<오라클 성능 고도화 원리와 해법1> Ch05-05 Fetch Call 최소화
오라클 성능 고도화 원리와 해법1 - Ch05-05 Fetch Call 최소화
지금부터 설명할 Fetch Call 최소화 원리 내용을 요약하면 다음과 같다.
- 부분 범위 처리 원리
- OLTP 환경에서 부분 범위 처리에 의한 성능 개선 원리
- ArraySize 조정에 의한 Fetch Call 감소 및 블록 I/O 감소 효과
- 프로그램 언어에서 Array 단위 Fetch 기능 활용
(1) 부분 범위 처리 원리
클릭했을 때 아래 JAVA Method를 호출하는 실행 버튼이 있다고 하자. SQL문에 사용된 BIG_TABLE이 1억 건에 이르는 대용량 테이블인데도 실제 테스트해보면 버튼을 클릭하자마자 곧바로 결과를 반환한다. 1억 건의 테이블을 그렇게 빨리 읽을 수 있는 원리는 무엇일까?
이런 상황에서 쿼리를 수행해보면, 엔터를 입력하자마자 5건을 출력하고 잠시 멈춘 듯하다가 33초가 경과한 후에 마지막 6번째 레코드를 출력하고 수행을 종료한다. 왜 이런 현상이 발생하는걸까?
Array Size를 5로 설정한 데서 해답을 찾을 수 있는데, 그림 5-5를 보면서 이해해보자.
공사장에서 미장공이 시멘트를 이용해 벽돌을 쌓는 동안 운반공이 벽돌을 실어나르고 있다. 아마 집을 짓는 듯하다. 쌓여있는 벽돌을 한번에 모두 실어나를 수 없기 때문에 수레를 이용해 일정량씩 나누어 운반하는 모습을 볼 수 있다. 운반공은 미장공이 벽돌을 더 가져오라는 요청(-> Fetch Call)이 있을 때만 벽돌을 실어나른다. 추가 요청이 없으면 운반 작업은 거기서 멈춘다.
DBMS도 이처럼 데이터를 클라이언트에게 전송할 때 일정량씩 나누어 전송하며, 오라클의 경우 ArraySize(또는 FetchSize) 설정을 통해 운반 단위를 조절한다. 그리고 전체 결과 집합 중 아직 전송하지 않은 분량이 많이 남아있어도 클라이언트로부터 추가 Fetch Call을 받기 전까지는 그대로 멈춰서 기다린다. 여기에 OLTP 환경에서 대용량 데이터를 빠르게 핸들링 할 수 있는 아주 중요한 원리가 숨어있다.
앞에서 1억 건 짜리 BIG_TABLE을 쿼리하는데 1초가 채 걸리지 않는다고 했는데, 그것도 Array 단위 Fetch 때문에 나타나는 효과다. 물론 1억 건 전체를 읽고 처리한 것은 아니며, rs.next()를 한 번만 호출하고 곧바로 ResultSet과 Statement를 닫아 버렸다. rs.next()를 호출하는 순간 오라클은 FetchSize(자바에서 기본값은 10)만큼을 전송했고, 클라이언트는 그 중 한 건만 콘솔에 출력하고는 곧바로 커서를 닫은 것이다. 추가 요청 없이 그대로 커서를 닫아버리면 오라클은 데이터를 더는 전송하지 않고 바로 일을 마친다. 이처럼 쿼리 결과 집합을 전송할 때, 전체 데이터를 쉼 없이 연속적으로 처리하지 않고 사용자로부터 Fetch Call이 있을 때마다 일정량씩 나누어서 전송하는 것을 이른바 ‘부분 범위 처리48)‘라고 한다. (어떤 오라클 튜닝 서적을 보면, 쿼리 수행 시 그 결과 집합을 버퍼 캐시에 모두 적재하고 나서 사용자에게 전송한다고 설명하고 있다. 그 책을 보고 지금까지 그렇게 이해하고 있는 독자가 있다면 여기서 개념을 다시 정립하기 바란다.)
