<오라클 성능 고도화 원리와 해법1> Ch01-06 문장수준 읽기 일관성
오라클 성능 고도화 원리와 해법1 - Ch01 오라클 아키텍처 - 06 문장수준 읽기 일관성
단일 SQL 문이 수행되는 도중에, 또는 트랜잭션 내에서 일련의 SQL 문이 차례로 수행되는 도중에 다른 트랜잭션에 의해 데이터가 변경, 추가, 삭제된다면 일관성 없는 결과집합을 리턴하거나 값을 잘못 갱신하는 문제가 발생할 수 있다. 이런 현상을 방지하고 읽기 일관성(Read Consistency)을 보장하기 위해 DBMS마다 나름대로의 장치들을 마련하고 있는데, 트랜잭션 수준 읽기 일관성(Transaction-level Read Consistency)에 대해서는 다음 장에서 설명하기로 하고 여기서는 문장 수준 읽기 일관성(Statement-Level Read Consistency)에 대해서만 언급할 것이다.
(1) 문장수준 읽기 일관성이란?
문장수준 읽기 일관성은, 단일 SQL 문이 수행되는 도중에 다른 트랜잭션에 의해 데이터의 추가, 변경, 삭제가 발생하더라도 일관성 있는 결과집합을 리턴하는 것을 말한다.
예를 들어, 변경이 진행 중인 값, 즉 아직 커밋되지 않은 값을 다른 트랜잭션이 읽도록 Dirty Read를 허용한다면 읽기 일관성이 보장되지 않는다. 오라클을 제외한 다른 DBMS는 모두 로우 Lock을 사용해 Dirty Read를 방지한다. 즉, 읽기 작업에 대해 Shared Lock을 사용함으로써, Exclusive Lock이 걸린 로우를 읽지 못하도록 한다.
하지만 테이블 단위 Lock을 사용하지 않는 한, Dirty Read를 방지하는 것만으로는 문장수준 읽기 일관성이 완벽하게 보장되지 않는다.
만약 새 레코드가 맨 뒤쪽에 추가되면 잔고 총합계에 포함되겠지만 이미 읽고 지나간 위치에 삽입되면 총 합계에서 누락된다10). 레코드가 입력되는 위치에 따라 총합계가 달라진다면 읽기 일관성이 없는 것이다. 이런 현상을 방지하려면 2장에서 설명하는 트랜잭션 고립화 수준(Transaction Isolation Level)을 높이거나 테이블 Lock을 사용해야 한다. 오라클은 Shared Lock을 사용하지 않고 Undo 세그먼트에 저장해둔 Undo 데이터를 활용함으로써 그런 조치 없이도 완벽한 문장수준 읽기 일관성을 보장한다. 10) 그림에는 계좌번호가 1부터 10까지 차례로 입력된 것처럼 표시했지만, 순서를 유지하는 인덱스와 달리 테이블에는 어디로든 레코드 삽입이 이루어질 수 있다.
또 다른 예로서, TX1에서 잔고 총합을 구하는 쿼리가 진행 중일 때 다른 트랜잭션 TX2가 TX1에서 이미 읽고 지나간 레코드에서 잔고를 차감해 앞으로 읽을 레코드에 잔고를 더하거나 반대로, TX1이 앞으로 읽을 레코드에서 잔고를 차감해 이미 읽고 지나간 레코드에 잔고를 더한다면 잔고 총합계가 다르게 구해질 수 있다. 이런 현상을 방지하려면 트랜잭션 고립화 수준을 올리거나 테이블 Lock을 사용해야 한다. 하지만 오라클에서는 절대 이런 현상이 발생하지 않는다.
사례 1과 사례 2를 설명하는 중에 오라클의 읽기 일관성을 강조했는데, 다른 DBMS에서는 실제 위와 같은 현상이 발생할 수 있다는 뜻일까? 답은 “그렇다”이다.
