<오라클 성능 고도화 원리와 해법1> Ch05-07 PL/SQL 함수의 특징과 성능 부하
오라클 성능 고도화 원리와 해법1 - Ch05-07 PL/SQL 함수의 특징과 성능 부하
(1) PL/SQL 함수의 특징
오라클은 PL/SQL로 작성된 함수/프로시저의 이식성을 고려해, 오라클 서버가 아닌 Oracle Forms, Oracle Reports 같은 제품에서도 수행될 수 있도록 설계하였다. 그래서 PL/SQL로 작성한 함수와 프로시저를 컴파일하면 JAVA 언어처럼 바이트 코드(bytecode, machine-readable code)가 생성되며, 이를 해석하고 실행할 수 있는 PL/SQL 엔진(가상머신, Virtual Machine)만 있다면 어디서든 실행될 수 있다. 바이트 코드는 데이터 딕셔너리에 저장되었다가 런타임 시 해석된다.
현재는 가장 인기 있는 개발 언어가 된 JAVA가 초기에 고전했던 이유는 바로 속도 때문이었는데, PL/SQL도 JAVA처럼 인터프리터(Interpreter) 언어이기 때문에 Native 코드로 완전 컴파일된 내장(Build-In) 함수에 비해 많이 느리다. 이 문제를 극복하려고 오라클 9i부터 해당 플랫폼 Native 코드로 컴파일할 수 있는 기능을 제공하기 시작했지만, 사용상 복잡성 때문에 잘 사용되지 않고 있는 실정이다.
그리고 연산 위주의 작업을 주로 수행한다면 큰 효과를 보겠지만, 뒤에서 설명하는 것 처럼 함수/프로시저 성능이 나빠지는 이유가 대부분 그 안에 있는 Recursive SQL을 수행하기 때문이므로 Native 코드로 컴파일하더라도 큰 도움이 되지 못할 때가 많다.

어쨌든 대부분 위와 같은 Interpreted 실행 환경에서 개발하므로 이를 기준으로 설명을 진행하겠다.
PL/SQL은 인터프리터 언어이므로 그것으로 작성한 함수 실행 시 매번 SQL 실행엔진과 PL/SQL 가상머신(Virtual Machine) 사이에 컨텍스트 스위칭(Context Switching)이 일어난다. SQL에서 함수를 호출할 때마다 SQL 실행엔진이 사용하던 레지스터 정보들을 백업했다가 PL/SQL 엔진이 실행을 마치면 다시 복원하는 작업을 반복하게 되므로 느려질 수밖에 없다. C++, JAVA, VB와 같은 일반 프로그래밍 언어에서는 될 수 있으면 함수/프로시저를 이용해 잘게 모듈화 • 공용화하는 것이 권장사항이지만 PL/SQL 함수와 프로시저를 그런 식으로 활용하면 안되는 이유가 여기에 있다.
원리를 잘 알고 사용하면 PL/SQL 함수와 프로시저를 이용해 성능을 높일 수 있는 요소가 많지만, 잘못 사용하면 심각한 성능 부하를 일으킬 수 있다. 간단한 테스트를 통해 그 부하의 심각성을 살펴보자.
(2) Recursive Call를 포함하지 않는 함수의 성능 부하
아래는 가장 흔히 볼 수 있는 사용자 정의 함수 남용 사례인데, 날짜형 데이터를 공통 문자열 포맷으로 변환하려고 함수를 정의하는 경우다.


오라클 내장(Built-In) 함수 to_char와 사용자 정의 함수를 사용할 때의 수행 시간을 비교했더니, 2.45초만에 수행되던 것이 15.57초 소요된 것을 볼 수 있다. 서버 사양에 따라 다른 데, Recursive Call 없이 컨텍스트 스위칭 효과만으로 보통 5~10배 정도 느려진다. 0.1초 미만으로 수행되는 쿼리가 5~10배 정도 느려지면 별거 아니라고 생각할지 모르지만 1시간 걸리던 배치 프로그램이 함수 하나 때문에 5시간 넘게 걸린다고 생각해보라.