그러면 적정한 데이터 운반단위는 얼마일까? 항상 결론은 ‘적당한 게 좋다’이다. 공사장을 다시 예로 들어보자. 힘을 적게 들이면서 한 번에 실어 나를 수 있는 적당량을 운반 단위로 정하고 그만큼씩만 실어나르는 것이 가장 효과적인데, 적당량이라고 하는 게 공사장 성격에 따라 다르다. 작은 집 담장을 쌓고 있다면 작은 수레를 이용해 소량씩 나르다가 멈춰야 할 시점에 멈추는 것이 유리하고, 아파트를 짓고 있다면 가능한 한 큰 수레를 이용해 한 번에 많은 양을 실어나르는 것이 유리하다. 만약 담장을 쌓는 정도의 공사 인데 10,000개씩 실어나르면 그 중 1,000개만 쓰고 나머지 9,000개는 버리는 일이 생길 지도 모른다. 그럼, 한 개씩 실어나르는 것이 효과적일까? 아마 어깨, 팔은 멀쩡한데 다리만 아프고 작업 속도는 훨씬 늦어질 것이다.
지금까지 설명한 부분 범위 처리 원리를 이해했다면, 네트워크를 통해 전송해야할 데이터 양에 따라 ArraySize를 조절할 필요가 있음을 직감했을 것이다. 예를 들어, 대량 데이터를 파일로 내려받는다면 어차피 전체 데이터를 전송해야 하므로 가급적 그 값을 크게 설정해야 한다. ArraySize를 조정한다고 해서 전송해야 할 총량이 변하지는 않지만, Fetch Call 횟수를 그만큼 줄일 수 있다. 반대로 앞쪽 일부 데이터만 Fetch하다가 멈추는 프로그램이라면 ArraySize를 작게 설정하는 것이 유리하다. 불필요하게 많은 데이터를 전송하고 버리는 비효율을 줄일 수 있기 때문이다.
ArraySize를 5로 설정하면, 서버 측에서는 Oracle Net 으로 데이터를 내려보내다가 5 건 당 한 번씩 전송명령을 날리고는 클라이언트로부터 다시 Fetch Call 이 올 때까지 대기 한다. 클라이언트 측에는 서버로부터 전송받은 5개 레코드를 담을 Array 버퍼가 할당되 며, 그곳에 서버로부터 받은 데이터를 담았다가 한 건 씩 꺼내 화면에 출력하거나 다른 작 업들을 수행한다.
| SDU, TDU |
|---|
| 흔히 Array Fetch를 얘기할 때, Array 버퍼가 서버즉(Server Side)에 할당된다고 생각한다. 서버즉 Array 버퍼에 데이터가 차면 전송한다는 설명이다. 하지만 필자가 아는 한 Array 버퍼는 클라이언트즉(Client Side)에 위치하며, 서버측에서는 SDU에 버퍼링이 이루어 진다. Array Fetch를 수행하는 내부 메커니즘에 대해 자세히 알아보자. 오라클에서 데이터를 전송하는 단위는 ArraySize에 의해 결정된다. 하지만 내부적으로 데 이터는 네트워크 패킷 단위로 단편화되어 여러번에 걸쳐 나누어 전송된다. 부분 범위 처리 내에 또 다른 부분 범위 처리가 작동하는 것이다. 이것은 네트워크 프로그램을 해보았다면 너무 상식적인 얘기다. 