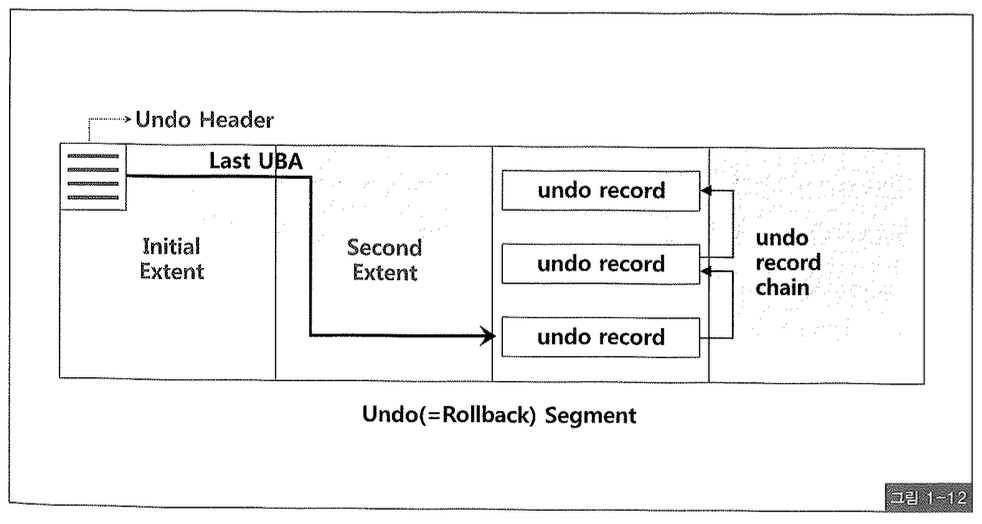
Undo 세그먼트 헤더에는 트랜잭션 테이블 슬롯(Transaction Table Slot)이 위치하는데, 각 슬롯에 기록되는 사항들은 아래와 같다.
- 트랜잭션 ID
- 트랜잭션 상태 정보(Transaction Status)
- 커밋 SCN (트랜잭션이 커밋된 경우)
- Last UBA (Undo Block Address)
- 기타
트랜잭션 ID는 [USN# + Slot# + Wrap#]으로 구성된다. USN은 Undo Segment Number의 약자다. 트랜잭션 ID 구성을 보면 알 수 있듯이, 트랜잭션을 시작하려면 먼저 Undo 세그먼트에 있는 트랜잭션 테이블로부터 슬롯(Slot)을 할당받아야 하며, 할당받은 슬롯에 자신이 현재 Active 상태임을 표시하고서 갱신을 시작한다.
이제부터 트랜잭션이 발생시키는 데이터 또는 인덱스 블록에 대한 변경사항은 Undo 블록에 Undo 레코드로서 하나씩 차례대로 기록된다. 각 DML 오퍼레이션별로 Undo 레코드에 기록되는 내용은 아래와 같다:
- Insert: 추가된 레코드의 rowid
- Update: 변경되는 컬럼에 대한 before image
- Delete: 지워지는 로우의 모든 컬럼에 대한 before image
4번 Last UBA(Undo Block Address)는 트랜잭션의 기록 사항들을 가장 마지막 Undo 레코드 뒤에 계속 추가해 나가려고 유지하는 일종의 포인터다. 그리고 각 Undo 레코드 간에는 체인 형태로 연결되어 있어 데이터를 롤백하고자 할 때 이 체인을 따라 거슬러 올라가며 작업을 수행하게 된다(그림 1-12).
인덱스가 전혀 없는 테이블이라면 한 건을 갱신할 때마다 used_urec 값이 하나씩 증가하지만 인덱스가 딸려 있다면 인덱스 엔트리에 대한 갱신 내용까지 값에 포함된다는 사실을 기억할 필요가 있다. 예를 들어, insert 또는 delete 시에는 인덱스 하나당 하나의 Undo 레코드가 추가되고, update 시에는 인덱스 하나당 두 개의 Undo 레코드가 추가된다. 인덱스 엔트리를 update 할 때는 내부적으로 delete & insert 방식으로 수행되기 때문이다.
