<오라클 성능 고도화 원리와 해법1> Ch06-02 Memory vs. Disk I/O
오라클 성능 고도화 원리와 해법1 - Ch06-02 Memory vs. Disk I/O
(1) I/O 효율화 튜닝의 중요성
디스크를 경유한 입출력은 물리적으로 액세스 암(Arm)이 움직이면서 헤드를 통해 데이터를 읽고 쓰기 때문에 느리다. 반면, 메모리를 통한 입출력은 전기적 신호에 불과하기 때문에 디스크 I/O에 비해 비교할 수 없을 정도로 빠르다. 그래서 모든 DBMS는 버퍼 캐시를 경유해 I/O를 수행한다. DB 버퍼 캐시를 경유한다는 것은, 읽고자 하는 블록을 먼저 버퍼 캐시에서 찾아보고, 찾지 못할 때만 디스크에서 읽는 것을 말한다. 메모리로부터 블록이 찾아진다면 디스크 상의 데이터 파일에서 읽는 것보다 평균적으로 10,000배 이상 나은 성능을 보인다.
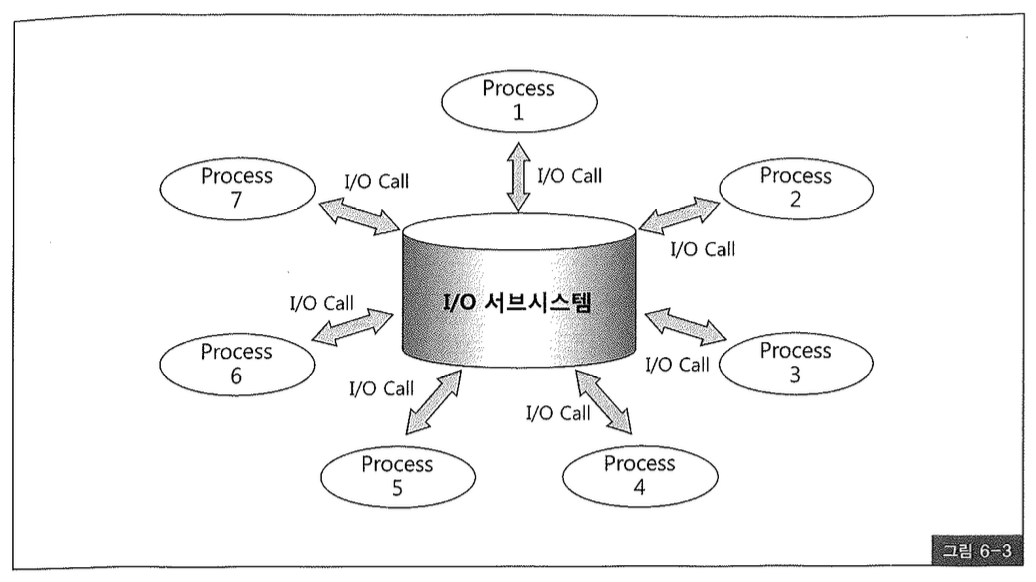
물리적인 디스크 I/O가 필요할 때면 서버 프로세스는 I/O 서브시스템에 I/O Call을 발생시키고 잠시 대기하게 되므로 비용이 큰 것이다. 디스크에 발생하는 경합이 심할수록 대기시간도 길어진다(그림 6-3). 독자의 PC에서 바이러스 검사, 디스크 오류 검사, 디스크 조각 모음 등을 동시에 수행하는 상황을 연상해보라.
만약 모든 데이터와 인덱스 블록을 DB 버퍼 캐시에 올려놓고 읽고 쓸 수 있다면 좋겠지만 비용과 기술적 측면에 한계가 있다. 메모리가 저렴해지는 것이상으로 데이터 증가 속도가 항상 더 빠르게 진행되고 있으며, 비용뿐 아니라 기술 측면에서도 메모리는 지금껏 항상 유한 자원이었다. 그런 유한한 메모리 자원을 좀 더 효율적으로 사용해야 하므로 자주 액세스하는 블록들이 캐시에 더 오래 남아있도록 LRU 알고리즘을 사용한다고 1장에서 설명했다. 결국 디스크 I/O를 최소화하고, 대부분 처리를 메모리에서 할 수 있도록 버퍼 캐시 효율성을 높이는 것이 데이터베이스 성능을 좌우하는 열쇠라고 하겠다.
