<오라클 성능 고도화 원리와 해법1> Ch03-03 SQL 트레이스
오라클 성능 고도화 원리와 해법1 - Ch03-03 SQL 트레이스
SQL을 튜닝할 때 가장 많이 사용되는 강력한 도구는 SQL 트레이스다. 앞서 살펴본 사전 실행 계획과 AutoTrace 결과만으로 부하 원인을 찾을 수 없을 때, SQL 트레이스를 통해 쉽게 찾아낼 수 있다. SQL 트레이스를 설정하는 여러 가지 방법이 있고, 각각 용도가 다르므로 잘 숙지하고 적시적지에 잘 활용하기 바란다.
(1) 자기 세션에 트레이스 걸기
아래는 현재 자신이 접속해 있는 세션에만 트레이스를 설정하는 방법이다.

위와 같이 트레이스를 설정하고 SQL을 수행한 후에는 user_dump_dest 파라미터로 지정된 서버 디렉토리 밑에 트레이스 파일(.trc)이 생성된다. 가장 최근에 생성되거나 수정된 파일을 찾아 분석하면 되는데, 파일 찾기에 어려움을 느끼는 분들은 아래 쿼리를 잘 활용하기 바란다. 스크립트로 저장해두었다가 실행하면 편하다.

TKProf 유틸리티
트레이스 파일을 직접 열어본 독자라면 알겠지만 이 파일을 그대로 분석하기는 쉽지 않다.
일반적인 상황에서는 몇 가지 분석 팩터에 따라 좀 더 보기 쉬운 형태로 포맷팅하는 것이 필요하다.

TKProf 유틸리티를 사용하면 트레이스 파일을 보기 쉽게 포맷팅해준다. 아래처럼 유닉스 쉘(Shell)이나 도스 프롬프트상에서 tkprof를 치면 사용법을 확인할 수 있다.
1
2
3
$ tkprof
Usage: tkprof tracefile outputfile [ explain= ] [ table= ] [ print= ] [ insert= ] [ sys= ] [ sort= ]
......
아래는 TKProf 유틸리티의 가장 일반적인 사용법이다. sys=no 옵션은 SQL을 파싱하는 과정에서 내부적으로 수행되는 SQL 문장을 제외시켜준다.
1
$ tkprof ora10g_ora_14370_oraking.trc report.prf sys=no
트레이스 결과 분석
지금까지 설명한 내용은 자주 반복하다 보면 누구나 쉽게 할 수 있지만, 이제부터의 분석 작업은 쉽지가 않다. 아마 제대로 분석할 만큼 숙련하려면 본서 1권은 물론 2권까지 모두 독파한 후에 가능한 일이다. 하지만 차근차근 따라오다 보면 뜻밖에 쉽고 재미있다고 느낄 것이므로 부담을 가질 필요는 없다.