예를 들어, ArraySize가 100이고 한 레코드 당 1MB를 차지한다면 한번 Fetch 할 때마다 100MB를 전송해야 하는데, 이를 하나의 패킷으로 묶어 한 번에 전송하지는 않는다. 네트워크를 통해 큰 데이터를 전송할 때는 작은 패킷들로 단편화해야 하며, 그래야 유실이나 에러가 발생했을 때 부분 재전송을 통해 복구할 수 있다. IT에 종사하면서 OSI 7 레이어를 모르는 독자는 아마 없을 것이다. 이것은 Application, Presentation, Session, Transport, Network, Data Link, Physical 이렇게 7개 레이어로 이루어진다. 오라클 서버와 클라이언트는 Application 레이어에 위치하며, 그 아래에 있는 레이어를 통해 서로 데이터를 주고 받는다. SDU(Session Data Unit는 Session 레이어 데이터 버퍼에 대한 규격으로서, 네트워크를 통해 전송하기 전에 Oracle Net이 데이터를 담아두려고 사용하는 버퍼다. 예컨대, Array Size를 5 로 설정하면 클라이언트측에는 서버로부터 전송받은 5개 레코드를 담을 Array 버퍼를 할당한다. 서버측에서는 Oracle Net으로 데이터를 내려보내다가 5건당 한 번씩 전송 명령을 날리고는 매번 클라이언트로부터 다음 Fetch Call 을 기다리는데, Oracle Net이 서버 프로세스로부터 전송명령을 받을 때까지 데이터를 버퍼링하는 곳이 SDU다. Oracle Net은 서버 프로세스로부터 전송 요청을 받기 전에라도 SDU가 다 차면 버퍼에 쌓인 데이터를 전송하는데, 이 때는 클라이언트로부터 Fetch Call을 기다리지 않고 곧이어 데이터를 받아 SDU를 계속 채워나간다. TDU(Transport Data Unit)는 Transport 레이어 데이터 버퍼에 대한 규격이다. 물리적인 하부 레이어로 내려보내기 전에 데이터를 잘게 쪼개어 클라이언트에게 전송되는 도중에 유실이나 에러가 없도록 제어하는 역할을 한다. |
(2) OLTP 환경에서 부분 범위 처리에 의한 성능 개선 원리
이제 부분 범위 처리 원리에 대해 이해했으므로 직전에 수행한 테스트에서 왜 5건만 출력하고 한동안 멈춰서 있었는지 설명할 수 있다. 이미 원리를 충분히 설명했지만 좀 더 직관적으로 이해할 수 있도록 그림 5-6을 그려보았다.
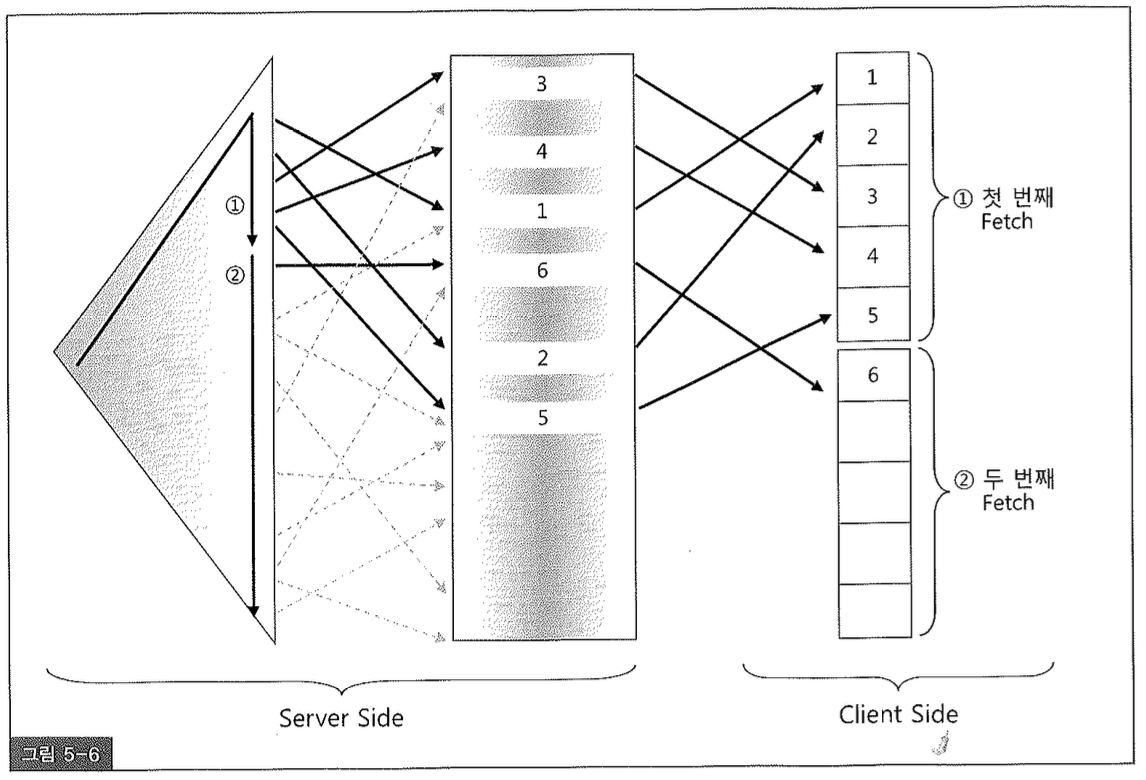
‘x > 0 and y <= 6’ 조건으로 쿼리를 수행하면, 첫 번째 Fetch Call(①)에서는 인덱스를 따라 x 컬럼 값이 1~5인 5개 레코드를 전송받아 Array 버퍼에 담는다. x와 y 컬럼 값을 같게 입력해 놓았으므로 이들 5개 레코드는 테이블 필터 조건인 y <= 6 조건도 만족한다. 오라클 서버는 이 5개 레코드를 아주 빠르게 찾았으므로 지체없이 전송명령을 통해 클라이언트에게 전송하고, 클라이언트는 Array 버퍼에 담긴 5개 레코드를 곧바로 화면에 출력한다.
