<오라클 성능 고도화 원리와 해법1> Ch04-11 Static SQL 구현을 위한 기법들
오라클 성능 고도화 원리와 해법1 - Ch04-11 Static SQL 구현을 위한 기법들
Dynamic SQL을 자주 사용하게 되는 첫 번째 이유를 앞에서 살펴보았다. 개발팀에 문의했을 때 두 번째로 많이 나온 사례는 조건에 IN-List 항목이 가변적으로 변할 때였다. 이를 포함해 Dynamic SQL을 Static SQL로 바꾸는 기법을 몇 가지 소개하려고 한다.
미리 언급하면, 여기서 소개하는 사례들은 Dynamic SQL로 작성하더라도 생성될 수 있는 최대 SQL 개수가 그다지 많지 않기 때문에 라이브러리 캐시에 그렇게 많은 부하를 주지는 않는다. 앞에서 보았던, 사용자가 선택적으로 입력한 검색 조건에 따라 SQL이 다양하게 바뀌는 사례도 마찬가지였다.
문제는, 이런 저런 이유로 Dynamic SQL을 사용하는 순간 조건절 비교값까지 습관적으로 Literal 상수값을 사용하도록 개발한다는 데에 있다. 그런 뜻에서, 꼭 필요한 경우가 아니라면 가급적 Static SQL로 작성하는 습관과 능력을 길러줄 수 있도록 몇 가지 사례를 독자와 공유하려는 것이다. 누구나 쉽게 생각해낼 수 있는 단순한 방법들이지만 이런 사례들을 접함으로써 SQL을 Static하게 구현하는 것이 결코 어려운 일이 아님을 전달하고자 한다.** **
(1) IN-List 항목이 가변적이지만 최대 경우수가 적은 경우

LP회원을 선택하는 그림 4-15 팝업창에서 사용자가 선택한 LP회원 목록을 선택하고 자할 때, Static 방식으로 SQL을 작성하려면 아래 7개 SQL을 미리 작성해두어야 한다.

선택 가능한 회원수가 4개로 늘어나면 15개, 5개면 31개의 SQL이 필요하다. SOL을 미리 작성해두고 경우에 따라 그 중 하나를 선택하도록 프로그래밍하는 것은 귀찮은 일이므로 Dynamic SQL을 사용하는 손쉬운 방법을 선택하게 된다.
하지만 이를 Static SQL로 구현하기 위한 해법은 허무하게도 아래와 같이 간단하다.
1
select * from LP회원 where 회원번호 in ( :a, :b, :c )
사용자가 입력하지 않은 항목에 Null 값을 입력하면 자동으로 결과 집합에서 제외된다. 그런데도 IN-List를 동적으로 생성하도록 Dynamic SQL을 사용하는 경우를 종종 보게 되므로 여기서 언급하는 것이다.
상황에 따라 아래처럼 decode 문을 사용해야할 때도 있다. 그림 4-15에서 4개의 체크 박스에 각각 내부적으로 ‘all’, ‘01’, ‘02’, ‘03’ 값이 부여돼 있다고 가정하고 작성한 것이다.