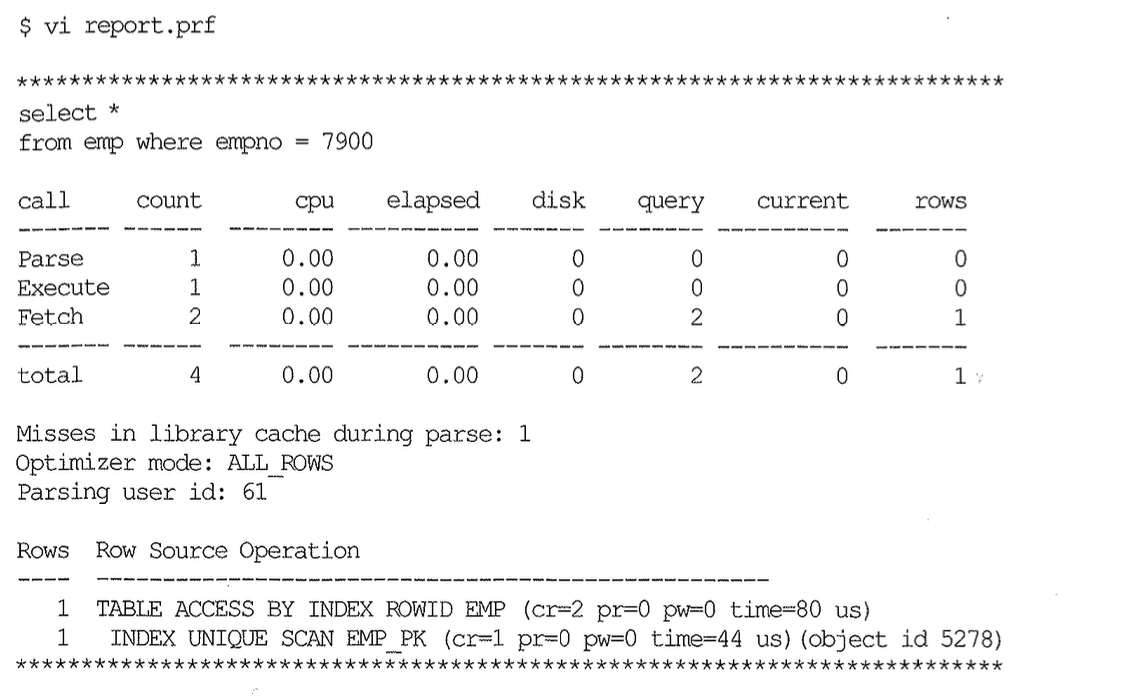
SQL 문 바로 밑에 있는 Call 통계(Statistics) 컬럼들 의미부터 간단히 살펴보자.


좀 더 자세한 설명은 각 장에서 자연스럽게 이루어질 것이며, 2절에서 보았던 AutoTrace 결과와 일치하는 항목과 비교해보면 다음과 같다.

Call 통계 아래쪽에 보이는 Row Source Operation에 대해서도 각 장에서 더욱 상세한 분석 방법이 설명될 것이며, 여기서는 각 항목의 의미만을 간단히 살펴보자.

왼쪽에 보이는 Rows는 각 수행 단계에서 출력된 로우 수를 의미한다. 오라클은 Flow-Out 방식으로 바뀌면서 생긴 단점을 보완하려고 9.2.0.2 버전부터 각 수행 단계별로 cr, pr, pw, time 등을 표시하기 시작했는데, 각각 Consistent 모드 블록 읽기, 디스크 블록 읽기, 디스크 블록 쓰기, 소요 시간(us=microsecond)을 의미한다.
그리고 꼭 기억해야 할 중요한 사실은, 부모는 자식 노드의 값을 누적한 값을 갖는다는 점이다. 예를 들어, 위에서 EMP 테이블 액세스 단계는 cr=2이고, 그 자식 노드인 EMP_PK 인덱스 액세스 단계는 cr=1이므로, 인덱스를 읽고 난 후 테이블을 액세스하는 단계에서 순수하게 일어난 cr 개수는 1이다.
이벤트 트레이스
오라클은 오래전부터 다양한 종류의 이벤트 트레이스를 제공해왔고, 이를 통해서도 SQL 트레이스를 걸 수 있는데 방법은 다음과 같다.
1
2
alter session set events '10046 trace name context forever, level 1';
alter session set events '10046 trace name context off';
특히, 이 방식을 사용하면 레벨 설정을 통해 바인드 변수와 대기 이벤트 발생 현황까지 수집할 수 있다. 설정할 수 있는 레벨 값은 1, 4, 8, 12이며, 레벨 1은 지금까지 살펴본 일반적인 SQL 트레이스와 같다.
레벨을 4 또는 12로 설정했을 때 트레이스 파일을 열어보면 아래처럼 바인드 변수에 대한 정보를 확인할 수 있다.