아직 커밋되지 않은, Active 상태의 트랜잭션이 사용하는 Undo 블록과 트랜잭션 테이블 슬롯은 절대 다른 트랜잭션에 의해 재사용되지 않는다. 사용자가 커밋해 트랜잭션이 완료되면 트랜잭션 상태 정보를 ‘committed’로 변경하고 그 시점의 커밋 SCN을 트랜잭션 슬롯에 저장해둔다. 이제 이 트랜잭션 슬롯과 Undo 블록들은 다른 트랜잭션에 의해 재사용될 수 있다. 하지만 가장 먼저 커밋된 트랜잭션 슬롯부터 순차적으로(in a circular fashion) 재사용되기 때문에 Undo 데이터는 커밋 후에도 상당기간 남아있게 된다.
[Undo Retention]
9i에서 AUM이 도입되면서 새롭게 생긴 파라미터가 undo_retention인데, 이는 트랜잭션이 완료되었어도 지정한 시간 동안은 “가급적” Undo 데이터를 재사용하지 말라고 오라클에 힌트를 주는 것이다. 오라클은 Undo Extent에 대한 상태 정보(active, unexpired, expired)를 주기적으로 관리하며, 이를 위해 Undo 테이블 스페이스에 할당된 모든 Extent의 Commit Time을 목록(List)으로 관리한다. undo_retention으로 지정된 시간을 기준으로 unexpired 상태의 Extent들을 expired 상태로 변경하며, Undo Extent가 필요할 때면 expired 상태의 Extent부터 재사용한다. 하지만 undo_retention은 강제성을 갖지 않기 때문에 expired Extent가 없고 새로 할당할 공간까지 부족해지면 unexpired 상태의 Extent라도 언제든 재사용할 수 있다.
Undo 테이블 스페이스에 guarantee 옵션을 설정하면, 공간이 부족해 에러를 발생시키는 한이 있더라도 undo_retention으로 지정된 시간 내에 커밋된 Undo 정보는 재사용하지 않는다.
(2) 블록 헤더 ITL 슬롯
지금까지 Undo 세그먼트에 대해 살펴봤고, 이제 블록에 저장되는 ITL 슬롯과 Lock Byte에 대해 알아보자.
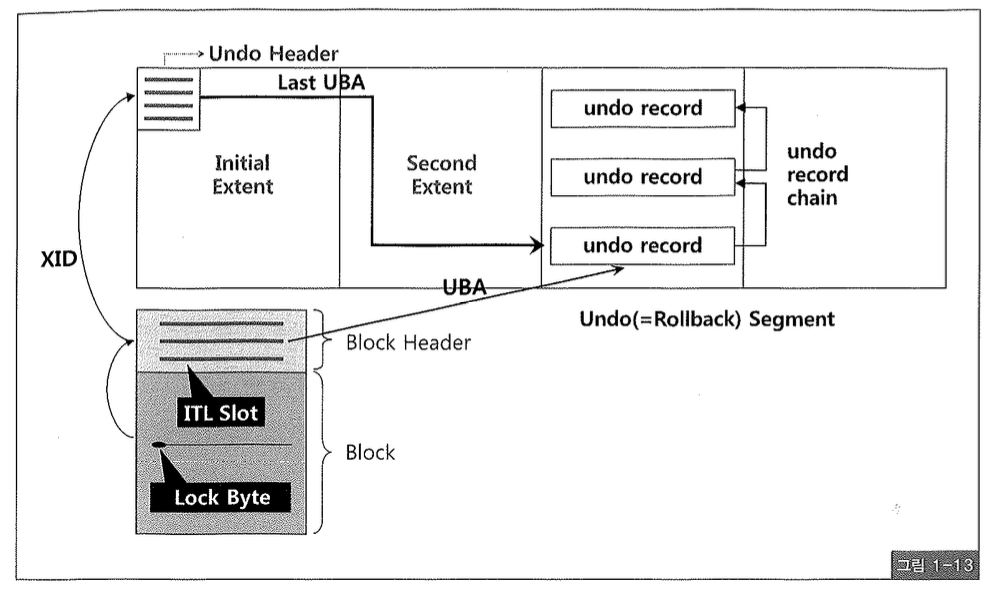
Undo 세그먼트 헤더에 트랜잭션 테이블 슬롯이 있다면, 각 데이터 블록과 인덱스 블록 헤더에는 ITL(Interested Transaction List) 슬롯이 있다(그림 1-13). ITL 슬롯에 기록되는 내용은 다음과 같다.