(3) Recursive Call를 포함하는 함수의 성능 부하
5배쯤 느려지는 위 테스트 결과가 사소하게 느껴질 수 있다. 그런데 대개의 사용자 정의 함수에는 Recursive Call을 포함한다. 네트워크 트래픽을 발생시키는 User Call에 비하면 그 비용이 훨씬 적지만 Recursive Call도 매번 Execute Call과 Fetch Call을 발생시키기 때문에 대량의 데이터를 조회하면서 레코드 단위로 함수를 호출하도록 쿼리를 작성 하면 성능이 극도로 나빠진다. 위에서 사용한 date_to_char 함수에 DUAL 테이블을 읽는 간단한 select 문 하나를 삽입하고 다시 테스트해보자.
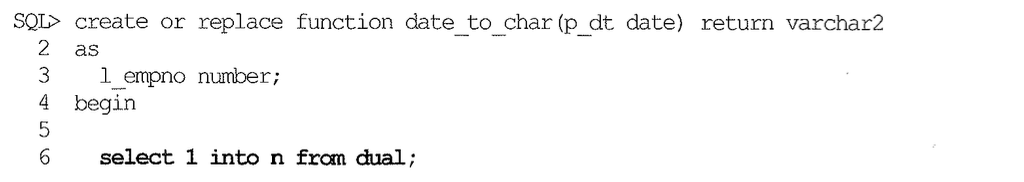

1분 5초가량 소요되었다. I/O가 전혀 발생하지 않는 가벼운 쿼리49)를 삽입했을 뿐인데, Recursive Call 없는 함수와 비교하면 4배, 함수를 사용하지 않았을 때와 비교하면 23배 가량 더 느려졌다. 15초가 1분 5초 걸린 것을 보고 4배 느려지는 정도는 참을 수 있다고 생각할지 모르지만, 1시간 걸리는 쿼리가 4시간 걸릴 수도 있는 것이다. 23배라면? 23시간이다.
아래 SQL 트레이스 결과를 보고나면 쿼리 성능이 급격히 저하된 원인을 쉽게 확인할 수 있다.
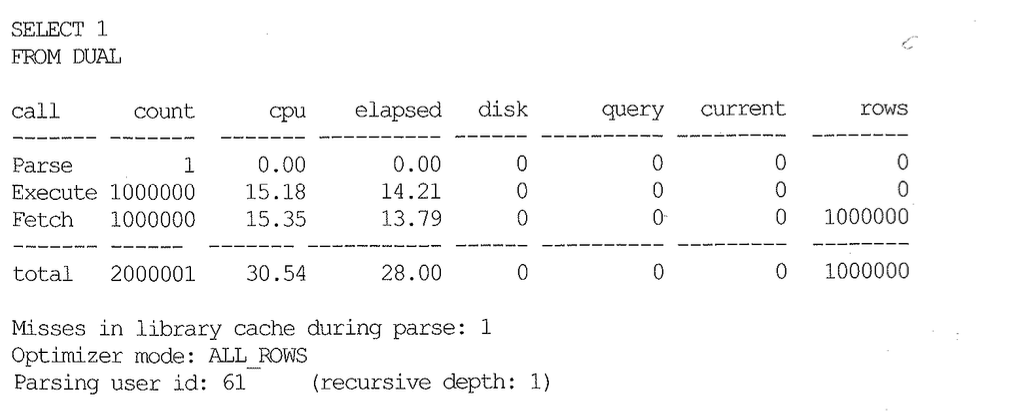
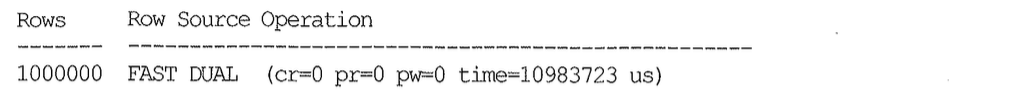
지금까지 강조하고 또 강조한 데이터베이스 Call이 200만 번이나 추가로 더 발생했다. 쿼리 하나를 수행하는데 말이다. 다행히 Parse Call은 한 번뿐이다. 함수가 커서를 캐싱한 채로 라이브러리 캐시에 캐싱돼있었기 때문이다. 여기서는 최초 테스트(Recursive Call 없는 경우)와의 공정한 비교를 위해 추가 I/O가 발생하지 않도록 DUAL 테이블을 사용했지만 실제 상황이라면 함수에서 발생하는 Recursive Call은 대부분 I/O를 수반하므로 실제 훨씬 큰 성능 저하를 일으킨다.