문제는 두 번째 Fetch Call(②)에서 발생한다. 사용자로부터 두 번째 Fetch Call 명령을 받자 마자 x = y = 6 인 레코드를 찾아 Oracle Net으로 내려보낸다. 이제 ‘x > 0 and y <= 6’ 조건을 만족하는 레코드가 더 없다는 사실을 오라클은 모르기 때문에 계속 인덱스를 스캔하면서 테이블을 액세스해본다. 끝까지 가본 후에야 더는 전송할 데이터가 없음을 인식하고 그대로 한 건만 전송하도록 Oracle Net에 명령을 보낸다. Oracle Net은 한 건 만 담은 패킷을 클라이언트에게 전송한다. 클라이언트는 Array 버퍼가 다시 채워지기를 기다리면서 30여 초 이상을 허비했지만 결국 한 건 밖에 없다는 신호를 받고 이를 출력한 후에 커서를 닫는다.
이런 부분 범위 처리 원리 때문에 OLTP 환경에서는 결과 집합이 많을수록 오히려 성능이 더 좋아진다.
여기에 한 가지를 더해, OLTP 업무에서는 쿼리 결과 집합이 아주 많더라도 그 중 일부만 Fetch하고 멈출 때가 자주 있다. 따라서 출력 대상 건이 많을수록 Array를 빨리 채울 수 있어 쿼리 응답 속도도 그만큼 빨라진다. 인덱스와 부분 범위 처리 원리를 잘 활용하면 OLTP 환경에서 극적인 성능 개선 효과를 얻을 수 있는 원리가 여기에 숨어있다.
어부가 배를 타고 바다에 나가 낚시를 하는 것에 비유하면, 물 반 고기 반인 황금 어장에서는 배를 금방 채워 몇 시간 되지 않아 집으로 돌아갈 수 있지만 고기가 얼마 없는 어장에서는 온종일 낚시를 하고도 배를 다 채우지 못한 채 귀가하는 것과 같은 이치다.
데이터가 많을수록 더 빨라진다는 의미는 부분 범위 처리가 가능한 업무에 한하며, 서버가 공 프로그램이나 DW 성 쿼리처럼 결과 집합 전체를 Fetch 해야 한다면 결과 집합이 많을수록 더 빨라지는 일은 있을 수 없다.
(3) ArraySize 조정에 의한 Fetch Call 감소 및 블록 I/O 감소 효과
대량 데이터를 내려받을 때 ArraySize를 크게 설정할수록 그만큼 Fetch Call 횟수가 줄어 네트워크 부하가 감소하고, 쿼리 성능이 향상된다. 그뿐만이 아니다. 서버 프로세스가 읽어야 할 블록 개수까지 줄어드는 일거양득의 효과를 얻게 된다. ArraySize를 조정하는데 왜 블록 I/O가 줄어드는 것일까?
ArraySize를 키울수록 Fetch Count 횟수가 줄고 더불어 Block I/O까지 주는 것을 볼 수 있다. 즉, 반비례 관계다. 보기 쉽게 표와 그래프로써 정리해보았다.