(2) 버퍼 캐시 히트율(Buffer Cache Hit Ratio)
버퍼 캐시 효율을 측정하는 지표로서 전통적으로 가장 많이 사용되어온 것은 버퍼 캐시 히트율(이하 BCHR)다. 전체 읽은 블록 중에서 얼마나을 메모리 버퍼 캐시에서 찾았는지를 나타내는 것으로서, 구하는 공식은 아래와 같다.
1
2
3
BCHR = (캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수) X 100
= ((논리적 블록 읽기 - 물리적 블록 읽기) / 논리적 블록 읽기) X 100
= (1 - (물리적 블록 읽기) / (논리적 블록 읽기)) X 100
- ‘논리적 블록 읽기’ = ‘총 읽은 블록 수’
- ‘캐시에서 곧바로 찾은 블록 수’ = ‘논리적 블록 읽기’ - ‘물리적 블록 읽기’
공식에서 알 수 있듯이 BCHR은 물리적인 디스크 읽기를 수반하지 않고 곧바로 메모리에서 블록을 찾은 비율을 말한다.
Direct Path Read57) 방식으로 읽는 경우를 제외하면 모든 블록 읽기는 버퍼 캐시를 통해 이루어진다. 즉, 읽고자 하는 블록을 먼저 버퍼 캐시에서 찾아보고 없을 때 디스크로부터 읽어들이며, 이때도 디스크로부터 곧바로 읽는 게 아니라 먼저 버퍼 캐시에 적재한 후에 읽는다. 따라서 SQL을 수행하는 동안 캐시에서 읽은 총 블록 수를 ‘논리적 블록 읽기(Logical Reads)’ 라고 한다. 그리고 ‘캐시에서 곧바로 찾은 블록 수’는 디스크를 경유하지 않고 버퍼 캐시에서 찾은 블록 수를 말하므로 ‘총 읽은 블록 수(=논리적 블록 읽기)’ 에서 ‘물리적 블록 읽기(Physical Reads)’ 를 차감해서 구한다.
애플리케이션 성격에 따라 차이가 있지만 BCHR은, 온라인 트랜잭션을 주로 처리하는 시스템이라면 99% 달성을 목표로삼아야한다. BCHR를 주로 시스템 전체적인 관점에서 바라보지만, 개별SQL 측면에서 구해볼 수도 있는데 이 비율이 낮은 것이 쿼리 성능을 떨어뜨리는 주된 원인이다.

위에 있는 Disk 항목(다섯 번째 열)이 ‘물리적 블록읽기’에 해당한다. ‘논리적 블록 읽기’는 Query와 Current 항목을 더해서 구하며, Direct Path Reaad 방식으로 읽은 블록이 없다면 이 두 값을 더한 것이 ‘총 읽은 블록 수’가 된다. 총 1,351,677개 블록을 읽었는데, 그 중 601,458개는 디스크에서 버퍼 캐시로 적재한 후에 읽었다. 그러므로 위 샘플에서 BCHR은 56%다.
1
2
3
BCHR = (1 - (Disk / (Query + Current))) X 100
= (1 - (601,458 / (1,351,677 + 0))) X 100
= 55.5 %
논리적으로 100개 블록을 읽기를 요청하면 56개는 메모리에서 찾고, 44개는 메모리에 없어 디스크 I/O를 발생시켰다는 의미가 된다. 다른 대기 이벤트가 없었다면 CPU time과 Elapsed time 간에 발생한 시간차는 대부분 디스크 I/O 때문이라고 이해하면 된다.