레벨을 8 또는 12로 설정하면, SQL 수행 도중 대기 이벤트가 발생할 때마다 트레이스 파일에 아래와 같은 정보들이 로그처럼 계속 기록된다.

그리고 이를 TKProf로 포맷팅하면 아래처럼 각 이벤트별로 집계된 정보를 볼 수 있다. 이벤트 분석을 통해 SQL이 빨리 수행되지 못하게 한 병목 요인을 쉽게 파악할 수 있다. 대기 이벤트가 무엇인지에 대해서는 1강에서 자세히 설명했다.

10046 트레이스를 걸 때 레벨을 4 이상으로 설정하면 트레이스 파일이 매우 급격하게 커지므로 주의가 필요하다. 계속 모니터링하다가 적정 시점에 정지시키는 것을 잊지 말아야 한다.
Elapsed time = CPU time + Wait time
위 대기 이벤트 정보는 쿼리 병목 원인을 찾아내는 데 결정적인 역할을 한다. 앞에서 Call 통계에서 CPU time과 Elapsed time을 간단히 설명했지만, DB 튜닝을 처음 시작하는 독자에게는 이 두 값의 의미가 혼란스러울 것이다. 대기 이벤트 개념을 이용해 그 의미를 좀 더 자세히 살펴보자.
오라클이 내부적으로 사용하는 측정 단위와 방법 때문에 생기는 오차가 있긴 하지만, Elapsed time은 CPU time과 Wait time의 합으로 정의할 수 있다.
- Elapsed time = CPU time + Wait time = Response 시점 - Call 시점
Elapsed time은 Call 단위로 측정이 이루어진다. 사용자(App 또는 WAS)로부터 데이터베이스 Call을 받은 순간부터 Response를 보내는 순간까지의 소요 시간을 말하며, Response 시점에서 Call 시점을 차감해서 구한다. 예를 들어, 13초에 Call을 보냈는데 25초에 Response를 받았다면 Call Elapsed time은 12초가 된다.
또 한 가지 알아야 할 것은, 애플리케이션 커서 캐싱25) 기법을 사용하지 않는 한 하나의 SELECT 문을 수행하는 동안 최소 3번의 Call이 발생하고, DML 문은 단 2번의 Call이 발생한다는 사실이다.
- SELECT 문 = Parse Call + Execute Call + Fetch Call(-> 1회 이상)
- DML 문 = Parse Call + Execute Call
특히, SELECT 문에서 다량의 데이터를 사용자에게 전송할 때는 Fetch Call이 ‘전송 레코드 건 수 / ArraySize’만큼 여러 번 발생한다. 따라서 하나의 SQL을 수행할 때의 Total Elapsed time은, 수행 시 발생하는 모든 Call의 Elapsed time을 더해서 구한다. 실제 예제를 통해 살펴보자.
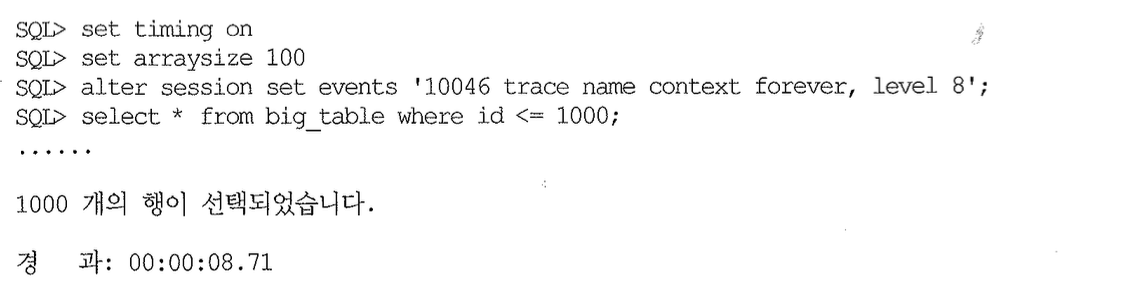
위에서 경과 시간을 보면 사용자가 느끼는 쿼리 총 소요 시간은 8.71초다. 하지만 아래 SQL 트레이스에서 Call 통계를 보면 DB 구간에서의 총 소요 시간은 0.07초에 불과하다.