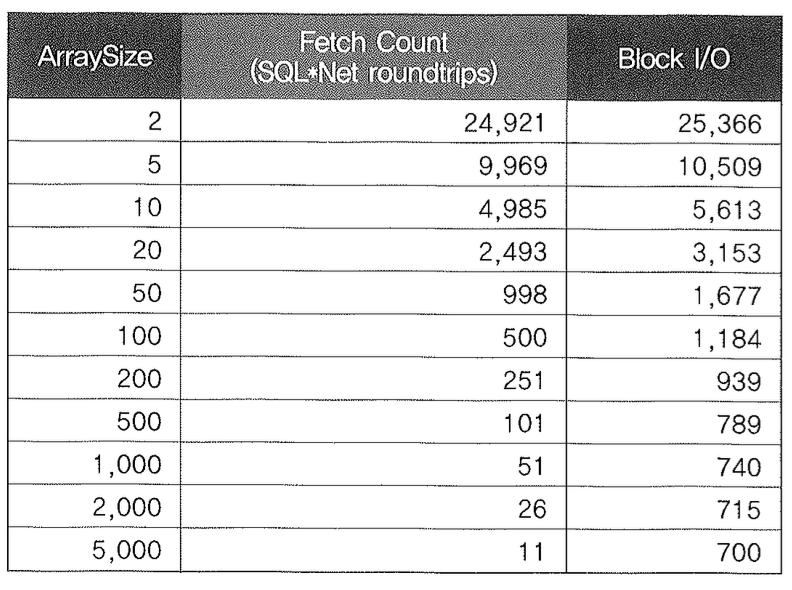
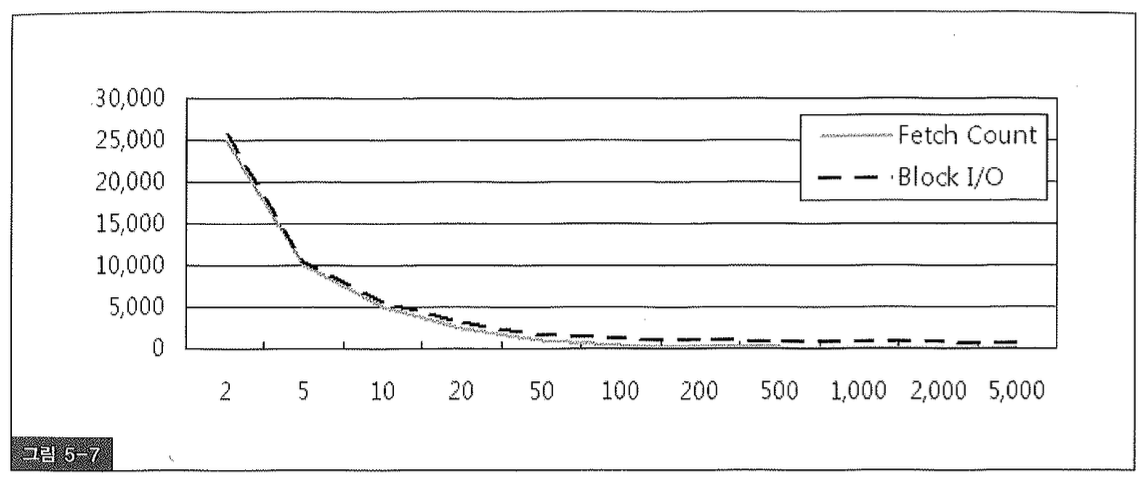
그림 5-7에서 눈에 띄는 것은, ArraySize를 키운다고 해서 같은 비율로 Fetch Count와 Block I/O가 줄지는 않는다는 점이다. 따라서 무작정 크게 설정한다고 좋은 것만은 아니며 일정 크기 이상이면 오히려 리소스만 낭비하게된다. 데이터 크기에 따라 다를텐데, 위 데이터 상황에서는 100 정도로 설정하는게 적당해 보인다.
ArraySize가 늘면서 블록 I/O까지 감소하는 원리를 설명해보자.
