<오라클 성능 고도화 원리와 해법1> Ch04-06 바인드 변수의 부작용과 해법
오라클 성능 고도화 원리와 해법1 - Ch04-06 바인드 변수의 부작용과 해법
바인드 변수 사용과 관련해 꼭 알아야 할 중요한 사실이 있다. 앞선 그림 4-5에서 본 SQL 수행 절차를 다시 상기해보자.

바인드 변수를 사용하면 처음 수행할 때 최적화를 거친 실행 계획을 캐시에 저장하고, 실행 시점에는 그것을 그대로 가져와 값을 다르게 바인딩하면서 반복 재사용하게 된다. 여기서 중요한 점은 변수를 바인딩하는 시점이 (최적화 시점보다 나중인) 실행 시점이라는 것이다. 즉, SQL을 최적화하는 시점에 조건절 컬럼의 데이터 분포도를 활용하지 못하는 문제점을 갖는다. (바인드 변수를 사용하면 통계 정보를 사용하지 못한다고 흔히 말하지만, 정확히는 컬럼 히스토그램 정보를 사용하지 못한다는 것이다. 히스토그램을 제외한 다른 통계 정보들은 충분히 활용한다.)
따라서 바인드 변수를 사용할 때 옵티마이저는 평균 분포를 가정한 실행 계획을 생성한다. 컬럼 분포가 균일할 때는 문제될 것이 없지만 그렇지 않을 때는 실행 시점에 바인딩되는 값에 따라 최적이 아닌 실행 계획이 될 수 있어 문제다.
특히, 등치(=) 조건이 아닌 부등호나 Between 같은 범위 기반 검색 조건일 때는 고정된 규칙을 사용하기 때문에 더 부정확한 예측에 기반한 실행 계획이 만들어진다. 좀 더 구체적으로 말해, 아래 1~4번은 선택도(Seletivity)를 5%로 계산하고, 5~8번까지는 0.25%로 계산한다.

2권에서 설명하겠지만 비용 계산에 기초가 되는 카디널리티(Cardinality, 특정 액세스 단계를 거치고나서 출력될 것으로 예상되는 결과 건수)는 전체 레코드 수에 선택도를 곱해서 구한다.
카디널리티(Cardinality) = 선택도(Selectivity) X 전체 레코드 수
따라서 테이블에 1,000개 로우가 있을 때 옵티마이저는 1~4번과 같은 조건절에 대해서는 50개 로우이 출력될 것으로 예상하고, 5~8번과 같은 조건절에 대해서는 3개 로우가 출력될 것으로 예상한다. 아래 테스트 결과에서 이런 사실을 쉽게 확인할 수 있다.

바인드 변수를 사용했을 때 옵티마이저는 각각 50개와 3개의 카디널리티(rows)를 예상하였다. 사용자가 실제 입력한 값에 따라 전혀 결과가 달라질 수 있지만 옵티마이저로서는 어쩔 수 없는 선택을 한 것이다.
반면, 아래처럼 상수 조건식(no <= 100, no between 500 and 600)을 사용했을 때는 거의 정확한 카디널리티를 계산해 낸다.

이처럼 바인드 변수를 사용할 때는 정확한 컬럼 히스토그램에 근거하지 않고 카디널리티를 구하는 정해진 계산식에 기초해 비용을 계산하므로 최적이 아닌 실행 계획을 수립할 가능성이 높다.
바인드 변수를 사용하면 컬럼 히스토그램을 제대로 활용하지 못할 뿐만 아니라 파티션 테이블을 쿼리할 때 파티션 레벨 통계 정보를 이용하지 못하는 것도 바인드 변수의 대표적인 부작용 중 하나다. 파티션 레벨 통계보다 다소 부정확한 테이블 레벨 통계를 이용함으로써 옵티마이저가 가끔 악성 실행 계획을 수립한다.