말도 안 된다고 생각할지 모르겠지만, Sybase나 SQL Server에서 테스트해 보면 실제로 위와 같은 현상이 발생하는 것을 눈으로 확인할 수 있다. 테스트할 때, TX1 트랜잭션이 계좌 테이블을 너무 빨리 읽고 지나가면 안 되므로 그 전에 제3의 트랜잭션에서 2번 레코드에 Lock을 걸었다가 (TX1이 이 레코드를 읽으려는 순간 Shared Lock을 얻지 못해 대기하게 됨) TX2가 1번을 update를 실시한 직후에 롤백을 통해 Lock을 풀어주면 쉽게 재현할 수 있다.
| 테이블 레벨 Lock을 통한 읽기 일관성 확보 |
|---|
| 위와 같은 비일관성 읽기 문제를 해결하기 위한 일반적인 해법은 트랜잭션 고립화 수준(다음 장에서 설명함)을 상향 조정하는 것이다. SQL Server, Sybase 등은 Lock을 사용해 읽기 일관성을 구현하는데, 기본 트랜잭션 고립화 수준(Level 1, Read Committed)에서는 값을 읽는 순간에만 Shared Lock을 걸었다가 다음 레코드로 이동할 때 Lock을 해제한다. Shared Lock이 해제되기 때문에 이미 읽고 지나간 레코드를 다른 트랜잭션이 변경할 수 있게 되고, 이 때문에 문장 수준 읽기 일관성이 보장되지 않는 문제가 생긴다. 트랜잭션 고립화 수준을 레벨 2 (=Repeatable Read)로 조정하면 TX1 쿼리가 진행되는 동안 읽은 레코드는 Shared Lock이 계속 유지되며 심지어 쿼리가 끝나고 다음 쿼리가 진행되는 동안에도 Lock을 풀지 않는다. 커밋 또는 롤백을 통해 트랜잭션이 완료될 때 비로소 Lock이 해제되므로 더 높은 수준의 읽기 일관성이 보장된다. 하지만 트랜잭션 고립화 수준을 상향 조정하면 Lock이 발생하는 범위가 넓어지고 더 오래 유지되기 때문에 동시성 저하를 초래함은 물론이고 교착상태(Deadlock)가 발생할 가능성이 높아진다. |
오라클 데이터베이스를 사용하고 있다면 위와 같은 상황을 우려하지 않아도 된다. 오라클은 높은 수준의 동시성을 유지하면서도 완벽한 문장 수준 읽기 일관성을 보장하기 때문이다. 지금부터 오라클이 어떤 방식으로 문장 수준 읽기 일관성을 보장하는지 자세히 살펴보자.
(2) Consistent 모드 블록 읽기
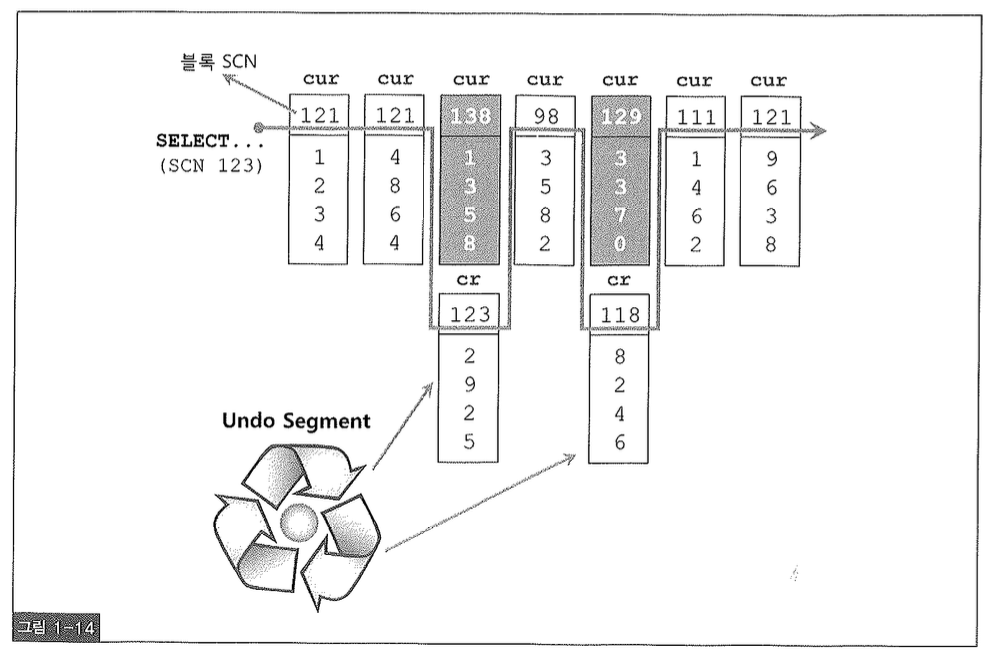
그림 1-14에 도식화한 것처럼, 오라클은 쿼리가 시작된 시점을 기준으로 데이터를 읽어들인다. 쿼리가 시작되기 전에 이미 커밋된 데이터만 읽고, 쿼리 시작 이후에 커밋된 변경사항은 읽어들이지 않는다. 변경이 발생한 블록을 읽을 때는 현재의 Current 블록으로부터 CR 블록을 생성해서 쿼리가 시작된 시점으로 되돌린 후 그것을 읽는다.