이처럼 대용량 조회 쿼리에서 함수를 남용하면 읽는 레코드 수만큼 건건이 함수 호출이 발생해 성능이 극도로 나빠진다. 따라서 사용자 정의 함수는 소량의 데이터 조회시에만 사용하거나, 대용량 조회 시에는 부분 범위 처리가 가능한 상황에서 제한적으로 사용해야 한다. 그리고 성능을 위해서라면 가급적 조인 또는 스칼라 서브쿼리 형태로 변환하려고 노력해야 한다.
(4) 함수를 필터 조건으로 사용할 때 주의사항
함수를 where 절에서 필터 조건으로 사용할 때도 각별한 주의가 필요하다. 조건절과 인덱스 상황에 따라 함수 호출 횟수가 달라지기 때문이다. 테스트를 위해 emp 테이블을 읽어 평균 급여를 리턴하는 함수를 만들고, 컬럼 구성을 달리 하는 인덱스 4개를 만들어 보자.

테스트 결과를 표로써 요약해 보자.
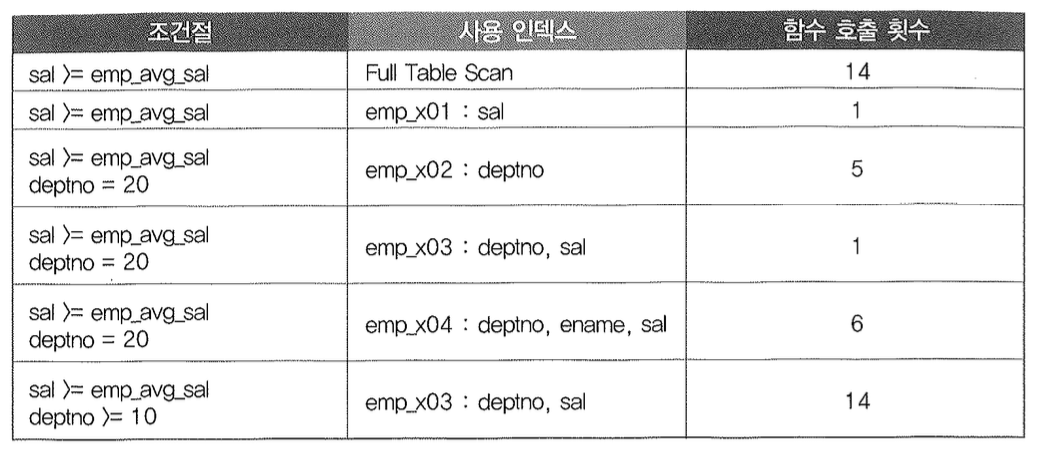
여기서는 작은 테이블을 사용했으므로 직접 테스트해 보더라도 성능차이를 느낄 수 없겠지만, 실제 사용하는 대용량 테이블에서는 조건절과 인덱스 구성에 따라 성능 차이가 매우 크게 나타날 수 있음을 이해할 것이다.
(5) 함수와 읽기 일관성
성능 문제 외에도 사용자 정의 함수를 사용할 때 꼭 알아두어야 할 주의사항이 있다. 1장에서 설명한 읽기 일관성과 관련 있는데, 테스트를 위해 LookupTable과 이를 액세스하는 함수를 정의해보자.