(1) 바인드 변수 Peeking
바인드 변수의 부작용을 극복하기 위해 오라클은 9i부터 바인드 변수 Peeking 기능을 도입했다. ‘Peeking’이라는 단어가 의미하듯, 이 기능은 SQL이 첫 번째 실행될 때 하드 파싱될 때 함께 딸려 온 바인드 변수 값을 살짝 훔쳐보고, 그 값에 대한 컬럼 분포를 이용해 실행 계획을 결정하는 것이다. 다른 DBMS에서도 같은 기능을 제공하는데, 예를 들어 SQL Server에서는 ‘Parameter Sniffing’이라고 부른다38).
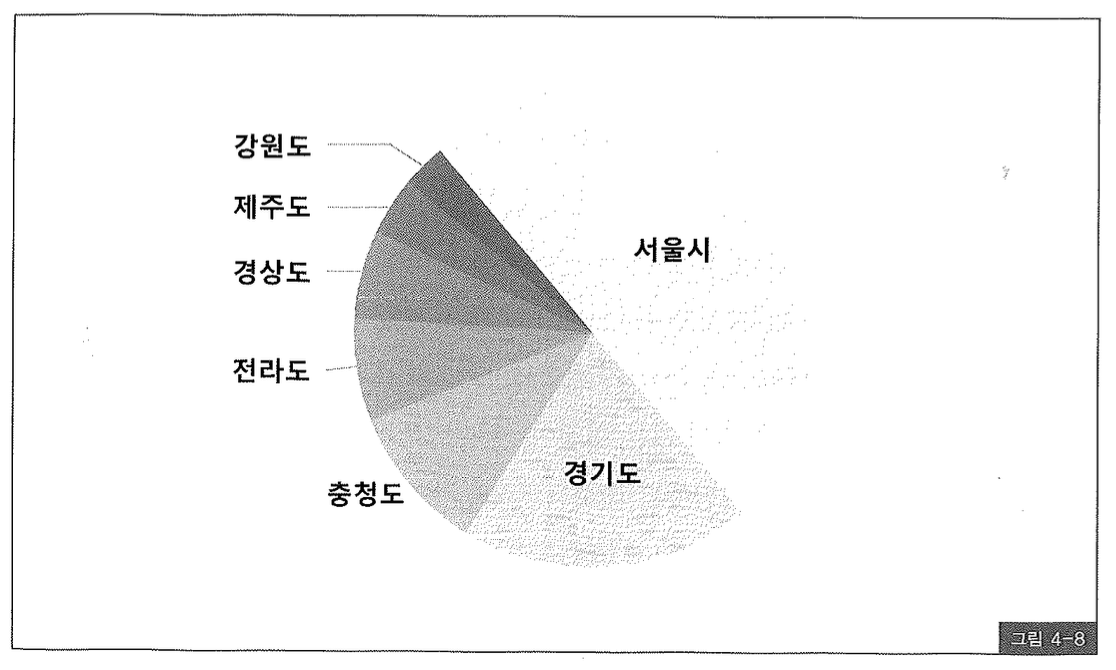
그런데 이것은 매우 위험한 기능이 아닐 수 없다. 어제까지 잘 돌던 프로그램이 어느 날 갑자기 느려지는 현상이 발생할 수 있기 때문이다. 예를 들어, 아파트 매물 분포가 그림 4-8과 같다고 하자.
아직 인덱스 원리에 대해 설명하지 않았지만, 서울시와 경기도처럼 선택도(Selectivity)39)가 높은 데이터를 인덱스를 경유해 액세스할 때면 성능이 오히려 더 느려진다는 사실만큼은 잘 알고 있을 것이다.
SELECT * FROM 아파트 매물 WHERE 도시 = :CITY;
아파트 매물을 검색하는 위 쿼리가 처음 수행되는 시점에 사용자가 ‘서울시’ 또는 ‘경기도’를 입력했다면, 옵티마이저는 아마 테이블을 Full Scan 하는 실행 계획을 수립할 것이다. 그러면 이 실행 계획이 캐시에서 밀려나기 전까지는 ‘제주도’가 입력되든 ‘강원도’가 입력되든 항상 테이블을 Full Scan 하게 된다. (참고로, Bind 변수 Peeking에 사용된 값보다 아주 긴 값이 입력되면 실행 계획을 다시 수립하는 기회를 얻게 된다. 하지만 이 사례에서는 해당 사항이 없는 것 같다. 4절 ‘커서 공유’ 중 ‘(3) 커서를 공유하지 못하는 경우’를 참조하기 바란다.)