Current 블록은 디스크로부터 읽혀진 후 사용자의 갱신 사항이 반영된 최종 상태의 원본 블록을 말하며, CR 블록은 Current 블록에 대한 복사본이다. CR 블록은 여러 버전이 존재할 수 있지만 Current 블록은 오직 한 개뿐이다. 이처럼 Current 블록을 여러 개의 CR Copy 블록으로 복사해 읽기 일관성을 지원하는 오라클만의 독특한 메커니즘을 ‘다중 버전 읽기 일관성 모델(Multi-Version Read Consistency Mode)’이라고 한다.
| RAC 환경에서의 Current 블록 |
|---|
| 단일 인스턴스 환경이라면 캐싱된 Current 블록은 오직 한 개뿐이지만 RAC 환경이라면 Share 모드의 Current 블록이 여러 노드에 동시에 캐싱될 수 있다. 로컬 캐시 관점에서는 여전히 하나지만 글로벌 캐시 관점에서 보면 Current 블록이 여러 개인 셈이다. 하지만 Share 모드와 달리 Exclusive 모드의 Current 블록은 오직 한 노드에만 존재할 수 있다. 예를 들어, Share 모드의 Current 블록이 여러 노드에 공유된 상태에서 특정 노드가 Exclusive 모드로 업그레이드하면 나머지 노드에 캐싱된 Current 블록들은 전부 Null 모드로 다운그레이드된다. Null 모드로 다운그레이드된 블록을 읽을 때는 다른 노드 또는 디스크로부터 블록을 다시 읽어야 한다. |
쿼리가 시작된 시점을 기준으로 데이터를 읽는다고 했는데, 때로는 시작 시점이 아닌, 데이터를 찾아간 바로 그 시점의 최종값을 읽어야 할 때도 있다. 전자를 ‘Consistent 모드 읽기’, 후자를 ‘Current 모드 읽기’라고 하는데, 두 읽기 모드의 차이점에 대해서는 바로 다음 절에서 설명할 것이다.
그렇다면 Consistent 모드로 데이터를 읽을 때, 쿼리 시작 시점과 블록의 마지막 변경 시점을 어떻게 확인할까? 오라클은 SCN(System Commit Number)이라고 하는 시간 정보를 이용해 데이터베이스의 일관성 있는 상태를 식별하는데, 이는 시스템 전체적으로 공유되는 Global 변수라고 이해하면 쉽다. 이름이 의미하듯이 이 값은 기본적으로 사용자가 커밋할 때마다 1씩 증가한다. 또는 커밋이 없더라도 오라클 백그라운드 프로세스에 의해 조금씩 증가한다.
SCN은 읽기 일관성과 동시성 제어를 위해 사용되며, 생성된 Redo 로그 정보의 순서를 식별하는 데에도 사용되고, 마지막으로 데이터 복구를 위해서도 사용된다.
Consistent 모드 읽기를 이해하기 위해 알아야 할 또 다른 개념은 ‘블록 SCN’이다. 오라클은 블록이 마지막으로 변경된 시점 정보를 식별하기 위해 모든 블록 헤더에 SCN(System Change Number) 정보를 관리하는데, 이를 ‘블록 SCN’이라고 한다. 이는 앞서 설명했던, 블록 ITL 엔트리에 저장되는 트랜잭션별 커밋 SCN과는 별도로 관리된다.
(3) Consistent 모드 블록 읽기의 세부 원리
오라클에서 수행되는 모든 쿼리는 Global 변수인 SCN(System Commit Number) 값을 먼저 확인하고 나서 읽기 작업을 시작하는데, 이를 ‘쿼리 SCN’ 또는 ‘스냅샷 SCN’이라고 한다. 쿼리 SCN을 들고 다니면서 읽는 블록마다 블록 SCN과 비교해 읽을 수 있는 버전인지를 판단하는 것이다.