(2) IN-List 항목이 가변적이고 최대 경우 수가 아주 많은 경우

그림 4-16을 보면, IN-List 항목이 가변적이고 최대 개수도 고정적인 것은 앞 사례와 동일하다. 하지만 가능한 경우수가 너무 많아 Static SOL로 일일이 작성해두는 것은 불가능해보인다. 그렇다고 바인드 변수를 사용하는 것도 쉬운 일은 아니다. 실행시 바인드 변수에 값을 입력하는 코딩을 그만큼 많이 해야하기 때문이다. 그림 4-16은 화면에 보이는 부분만 표시했는데도 항목 개수가 이미 60여개에 이른다. 좀 더 쉽게 구현하는 방법이 없을까?
문제를 풀려면 발상의 전환이 필요하다. SQL 조건절에는 대개 좌변에 컬럼을 두고 우변에는 그것과 비교할 상수 또는 변수를 위치시킨다. 하지만 여기서는 생각을 바꿔 컬럼과 변수 위치를 서로 바꿔보자.
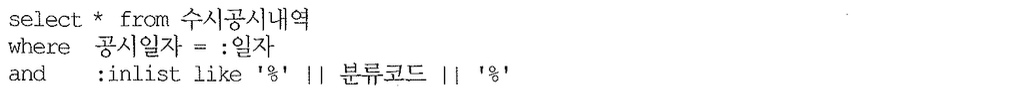
조건을 위와 같이 작성하고 사용자가 선택한 분류코드를 ‘,(comma)’ 등 구분자로 연결해 아래처럼 String 형 변수에 담아서 바인딩하고 실행시키면 된다.
:inlist := '01,03,08,14,17,24,33,46,48,53
의외로 문제가 쉽게 풀린 느낌이다. 참고로, 문자열을 처리하는 오라클 내부 알고리즘 상 like 연산자보다 instr 함수를 사용하면 더 빠르므로 아래와 같이 작성할 것을 권고한다.

인덱스 원리에 익숙한 독자라면 like, instr 둘 다 컬럼을 가공한 형태이므로 분류코드를 인덱스 액세스 조건으로 사용 못해 성능상 문제가 될 수 있음을 직감했을 것이다. 이는 인덱스 구성에 따라 얘기가 달라진다.

인덱스 구성이 [분류코드+공시일자]일 때는 당연히 1번이 유리하다. 2번 SOL, 문은 이 인덱스를 사용하지 못하거나 Index Full Scan 해야만 한다.
하지만 인덱스 구성이 [공시일자+분류코드]일 때는 상황에 따라 다르다. 사용자가 선택한 항목 개수가 소수일 때는 1번이 유리하지만 다수일 때는 인덱스를 그만큼 여러 번 탐침해야 하므로 2번이 유리할 수도 있다. 2번 SQL의 유·불리는 인덱스 깊이(루트에서 리프 블록에 도달하기까지 거치는 블록 수)와 데이터 분포에 따라 결정될 것이다. 하루치 데이터가 수십만 건 이상 되는 경우가 아니라면 대개는 2번 처럼 분류 코드가 인덱스 필터 조건으로 사용되는 것만으로도 과도한 테이블 랜덤 액세스를 제거할 수 있어 만족할 만한 성능을 얻을 수 있다.
(3) 체크 조건 적용이 가변적인 경우

주식 종목에 대한 회원사(=증권사) 별 거래 실적을 집계하는 쿼리다. 굵게 표시한 Exists 서브쿼리는 코스피(KOSPI)에 편입된 종목만을 대상으로 거래 실적을 집계하고자 할 때 만 동적 으로 추가된다.
사실 이 케이스는 라이브러리 캐시 최적화와는 그다지 상관이 없다. 나올 수 있는 경우의 수가 두 개뿐이기 때문이다. 그럼에도 Static SQL로 구현해보려는 노력 속에 SQL을 아래와 같이 작성한 경우를 보았다. 문제는, 아이디어는 괜찮은데 성능이 오히려 이전보 다 나빠진다는 데에 있다.

사용자가 코스피 종목 편입 여부와 상관없이 전종목을 대상으로 집계하려고 할 때는 서브쿼리를 수행할 필요가 없다. 그럼에도 위와 같이 무리하게 SQL을 통합함으로써 항상 서브쿼리를 수행해야만 하는 비효율을 안게된 것이다.
Static SQL 구현 능력을 향상시키는 차원에서 굳이 하나의 SOL로 통합하고 싶다면, 아래와 같이 함으로써 두 마리 토끼를 다 잡을 수 있다. 즉, I/O 효율과 라이브러리 캐시 효율을 모두 달성 가능하다.