그 다음날 쿼리가 처음 수행될 때는 사용자가 우연히 ‘제주도’를 입력했다. 그러면 Index Range Scan을 통해 테이블을 액세스하는 실행계획을 수립하게 되고, 그 이후에는 계속해서 같은 방식으로 수행된다. 서울시와 경기도 매물이 많다면 검색이 이루어지는 비중도 그럴 텐데, 실행 계획이 캐시에서 밀려나기 전까지 이 애플리케이션에서 서울시와 경기도 매물을 검색하는 사용자는 예전보다 느려진 성능 때문에 짜증을 느끼게 된다.
그리고 이 쿼리의 수행 빈도가 낮아 캐시에서 자주 밀려난다면 하루 중에도 실행 계획이 수시로 바뀔 수 있으니 이 또한 문제가 아닐 수 없다.
그런데 10g부터 dbms_stats의 기본 설정이 히스토그램을 생성할지 여부를 오라클이 판단하는 쪽으로 바뀌었다. 이전에는 히스토그램을 전혀 생성하지 않거나 몇몇 개만 생성했던 것이 10g부터는 더 많은 컬럼에 히스토그램이 생성됨으로 말미암아 바인드 변수 Peeking에 의한 폐해가 더 도드라져 보이게 되었다.
잘못 수립된 실행 계획 때문에 느린 애플리케이션도 문제지만 시스템 운영자 입장에서는 자주 실행 계획이 바뀌어 어제와 오늘의 수행 속도가 급격히 달라지는 현상을 더 민감하게 받아들일 수밖에 없다. 차라리 항상 느린 애플리케이션이라면 튜닝을 통해 해결할 수 있어 더 낫다.
또한, 바인드 변수 Peeking 기능이 활성화되었어도 Explain Plan 명령을 통해 확인하는 사전 실행 계획은 이 기능이 적용되지 않은 실행 계획임을 주의할 필요가 있다. Explain Plan 명령을 통해 실행 계획을 확인할 때는 바인드 값을 제공하지 않으므로 옵티마이저는 바인드 값을 Peeking할 수 없다. 당연히 이때의 실행 계획은 평균 분포를 가정한 실행 계획일 테고, 그 실행 계획을 확인하고 배포한 SQL이 실제 실행 시점에는 바인드 변수 Peeking을 일으켜 다른 방식으로 수행될 수 있다.
이런저런 연유로, 바인드 변수 Peeking 기능을 개발한 오라클 개발팀 입장에서는 안타까운 일이지만 현재 대부분 운영 시스템에서는 아래처럼 이 기능을 비활성화시킨 상태에서 운영 중이다.
alter system set "_optim_peek_user_binds"=FALSE;
(3) 입력 값에 따라 SQL 분리
바인드 변수가 시스템 성능과 확장성을 위해 워낙 중요하기 때문에 어떤 식으로든 그 부작용을 없애려는 DBMS 차원의 노력은 계속 이어질 것이다. DBMS 벤더가 부작용 없이 문제를 완전히 해소할 때까지는 개발자 입장에서의 노력이 필요하고, 이처럼 어려운 문제들을 해결하는 것이 개발하는 사람의 본분이고 보람이다.
인덱스 액세스 경로(Access Path)로서 중요하고 조건절 컬럼의 데이터 분포가 균일하지 않은 상황에서 바인드 변수 사용에 따른 부작용을 피하려면 바인딩되는 값에 따라 실행 계획을 아래와 같이 분리하는 방안을 고려해야 한다.