여기서 생성한 lookup 함수를 참조하는 쿼리가 있다고 하자. 그 쿼리를 수행하고 결과 집합을 Fetch 하는 동안 다른 세션에서 LookupTable로부터 value 값을 변경한다면 어떤 일이 발생할까? 레코드를 Fetch 하면서 lookup 함수가 반복 호출되는데, 중간부터 다른 결과값을 반환하게 된다. 가장 기본적인 문장 수준의 읽기 일관성(Statement-level consistency)이 보장되지 않는 것으로서, 함수 내에서 수행되는 Recursive 쿼리는 메인 쿼리의 시작 시점과 무관하게 그 쿼리가 수행되는 시점을 기준으로 블록을 읽기 때문에 생기는 현상이다.
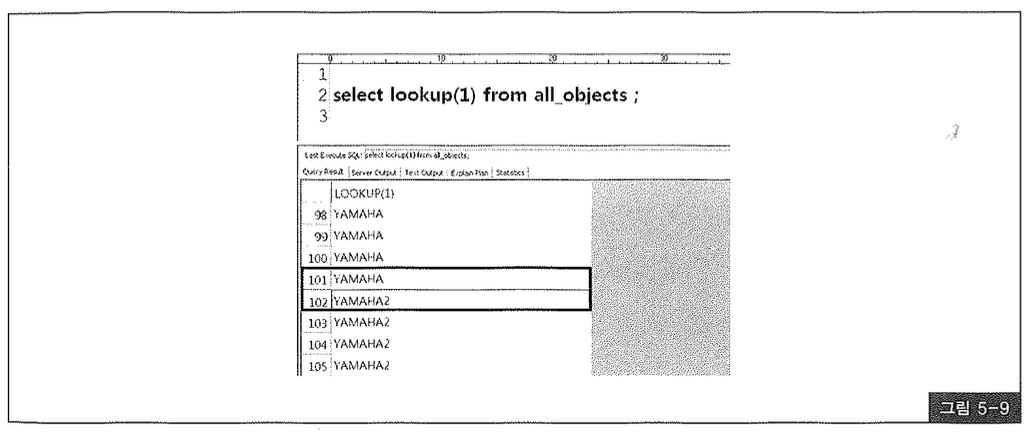
토드나 오렌지 같은 쿼리 툴에서 그림 5-9 처럼 큰 테이블(또는 뷰)을 이용해 lookup 함수를 호출하도록 select 문을 수행시켜보라. 그리고 결과 집합을 스크롤하는 도중에 다른 세션에서 LookupTable의 value를 변경하고 커밋해보라. 그런 후 계속 스크롤을 진행하다보면 그림 5-9 처럼 입력값이 같은데도 중간부터 다른 값을 출력하는 것을 발견할 것이다.
아래처럼 일반 조인문 또는 스칼라 서브쿼리를 사용할 때만 완벽한 문장 수준의 읽기 일관성이 보장된다.
이런 읽기 일관성 문제는 프로시저, 패키지, 트리거를 사용할 때도 공통적으로 나타나는 현상이다. 오라클에서 트리거를 사용하면 데이터 정합성이 깨진다는 얘기를 자주 듣는데, 사실은 오라클만의 독특한 읽기 일관성 모델을 정확히 이해하지 못한 상태에서 개발하기 때문에 생기는 현상이라고 봐야 한다. 함수/프로시저를 잘못 사용하면 성능을 떨어뜨릴 뿐 아니라 데이터 정합성까지 해칠 수 있으므로 주의해야 한다.
(6) 함수의 올바른 사용 기준
지금까지의 설명을 듣고나면 함수를 쓰지 말라는 얘기처럼 들릴 수 있다. 실제 오라클 함수/프로시저를 절대 사용하지 못하도록 개발표준이 정해지는 경우가 종종 있다. 최근 모 통신사 프로젝트가 그랬다. 필자가 거기서 데이터베이스 튜닝업무를 맡았는데, 반드시 함수를 써야만 성능문제를 해결할 수 있는 상황에 직면해 그 개발 표준을 타파해 보려고 노력했던 기억이 난다. 하지만 결국 실패하고 말았는데, 예외를 인정할 수 없다는 것이었다. 재미있는 것은 그 개발 표준이 제정된 이유도 바로 성능 때문이었다. 애플리케이션 아키텍처 팀의 개발 표준 담당자가 과거에 함수를 사용하다 낭패를 본 경험이 있었던 것 같다.