Exists 서브쿼리는 존재 여부만 체크하는 것이므로 로그 안에 union all을 사용하면 조인 에 성공하는 첫 번째 레코드를 만나는 순간 더는 진행하지 않고 true를 리턴한다.
(4) select-list가 동적으로 바뀌는 경우
사용자 선택에 따라 화면에 출력해야 할 항목이 달라지는 경우가 종종 있다. 그림 4-17 은, 그런 요건 때문에 SQL을 동적으로 구성할 수 밖에 없었다면서 어떤 개발팀에서 가져 온 사례다.
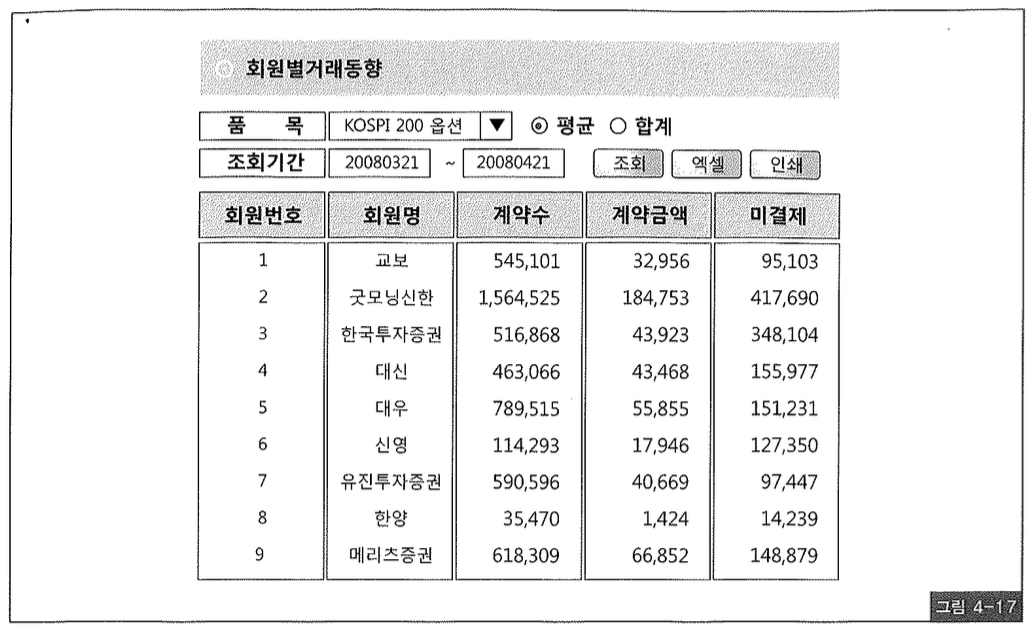

이를 Static SQL로 바꾸는 것은 너무 쉽다. decode 함수 또는 case 구문을 활용하면 된다.

아래는 또 다른 개발팀에서 가져온 사례인데, 위의 것과 동일하다.

아래처럼 Static SQL로 바꾸면 된다.

주의할 것은, 결과가 같더라도 아래와 같이 작성하면 decode 함수를 집계 대상 건수 만큼 반복 수행하게 되므로 성능이 더 나빠질 수 있다는 사실이다.