- ITL 슬롯 번호
- 트랜잭션 ID
- UBA (Undo Block Address)
- 커밋 Flag
- Locking 정보
- 커밋 SCN (-> 트랜잭션이 커밋된 경우)
트랜잭션을 시작하려면, Undo 세그먼트 트랜잭션 테이블로부터 슬롯을 먼저 확보하듯이, 특정 블록에 속한 레코드를 갱신하려면 먼저 블록 헤더로부터 ITL 슬롯을 확보해야 한다. 거기에 트랜잭션 ID를 기록하고 현재 해당 트랜잭션이 Active 상태임을 표시한 후에야 블록 갱신이 가능하다. ITL 슬롯을 할당받지 못하면 트랜잭션은 계속 진행하지 못하고 블로킹(Blocking) 되었다가, 해당 블록을 갱신하던 앞선 트랜잭션 중 하나가 커밋 또는 롤백될 때 비로소 ITL 슬롯을 얻어 작업을 계속 진행할 수 있게 된다.
오라클은 ITL 슬롯 부족 때문에 트랜잭션이 블로킹되는 현상을 최소화할 수 있도록 3가지 옵션을 제공한다. 테이블과 인덱스를 생성할 때 initrans, maxtrans, pctfree 파라미터를 지정하는데, initrans는 블록을 사용하려고 처음 포맷할 때 블록 헤더에 ITL 슬롯을 몇 개 할당할지를 결정하는 파라미터다. 블록 헤더에 미리 할당해둔 ITL 슬롯이 모두 사용 중이라면 maxtrans로 지정된 개수만큼 데이터 영역에 추가 ITL 슬롯을 할당할 수 있다. 단, pctfree에 의해 예약된 공간이 update(인덱스는 insert)에 의해 모두 사용되고 없다면 ITL을 할당받지 못해 Lock 경합이 발생하게 된다.
(3) Lock Byte
이제 블록 헤더에서 블록으로 내려와서 Lock Byte에 대해 살펴보자 (그림 1-13 참조). 오라클은 레코드가 저장되는 로우마다 그 헤더에 Lock Byte를 할당해 해당 로우를 갱신 중인 트랜잭션의 ITL 슬롯 번호를 기록해 둔다. 이것이 로우 단위(row-level) Lock이며, 오라클은 로우 단위 Lock과 트랜잭션 Lock(=TX Lock)을 조합해서 로우 Lock을 구현했다. 레코드를 갱신하려고 할 때 대상 레코드의 Lock Byte가 활성화(turn-on)돼 있으면 ITL 슬롯을 찾아가고, 다시 그 ITL 슬롯이 가리키는 트랜잭션 테이블 슬롯을 찾아가 그 트랜잭션이 아직 active 상태면 트랜잭션이 완료될 때까지 대기(-> 트랜잭션 Lock)한다. 오라클 Lock 원리에 대해서는 2장에서 자세히 설명한다.
다른 DBMS는 Lock 매니저를 통해 현재 갱신 중인 레코드 정보를 관리하는데, Lock 매니저가 사용할 수 있는 리소스가 유한하기 때문에 대량의 갱신이 발생할 때는 로우 단위 Lock 정보를 모두 관리할 수 없어 블록 단위 또는 테이블 단위로 Lock 에스컬레이션(Escalation)이 발생하기도 하며, 그 순간 동시성이 현저히 저하된다. 하지만 오라클은 로우 단위 Lock을 별도의 Lock 리소스 사용 없이 레코드의 속성으로서 관리하기 때문에 Lock 에스컬레이션 메커니즘이 전혀 불필요하다.