위에서 언급한 주의사항들은 함수를 가급적 쓰지 말라는 의미로 설명한 것이 아니다. 함수를 사용했을 때 성능이 느려지는 원리를 이해하고 잘 활용하라는 뜻이다. 함수를 써서 오히려 성능을 향상시키는 사례도 많다. 2장에서 설명했던 채번 함수(sq_nextval)가 대표적인 케이스다. 오라클 Sequence 오브젝트를 사용하지 않는 한, Lock 경합을 최소화하면서 이보다 더 빠르게 채번하는 방법은 없다. 채번을 위해 PL/SQL 함수를 사용하지 않았다면 애플리케이션 단에서 select, insert, update를 날리면서 채번했을 텐데, 이는 User Call을 발생시키는 것이므로 Recursive Call 보다 현저히 느리고, Lock 경합 시 대기 시간도 더 길어지기 마련이다.
그리고 테이블에 트리거를 정의하면 DML 속도가 느려진다고 흔히 얘기하지만 트리거를 통해 처리하려했던 그 목적을 트리거보다 더 빠르게 달성할 수 있는 방법이 있던가? 배치(Batch)로 처리하면 모를까, 실시간 요건을 만족하면서 애플리케이션 단에서 트리거보다 더 빠르게 처리하는 방법은 없다.
앞에서 Recursive Call 부하를 강조한 것은, 조금 더 고민하면 조인으로 처리할 수 있는데 개발 생산성만을 고려해 무분별하게 함수를 남용했을 때 생기는 부작용을 지적하고자 했을 따름이다. 함수/프로시저를 사용하지 않았을 때 결국 User Call을 발생시키도록 구현해야한다면, 오라클 함수/프로시저를 사용하는 편이 더 나은 선택이다.
읽기 일관성 문제도 마찬가지다. 오라클 함수를 사용하지 않고 애플리케이션 단에서 구현하더라도 같은 문제가 발생하므로 함수 사용에 따른 폐단으로 규정하는 것은 문제가 있다. 대부분 개발자들이 모르고 있는 사실이므로 주의를 당부한 것이고, 애플리케이션 단에서 구현할 때와 마찬가지로 데이터 일관성이 깨지지 않도록 설계하고 개발해야한다는 뜻에서 설명한 것이다.
반대로, 모든 프로그램을 PL/SQL 함수와 프로시저로 구현하려는 것도 문제가 될 수 있다. 라이브러리 캐시에서 관리해야할 오브젝트 개수와 크기가 늘어나면 아무래도 히트율(Hit Ratio)이 떨어지고, 경합이 증가해 효율성이 저하되기 마련이다. 그리고 특정 데이터베이스 오브젝트 정의를 변경하면, 라이브러리 캐시 오브젝트간 Dependency 체인을 따라 순간적으로 동시 컴파일을 유발해 시스템 장애로 연결될 가능성도 있다. 참고로, Dependency 체인에 의한 라이브러리 캐시 부하를 최소화하려면 가급적 함수/프로시저 보다 패키지를 사용하는 것이 유리하다.
참 어려운 얘기인데, 정해진 Shared Pool 크기 내에서 소화할 수 있는 적정 개수의 SQL(-> 바인드 변수의 사용이 이를 가능케 함)과 PL/SQL 단위 프로그램을 유지하도록 노력해야한다. 그러려면 역할을 분담해 연산 위주의 작업은 애플리케이션 서버 단에서 주로 처리하 고, SQL 수행을 많이 요하는 작업은 오라클 함수/프로시저를 이용하도록 설계할 필요가 있다.