(5) 연산자가 바뀌는 경우
조건절에 사용되는 입력항목이나 출력항목이 바뀌는 게 아니라 그림 4-18처럼 비교 연산자가 그때그때 달라지는 경우는 어떻게 Static SQL로 구현할 수 있을까?
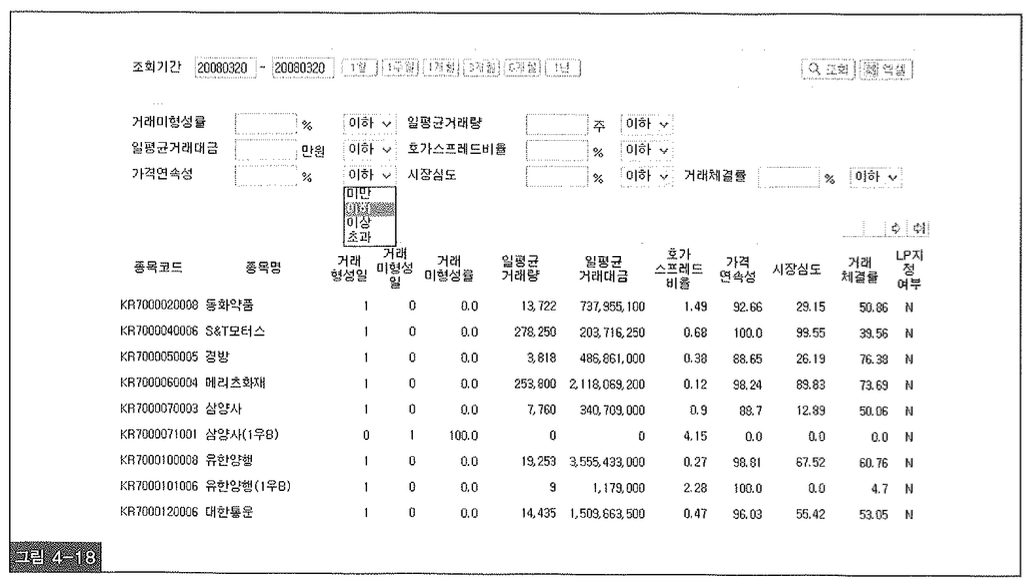
미만, 이하, 이상, 초과 중 사용자가 선택하는 항목이 무엇이냐에 따라 <, <=, >, >= 4가지 중 하나의 연산자로 바꿔야 하므로 Dynamic SQL이 불가피하다고 생각할 수 있다. 하지만 누구나 조금만 고민해보면 쉽게 해법을 찾을 수 있다. 아래처럼 SQL을 작성하고 바인딩하는 값을 바꾸면 된다.

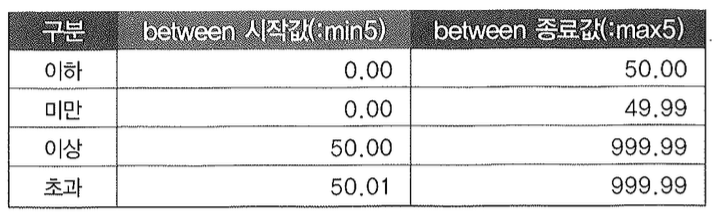
각 컬럼은 아래와 같은 도메인에 따라 표준화된 데이터 타입과 자릿수를 할당받는다.
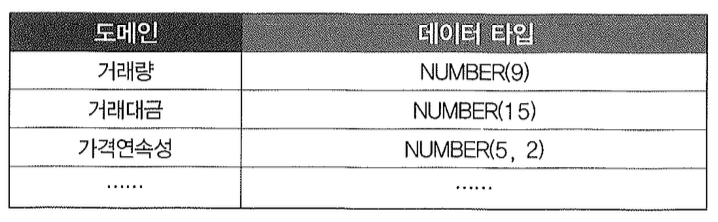
일평균거래량을 예로들면, 거래량 도메인은 9자리 숫자형이고 정수값만 허용하므로 입력 가능한 최소값은 0, 최대값은 99,999,999이다. 따라서 사용자가 1000주를 입력하면 사용자가 선택한 비교 연산자에 따라 아래와 같이 Between 시작값과 종료값을 바인딩하면 된다.
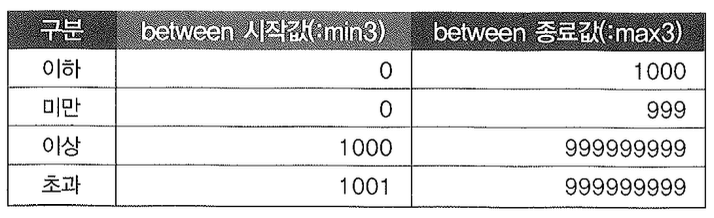
정수형이 아닌 가격연속성을 하나 더 예로들면, 가격연속성 도메인은 소수점 이하 2 자리를 갖는 총 5자리 숫자형이므로 입력 가능한 최소값은 0.00, 최대값은 999.99이다. 따라서 사용자가 50%를 입력하면 사용자가 선택한 비교 연산자에 따라 아래와 같이 Between 시작값과 종료값을 바인딩하면 된다.