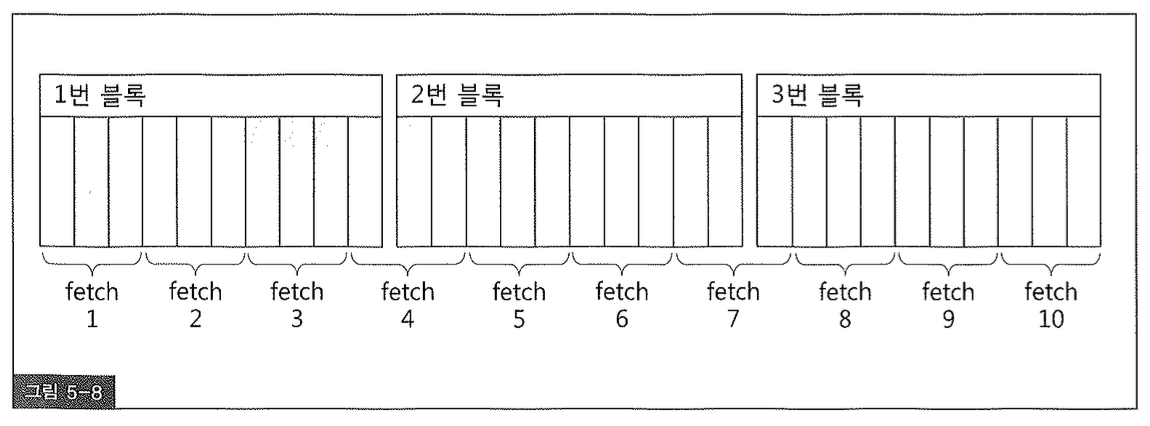
그림 5-8 처럼 10개 행으로 구성된 3개의 Block이 있다고 하자. 총 30개 레코드이므로 ArraySize를 3으로 설정하면 Fetch 횟수는 10이고, 이때 Block I/O는 12번이나 발생하게 된다. 왜냐하면, 10개 레코드가 담긴 블록들을 각각 4번에 걸쳐 반복 액세스해야하기 때문이다. 그림에서 보듯, 첫번째 Fetch에서 읽은 1번 블록을 2~4번째 Fetch에서도 반복 액세스하게된다. 2번 블록은 4~7번째 Fetch, 3번 블록은 7~10번 Fetch에 의해 반복 적으로 읽힌다. 만약 ArraySize를 10으로 설정한다면 3번의 Fetch와 3번 블록 I/O로 줄일 수 있다. 그리고 ArraySize를 30 으로 설정하면 Fetch 횟수는 1로 줄어든다.
(4) 프로그램 언어에서 Array 단위 Fetch 기능 활용
지금까지 SQL*Plus 중심으로만 설명했는데, PL/SQL을 포함한 프로그램 언어에서 어떻게 ArraySize를 제어하는 지 확인 해 보자.
PL/SQL에서 커서를 열고 레코드를 Fetch 하면, (4절 Array Processing에서 보았던 Bulk Collect 구문을 사용하지 않는 한) 9i까지는 한 번에 한 로우씩만 처리(Single-Row Fetch)했었다. 10g부터는 자동으로 100개씩 Array Fetch가 일어난다. 단, 아래처럼 Cursor FOR Loop 구문을 이용할 때만 작동한다.
1
2
3
4
for item in cursor
loop
......
end loop;
setFetchSize 메서드를 이용해 FetchSize를 조정하는 예는 앞절에서 잠깐 본 적이 있다. JAVA에서 FetchSize 기본 값은 10이다. 대량 데이터를 Fetch 할 때 이 값을 100~500 정도로 늘려주면 기본값을 사용할 때보다 데이터베이스 Call 부하를 1/10 ~ 150로 줄일 수 있다. 예를 들어, FetchSize를 100으로 설정했을 때 데이터를 Fetch 해 오는 메커니즘은 아래와 같다
- 최초 rs.next() 호출 시 한꺼번에 100건을 가져와서 클라이언트 Array 버퍼에 캐싱한다.
- 이후 rs.next() 호출할 때는 데이터베이스 Call을 발생시키지 않고 Array 버퍼에서 읽는다.
- 버퍼에 캐싱되어있던 데이터를 모두 소진한 후 101번째 rs.next() 호출시 다시 100 건을 가져온다.
- 모든 결과 집합을 다 읽을 때까지 2~3번 과정을 반복한다.