1,000건을 읽는 데 Array Size를 100으로 설정했으므로 one-row fetch26)까지 합쳐 11번의 Fetch Call이 발생했고, Parse Call과 Execute Call까지 합쳐 총 13번의 Call이 발생했다. 따라서 13번 발생한 Call 각각에 대한 소요 시간을 더한 총 소요 시간이 0.07초다. 데이터베이스 내부적으로는 0.07초 동안만 일을 했고, 나머지 시간은 애플리케이션으로부터 추가 Call을 기다리면서 Idle 상태로 대기한 시간이다.
또한, CPU time과 Elapsed time 간 시간 차는, 0.07초 동안 일하는 동안에도 실제로 프로세스가 CPU를 점유하고 원활하게 일을 진행한 시간은 0.03초에 불과하다는 사실을 말해준다. 나머지 0.04초는 대기(Wait) 상태에 빠졌던 것으로 이해하면 된다. 지금까지 설명한 내용은 그림 3-1을 통해 쉽게 이해할 수 있다.
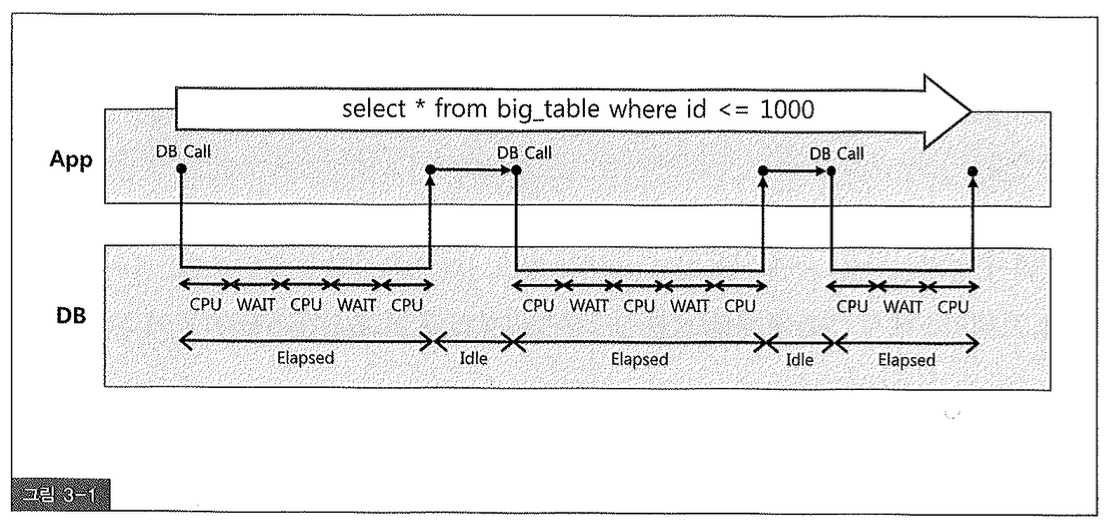
SQL 수행 전 이벤트 트레이스 레벨을 8로 설정했으므로 다음과 같이 이벤트 발생 현황까지 확인할 수 있다. 이를 통해 CPU time과 Elapsed time 간의 갭(GAP), 그리고 사용자가 느낀 총 소요 시간과의 갭이 발생했던 이유를 설명할 수 있다.

가장 눈에 띄는 것은 SQL*Net message from client 이벤트다. 이 대기 이벤트는 Idle 이벤트로서 오라클 서버 프로세스가 사용자에게 결과를 전송하고 다음 Fetch Call이 올 때까지 대기한 시간을 더한 값이다. 11번 발생하는 동안 8.43초를 대기했으므로 사용자가 느낀 총 소요 시간 8.71초의 대부분을 이 값이 차지한 것을 알 수 있다. 오라클 서버 입장에서는 할 일 없이 대기한 시간이고, App와 Network 구간에서 소모된 시간이다.