여기서도 주의할 사항이 한 가지 있는데, OLTP 시스템에서 union all을 이용해 SQL을 지나치게 길게 작성하면 오히려 라이브러리 캐시 효율을 떨어뜨리게 된다는 사실이다. 예를 들어, union all을 사용해 10개의 SQL을 결합(Concatenate)했다고 가정하자. 그러면 하드 파싱 시점에 옵티마이저는 10개 SQL을 최적화해야 한다. 그리고 그만큼 Shared Pool에서 많은 공간을 차지하게 된다. 10개가 항상 골고루 사용된다면 모르지만 그중 한두 개만 주로 사용된다면 나머지는 불필요하게 공간만 낭비하는 결과를 초래한다. 더욱이 매번 수행할 때마다 긴 텍스트를 파싱하면서 Syntax를 체크하고 파싱 트리를 만들어 Semantic 체크하는 과정을 반복한다고 생각해보라. Parse 단계에서 CPU를 과도하게 소비할 것임은 불보듯 뻔하다.
이처럼 union all을 이용해 SQL을 길게 작성하면, 라이브러리 캐시 효율을 떨어뜨리고 Parse 단계의 CPU 사용률을 높일 뿐 아니라 Execute 단계에서도 CPU 사용률을 높이는 결과를 초래한다. 실행 계획 분기 조건에 의해 제외되는 부분은 실행되지 않는다고 생각하겠지만 I/O를 일으키지 않을 뿐 실제 실행은 일어나기 때문이다.
이처럼 union all을 사용해 SQL을 길게 작성하는 패턴을 많이 사용하면 시스템 전반의 CPU 사용률을 높이고 라이브러리 캐시 부하를 가중시킨다. 어디 그뿐인가? 네트워크를 통한 메시지 전송량도 증가하므로 좋을 게 없다.
따라서 배치 프로그램이나 DSS 시스템이라면 상관없겠지만 OLTP 시스템이라면 union all을 이용하는 것보다 아래처럼 애플리케이션 단에서 조건에 따라 SQL을 분기하는 것이 바람직하다.
(4) 예외적으로, Literal 상수값 사용
입력 값에 따라 SQL을 분리하는 방법이 모든 경우에 적용될 수 있는 해법은 아니다. 값의 종류가 의외로 많을 수 있고, 값의 종류가 늘거나 줄 때 소스를 일일이 변경해줘야 하는 관리상 부담도 존재한다.
우리가 그런 기법들을 동원해야만 하는 근본 원리와 취지를 다시 생각해보면, 조건절 컬럼의 값 종류(Distinct Value)가 소수일 때는 바인드 변수보다 오히려 Literal 상수를 사용하는 게 나은 선택일 수 있다. 왜냐하면, 입력 값 종류가 몇 개에 불과하다면 하드 파싱 부하가 미미할 테고, Literal 상수를 사용함으로써 옵티마이저가 더 나은 선택을 할 가능성이 커지기 때문이다.
부등호나 Between 같은 범위 검색 조건일 때도 Literal 상수를 사용하는 것이 최적화 측면에서 유리함을 앞서 설명하였다. 특히 배치 프로그램이나 DW, OLAP 등 정보계 시스템에서는 일자 조건이 빠지지 않고, 거의 대부분 범위 검색 조건이므로 Literal 상수 값을 사용할 때 더 나은 실행 계획이 수립된다.
게다가 배치 프로그램이나 정보계 시스템에서 수행되는 SQL은 대부분 Long Running 쿼리이므로 파싱 소요 시간이 쿼리 총 소요 시간에서 차지하는 비중이 매우 낮고, 사용 빈도도 낮아 하드 파싱에 의한 라이브러리 캐시 부하를 크게 염려할 필요가 없다.
OLTP 성 애플리케이션이더라도 사용 빈도가 아주 낮아 하드 파싱에 의한 라이브러리 캐시 부하를 유발할 가능성이 없다면, 예외적으로 Literal 상수값을 사용하는 것도 고려해 볼 수 있다. 예외적으로 적용해야지, 단순히 바인드 변수 정의하는 게 귀찮다고 그렇게 해서는 안 된다. 다시 강조하지만, OLTP 환경이라면 특별한 몇몇 경우를 제외하고는 반드시 바인드 변수를 사용해야만 한다.