쿼리 SCN을 가지고 Consistent 모드로 읽을 때, 읽는 블록 상태에 따라 어떻게 일관성을 유지하면서 데이터를 읽는지 아래 3가지 경우로 나누어 살펴보자.
- “Current 블록 SCN <= 쿼리 SCN” 이고, committed 상태
- “Current 블록 SCN > 쿼리 SCN” 이고, committed 상태
- “Current 블록이 Active 상태, 즉 갱신이 진행 중인 것으로 표시” 돼 있을 때
A. “Current 블록 SCN <= 쿼리 SCN” 이고, committed 상태
Consistent 모드에서 데이터를 읽을 때는 블록 SCN(System Change Number)이 쿼리 SCN(System Commit Number)보다 작거나 같은 블록만 읽을 수 있다. 이때의 블록은 Current 블록을 의미하며, Current 블록은 오직 한 개뿐이다. 데이터 갱신은 항상 Current 블록에만 발생하므로, Current 블록의 SCN이 쿼리 SCN보다 작고 committed 상태라면 쿼리가 시작된 이후에 해당 블록에 변경이 가해지지 않았다는 것을 의미한다. 이때는 CR 블록을 생성하지 않고 Current 블록을 그대로 읽으면 된다.
B. “Current 블록 SCN > 쿼리 SCN” 이고, committed 상태
Current 블록이 committed 상태지만 블록 SCN이 쿼리 SCN보다 크다면 쿼리가 시작된 이후 해당 블록에 변경이 가해지고 커밋되었다는 것을 의미한다. 이때는 어떻게 일관성 있게 블록을 읽는지 그림 1-15를 보면서 이해해보자.
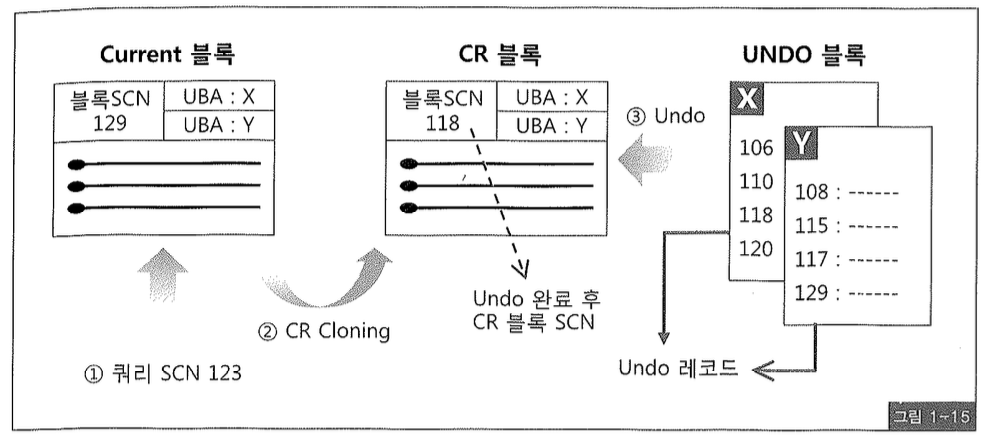
블록 원본에 해당하는 Current 블록의 SCN이 쿼리 SCN보다 크면, 블록 복사본인 CR 블록을 먼저 생성(CR Cloning)한다. 그림 1-15는 Current 블록 내용을 CR 블록에 그대로 복제하고(②) 이를 자신이 읽을 수 있는 과거 버전(쿼리 SCN보다 낮은 마지막 committed 시점)으로 되돌리는 과정(③)을 표현하고 있다. CR 블록을 과거 상태로 되돌릴 때 필요한 Undo 정보를 사용하며, ITL 슬롯에서 UBA(Undo Block Address)가 가리키는 Undo 블록을 찾아가 변경 이전 값을 읽는다.