커넥션을 맺은 상태에서 쿼리와 쿼리 수행 사이 thinking time이 긴 애플리케이션이나, 서버로부터 데이터를 Fetch하고 클라이언트 내부적으로 많은 연산을 수행한 후에 다음 Fetch Call을 날리는 배치 프로그램에서 특히 이 값이 크게 나타난다. SQL*Net message to client도 Idle 이벤트에 속한다. 클라이언트에게 메시지를 보냈는데, 클라이언트가 너무 바쁘거나 네트워크 부하 때문에 메시지를 잘 받았다는 신호가 정해진 시간보다 늦게 도착하는 경우다.
위 리포트에서 오라클이 일하는 Elapsed time 동안 발생한 대기 이벤트로는 db file sequential read와 SQL*Net more data to client 두 개가 있다. db file sequential read는 Single Block Read 방식으로 디스크 블록을 읽을 때 발생하는 대기 이벤트다.
SQL*Net more data to client는 클라이언트에게 전송할 데이터가 남았는데 네트워크 부하 때문에 바로 전송하지 못할 때 발생하는 대기 이벤트다. 5장에서 설명하겠지만, 오라클 서버는 내부적으로 SDU(Session Data Unit) 단위로 패킷을 나누어 전송한다. 하나의 SDU 단위 패킷을 전송했는데 잘 받았다는 신호가 정해진 시간보다 늦게 도착하면 대기가 발생하는데, 그 때 발생하는 대기 이벤트가 SQL*Net more data to client이다.
Elapsed time은 Response 시점에서 Call 시점을 차감해서 구한다고 했다. 반면, CPU time과 Wait time은 각 발생 구간의 시간을 더해서 구하며, 내부 타이머의 측정 단위 때문에 반올림된 수치를 사용한다. 따라서 이론적으로는 Elapsed time이 CPU time과 Wait time을 더한 값이지만 둘 간에는 항상 오차가 발생한다. 심지어 CPU time이 Elapsed time을 초과하기도 한다.
지금까지 Call 통계에서의 CPU time과 Elapsed time이 어떻게 다른지, 그리고 10046 이벤트 트레이스 레벨을 8로 설정했을 때 나오는 이벤트 발생 현황에 대한 분석 방법을 비교적 자세히 설명하였다.
10046 이벤트 트레이스 다음으로 자주 사용하게 되는 것이 10053 트레이스다. 이는 실행 계획을 생성하는 CBO의 의사 결정 과정을 추적하는 것을 가능케 하며, 이를 통해 옵티마이저가 이상한 돌출 행동을 보이는 원인을 찾아낼 수 있는 경우가 종종 있다.
(2) 다른 세션에 트레이스 걸기
성능 문제가 발생한 튜닝 대상 SQL 목록을 이미 확보했다면 앞에서처럼 자신의 세션에 트레이스를 걸어 문제 SQL의 트레이스 정보를 수집하여 분석을 진행하면 된다. 하지만 아직 튜닝 대상 SQL이 수집되지 않은 상황이라면, 커넥션 Pool에 놓인 세션 또는 시스템 레벨로 트레이스를 걸어 SQL 수행 정보를 수집해야 한다. 또는 특정 세션에서 심한 성능 부하를 일으키고 있다면 이미 수행 중인 그 세션에 트레이스를 걸어야 하는데, 그럴 때 사용할 수 있는 방법들이 제공되며 버전에 따라 다르다.