BCHR를 구하는 공식을 통해 알 수 있는 것처럼 ‘논리적 블록 읽기’를 ‘메모리 블록 읽기’로 이해하기보다는 ‘블록 요청 횟수’ 또는 ‘총 읽은 블록 수’로 이해하는 것이 정확하다. 모든 블록을 메모리를 경유해 읽기 때문에 결과적으로 같은 것일 수 있지만, ‘논리적’을 메모리로부터’로 해석해 Call 통계를 잘못 해석하는 경우를 자주 보기 때문에 의미를 명확히 하고자 하는 것이다. 즉, 많은 분들이 위 Call 통계를 보고 디스크에서 601,458개, 메모리에서 1,351,677개 블록을 읽어 총 1,953,135개 블록을 읽었다고 잘못 해석한다.
아래는 위 Call 통계의 원본 SQL을 튜닝한 결과다.
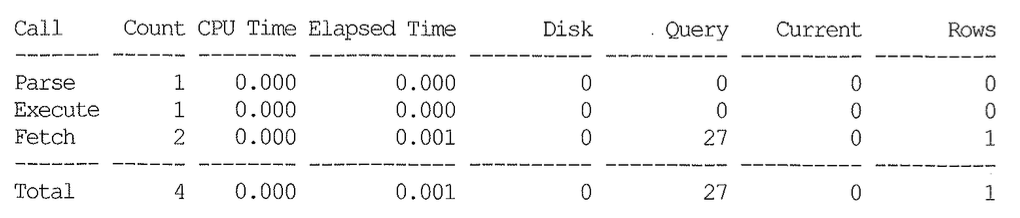
튜닝 전후 SQL이 서로 어떻게 달라졌는지 제시하지 않았으므로 조작된 것이라고 생각할 수 있지만 실제 튜닝을 통해 얻은 결과가 맞다. (SQL이 매우 길다는 이유도 있지만, 여기서는 BCHR 의미와 I/O 튜닝의 중요성을 강조하는 데에 목적이 있기 때문에 굳이 튜닝 전후 SQL을 제시하지 않았다.) 튜닝 전에는 논리적으로 1,351,677개의 블록을 요청했고, 많은 블록을 읽다 보니 디스크 블록 읽기도 601,458번이나 발생했었다. 하지만 튜닝을 통해 논리적인 블록 요청 횟수가 27번만 발생하니까 메모리에서 읽은 블록 수도 27개에 그치고, 설령 BCHR이 0%여서 27개를 모두 디스크에서 읽더라도 쿼리는 항상 빠르게 수행될 것이다.
이처럼 논리적인 블록 요청 횟수를 줄이고, 그럼으로써 물리적으로 디스크에서 읽어야 할 블록 수를 줄이는 것이 I/O 효율화 튜닝의 핵심 원리이다.
같은 블록을 반복적으로 액세스하는 형태의 애플리케이션이라면 논리적인 I/O 요청이 비효율적으로 많이 발생하는데도 BCHR은 매우 높게 나타난다. BCHR이 성능 지표로서 갖는 한계점이 바로 여기에 있다. 작은 테이블을 자주 액세스하면 모든 블록이 메모리에 서 찾아지므로 BCHR는 높겠지만 블록을 찾는 과정에서 래치를 얻어야 하므로 의외로 큰 비용을 수반한다.
특히, 같은 블록을 여러 세션에서 동시에 접근하면서 래치 경합과 버퍼 Lock 경합까지 발생한다면 메모리 I/O 비용이 오히려 디스크 I/O보다 크게 늘어날 수 있다58). 따라서 BCHR가 100%라고 하더라도 논리적으로 읽어야 할 블록 수의 절대량이 많다면 반드시 SQL 튜닝을 실시해서 논리적인 블록 읽기를 최소화해야 한다. 대량의 데이터를 기준으로 NL 조인 방식을 사용해 작은 테이블을 반복적으로 Lookup하는 경우가 대표적이다.
(3) 네트워크, 파일시스템 캐시가 I/O 효율에 미치는 영향
메모리 I/O, 디스크 I/O 발생량 뿐 아니라 최근에는 네트워크 속도가 I/O 성능에 지대한 영향을 미치고 있다. 예전에는 서버에 전용 케이블로 직접 연결된 외장형 저장 장치를 사용했지만 이제는 데이터베이스 서버와 스토리지 간에 NAS 서버나 SAN을 통해 연결되는 아키텍처를 사용한다. 대용량 데이터 저장과 관리 기법에 이런 네트워크 기술이 사용되기 시작한 지 이미 오래고, 따라서 디스크 속도뿐만 아니라 네트워크 속도까지 결합된 I/O 튜닝은 더 복잡해진 느낌이다.