Undo 레코드를 읽어 CR 블록을 한 단계 이전 상태로 되돌렸는데, 만약 거기에 커밋되지 않은 변경 사항이 포함되어 있거나 여전히 블록 SCN이 쿼리 SCN보다 높다면, 다시 ITL 슬롯에 있는 UBA가 가리키는 Undo 레코드를 찾아 블록을 이전 상태로 되돌리는 작업을 계속한다. 따라서 최종적으로 완성된 버전의 CR 블록은, 블록 SCN(그림 1-15에서 118)이 쿼리 SCN(그림 1-15에서 123)보다 작거나 같으면서 커밋되지 않은 내용은 전혀 포함하지 않은 상태가 된다.
IMU(In-Memory Undo) 기능이 작동하면 CR 롤백을 위해 Undo를 참조하지 않고 Shared Pool 내의 IMU Pool에 저장된 값을 이용(IMU CR rollbacks)하므로 update를 일정 횟수 반복하기 전까지는 consistent gets이 증가하지 않는다.
| IMU(In-Memory Undo) |
|---|
| 오라클 10g에 추가된 기능으로서 Hidden 파라미터 ‘inmemory_undo’와 ‘imupools’에 의해 제어된다. 이 파라미터가 TRUE면 오라클은 Undo 데이터를 Undo 세그먼트가 아닌 Shared Pool 내의 미리 할당된 IMU Pool에 생성한다. IMU는 작은 트랜잭션을 위해 고안된 기능이며, 이 기능을 통해 Undo 세그먼트 헤더 블록과 Undo 세그먼트 블록 버퍼에 대한 래치 경합 및 Pinning을 줄일 수 있다. |
만약 CR 블록을 과거 상태로 되돌리는 과정에서 필요한 Undo 정보가 덮어쓰여 계속 롤백을 진행할 수 없을 때 악명 높은 ‘Snapshot too old’ 에러가 발생한다. 또는 8절에서 설명할 ‘Delayed 블록 클린아웃(Cleanout)’ 과정에서 트랜잭션 테이블 슬롯이 이미 다른 트랜잭션에 의해 재사용되는 바람에 현재 읽고자 하는 클린아웃되지 않은 블록의 정확한 커밋 시점 정보를 확인할 수 없을 때도 ‘Snapshot too old’가 발생한다. ‘Snapshot too old’ 발생 원인과 해결책에 대해서는 9절에서 자세히 다룬다.
C. “Current 블록이 Active 상태, 즉 갱신이 진행 중인 것으로 표시되어 있을 때”
읽으려는 레코드에 Lock Byte가 설정되어 있고, ITL에 아직 커밋 정보가 기록되지 않았다면, 현재 갱신이 진행 중(Active 상태)인 것으로 인식할 수 있다. 하지만 오라클은 커밋 시 항상 곧바로 블록을 클린아웃(트랜잭션에 의해 설정된 로우 Lock을 해제하고 블록 헤더에 커밋 정보를 기록)하지는 않기 때문에 ITL 상태만 보고 갱신이 진행 중이라고 단정할 수 없다. 따라서 Active 상태의 블록일 때는 먼저 트랜잭션 테이블로부터 커밋 정보를 가져와 블록 클린아웃을 시도한다. 그 결과, 쿼리 SCN 이전에 이미 커밋된 블록으로 확인된다면 A 경우처럼 그 블록을 그대로 읽으면 된다. 쿼리 SCN 이후에 커밋된 블록으로 확인되거나, 커밋되지 않아 아직 클린아웃할 수 없다면 B 경우처럼 CR Copy를 만들어 쿼리 SCN보다 낮은 마지막 committed 상태로 되돌린 후 읽어야 한다.
| DBA에 의한 CR 개수 제한 |
|---|
| 자주 갱신되는 특정 테이블에 조회까지 많이 발생하면, 심한 경우 버퍼 캐시가 같은 블록에 대한 CR Copy로 가득 차는 일이 발생할 수 있다. 이를 방지하기 위해 오라클은 기본적으로 하나의 데이터 블록마다 6개까지만 CR Copy를 허용하며, 이를 제어하는 파라미터는 ‘_db_block_max_cr_dba’이다. 그리고 CR Copy는 LRU 리스트 상에서 항상 LRU end 쪽에 위치하기 때문에 Free 버퍼가 필요할 때 1순위로 밀려난다. |
이제 오라클만의 독특한 개념인 다중 버전 읽기 일관성 모델에 대해 어느 정도 이해했으리라 믿는다.