(3) Service, Module, Action 단위로 트레이스 걸기
최근 개발된 n-Tier 구조의 애플리케이션은 WAS에서 DB와 미리 맺어놓은 커넥션 Pool에서 세션을 할당받기 때문에 특정 프로그램 모듈이 어떤 세션에서 실행될지 알 수 없고, 한 모듈 내에서 여러 SQL을 수행할 때 각각 다른 세션을 통해 처리될 수도 있다. 이런 환경에서 성능 문제가 발생한 특정 모듈이나 SQL에 대해서만 트레이스를 거는 것은 매우 어려운 작업이다. WAS에서 맺은 세션에만 트레이스를 건 후에 트레이스 파일을 모두 뒤져 해당 모듈에서 수행한 SQL을 찾아내야 하므로 번거롭고 시간도 많이 소요된다. 게다가 커넥션 Pool에 유지되는 세션 개수는 동적으로 늘었다 줄었다 하는데 트레이스를 설정한 후에 새로 맺어진 세션에 대해서는 속수무책이다. 하는 수 없이 DB 트리거를 이용해 로그온 시점에 트레이스가 걸리도록 하거나 시스템 레벨로 전체 트레이스를 걸어야만 한다.
하지만 10g부터 service, module, action별로 트레이스를 설정하고 해제할 수 있는 dbms_monitor 패키지가 소개되면서 위와 같은 불편함이 모두 사라졌다.
지금까지 설명한 기능을 효과적으로 사용하려면 모든 프로그램 모듈 수행 전에 dbms_application_info.set_module 프로시저를 한 번씩 호출하도록 프로그램을 변경해야 한다. 데이터베이스 Call이 한 번씩 더 발생하기는 하지만 I/O 작업이 전혀 없고 세션 Global 변수값만 살짝 바꿔주기 때문에 부하가 거의 없다고 할 수 있다. SQL 단위로 set_action을 자주 수행하는 것은 시스템에 다소 부하를 줄 수 있으므로 SQL 수행이 빈번한 OLTP 성 프로그램보다는 배치 프로그램에만 적용하는 게 좋겠다.
그리고 set_module 호출하는 부분을 개발자가 모듈마다 일일이 삽입하려면 귀찮을 뿐만 아니라 빠뜨리기 쉬우므로 WAS에서 커넥션을 얻을 때마다 호출되는 공통 모듈 내에 추가시켜주는 것이 좋다. 필요할 때만 이 프로시저가 호출되도록 옵션을 제공할 수도 있다.
필자는 이미 몇몇 개발 프로젝트에 이 방법을 적용해 세션 모니터링과 튜닝 작업을 효과적으로 진행한 경험이 있다. 독자가 속한 프로젝트에도 반드시 적용할 것을 권고한다.
dbms_monitor 패키지를 이용해 row source operation과 대기 이벤트 발생 현황만 수집할 수 있는 게 아니라 service, module, action 단위로 v$sesstat 통계 정보를 수집하는 기능도 제공된다. dbms_monitor의 serv_mod_act_stat_enable과 serv_mod_act_stat_disable 프로시저를 이용하면 되고, 어떤 단위로 정보 수집이 진행 중인지 확인하려면 dba_enabled_aggregations 뷰를 이용한다. service, module, action별로 수집된 수행 통계를 확인하려면 v$serv_mod_act_stats 뷰를 이용하면 된다. 활용 방법은 트레이스를 걸 때와 모두 동일하므로 따로 설명하지는 않겠다.
참고로, v$session에서 client_identifier 별로 수행 통계를 수집할 때는 client_id_stat_enable과 client_id_stat_disable 프로시저를 이용하고, 수집된 수행통계를 확인하려면 v$client_stats 뷰를 이용하면 된다.
이렇게 세션 레벨, 서비스/모듈/액션 단위로 트레이스를 설정하고 해제하는 방법을 활용하면, 애플리케이션의 성능 모니터링과 튜닝 작업을 보다 효율적으로 수행할 수 있다. 이는 특히 대규모 시스템이나 복잡한 n-Tier 애플리케이션 환경에서 매우 유용하다.