이처럼 네트워크를 이용한 I/O 기법이 일반화되다 보니 I/O 성능 개선도 네트워크를 통한 전송량을 최소화하려는 쪽에 기술이 모아지고 있다. 우선, 서버와 스토리지 간에 더 크고 많은 파이프를 연결하려고 시도한다. 그리고 앞서 컬럼 기반(또는 컬럼 스토어) 데이터베이스가 DW 시장에서 각광을 받고 있다고 했는데59), 오라클은 현재의 I/O 방식을 고수하는 대신 네트워크를 통한 데이터 전송량을 최소화하는 쪽으로 기술을 발전시켜 나가고 있다.
최근 오라클은, 데이터베이스 서버와는 독립적으로 스토리지 자체에 CPU와 RAM을 탑재하는 하드웨어적인 솔루션을 도입했다. 그럼으로써 쿼리 프로세싱 중 일부를 스토리지가 처리하게끔 하는 지능형 스토리지 서버 개념이다. DW 시스템에 특화된 이 기술의 핵심은, 스마트 스캔이라는 기술을 이용해 쿼리에서 필요로 하는 컬럼과 로우만을 네트워크를 통해 전송하도록 하는 데에 있다. 이 기술을 이용하면 스토리지에서 데이터베이스 서버로 보내지는 데이터 양을 획기적으로 줄여주고, 서버의 CPU 부하를 감소시킨다.
그리고 오라클이 스토리지 서버를 도입하기 전에 이미 오래 전부터 CPU, RAM, 디스크를 일체형으로 개발한 MPP 방식의 어플라이언스 제품들이 많이 소개되어 왔다. 즉, 데이터를 여러 개 디스크에 분산 저장하고, 읽을 때도 동시에 ‘독립적으로’ 읽어 병렬 I/O 효과를 극대화한 제품들이다. 그리고 그런 기술들이 대부분 대용량 데이터 처리 속도를 극대화해야 하는 DW 시장에서 주목받는 것을 보더라도 데이터베이스 성능에 있어 I/O 효율이 얼마나 핵심적인 요소인지 알 수 있다.
오라클 RAC에서는 인스턴스 간에 네트워크를 통해 캐시된 블록들을 서로 공유함으로써 메모리 I/O 성능에도 네트워크 속도가 상당한 영향을 미치게 되었다. 통계적으로는 논리적 블록 읽기로 계수되지만, 그 중 일부는 다른 RAC 노드에서 네트워크를 통해 전송받은 것일 수 있기 때문이다. 기가비트(Gigabit) 단위의 초고속 인터커넥트(InterConnect) 전용 네트워크를 사용하지만 그것이 로컬 캐시에서 읽는 것보다 빠를 수는 없다. 그래서 전량 메모리에서 블록을 읽은 것으로 나타나는데도 성능이 느린 경우가 종종 있다.
같은 양의 디스크 I/O가 발생하더라도 I/O 대기시간이 크게 차이 날 때가 있다. 디스크 경합 때문일 수 있지만, OS에서 지원하는 파일 시스템 버퍼 캐시와 SAN 캐시 때문에 생기는 현상일 때가 많다. SAN 캐시는 마다할 이유가 없겠지만, 데이터베이스를 사용하는 데 있어 파일 시스템 버퍼 캐시는 최소화해야 한다. 데이터베이스 자체적으로 캐시 영역을 갖고 있으므로 이를 위한 공간을 크게 할당하는 것이 더 효과적이다.
아무튼, 디스크 속도가 문제이든, SAN이 문제이든, 아니면 RAC 인터커넥트가 문제이든 I/O 성능에 관한 가장 확실하고 근본적인 해결책은 논리적인 블록 요청 횟수를 최소화하는 것임을 잊지 말자. 방법은, SQL 튜닝에 있다.