<오라클 성능 고도화 원리와 해법1> Ch06-03 Single Block vs. Multiblock I/O
오라클 성능 고도화 원리와 해법1 - Ch06-03 Single Block vs. Multiblock I/O
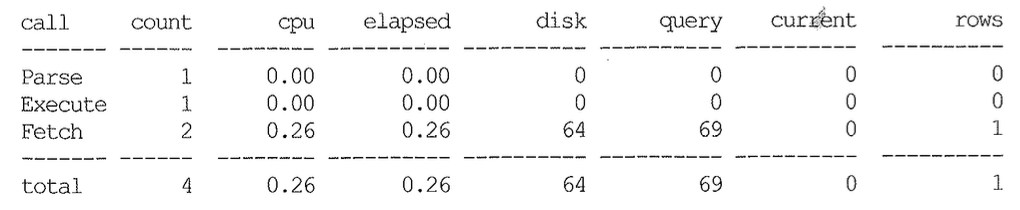
I/O Call 수행 원리에 대해 살펴보자. 위 Call 통계를 보면, 버퍼 캐시에서 69개 블록을 읽으면서 그 중 64개는 디스크에서 읽었다. 버퍼 캐시 히트율은 7.24%다. 디스크에서 읽은 블록 수가 64개라고 I/O Call까지 64번 발생했음을 의미하지는 않는다. 64번일 수도 있고, 그보다 작을 수도 있다.
읽고자 하는 블록을 버퍼 캐시에서 찾지 못했을 때, I/O Call을 통해 데이터 파일로부터 버퍼 캐시에 적재하는 방식에는 크게 두 가지가 있다.
- Single Block I/O
- Multiblock I/O
Single Block I/O는 말 그대로 한 번의 I/O Call에 하나의 데이터 블록만 읽어 메모리에 적재하는 것을 말한다. 인덱스를 통해 테이블을 액세스할 때는, 기본적으로 인덱스와 테이블 블록 모두 이 방식을 사용한다.
Multiblock I/O는 I/O Call이 필요한 시점에 인접한 블록들을 같이 읽어 메모리에 적재하는 것을 말한다. 오라클 블록 사이즈가 얼마전간에 OS 단에서는 보통 1MB(=1,024KB) 단위로 I/O를 수행한다(OS마다 다름). 한 번 I/O 할 때 1MB 크기의 ‘그릇’을 사용하는 것이므로 테이블 Full Scan처럼 물리적으로 저장된 순서에 따라 읽을 때는 그릇이 허용하는 범위 내에서 인접한 블록들을 같이 읽는 것이 유리하다. ‘인접한 블록’이란, 한 익스텐트 내에 속한 블록들을 말한다. 달리 말하면, Multiblock I/O 방식으로 읽더라도 익스텐트 범위를 넘지 못한다는 뜻이기도하다.
Multiblock I/O 단위는 db_file_multiblock_read_count 파라미터에 의해 결정된다. 이 파라미터가 16이면 한 번에 최대 16개 블록을 버퍼 캐시에 적재한다. 만약 db_block_size가 8,192 바이트면 한 번에 최대 131,072 바이트를 읽는 셈이 된다. 파라미터를 128로 바꾸면 1,048,576 바이트씩 읽는다. 대개 OS 레벨에서 I/O 단위가 1MB이므로 db_block_size가 8,192일 때는 최대 설정할 수 있는 값은 128이된다. 이 파라미터를 128 이상으로 설정해도 OS가 허용하는 I/O 단위가 1MB면 1MB씩 만 읽는다.
디스크 I/O는 비용이 크므로 I/O Call 한 번에 한 블록씩 읽는 것보다 여러 블록을 읽는 게 성능 향상에 도움이 되는데, 인덱스를 스캔할 때는 왜 한 블록씩 읽는 것일까? 인덱스 블록 간 논리적 순서는 물리적으로 데이터 파일에 저장된 순서와 다르다. 인덱스 블록 간 논리적 순서란, 인덱스 리프 블록끼리 이중 연결 리스트(Double Linked List) 구조로 연결된 순서를 말한다. 물리적으로 한 익스텐트에 속한 블록들을 I/O Call 발생 시점에 같이 적재해올렸는데, 그 블록들이 논리적 순서로는 한참 뒤쪽에 위치할 수 있다. 그러면 그 블록들은 실제 사용되지 못한 채 버퍼 상에서 밀려나는 일이 생길 수 있다. 하나의 블록을 캐싱하려면 다른 블록을 밀어내야 하는데, 이런 현상이 자주 발생한다면 버퍼 캐시 효율만 떨어뜨린다. 따라서 인덱스 스캔시에는 Single Block I/O 방식으로 읽는 게 효율적이다.
Index Range Scan 뿐 아니라 Index Full Scan 시에도 논리적인 순서에 따라 Single Block I/O 방식으로 읽는다. 인덱스의 논리적 순서를 무시하고 물리적인 순서에 따라 읽는 스캔 방식이 있는데, 이를 ‘Index Fast Full Scan’이라고 한다. 이때는 Table Full Scan과 마찬가지로 Multiblock I/O 방식을 사용하며, 한 번에 읽을 수 있는 최대 블록 수도 똑같이 db_file_multiblock_read_count 파라미터에 의해 결정된다.
서버 프로세스는 디스크에서 블록을 읽어야 하는 시점마다 I/O 서브시스템에 I/O 요청을 하고 대기 상태에 빠진다. 이 때 발생하는 대표적인 대기 이벤트로는 아래 두 가지를 들 수 있다.
- db file sequential read 대기 이벤트: Single Block I/O 방식으로 I/O를 요청할 때 발생
- db file scattered read 대기 이벤트: Multiblock I/O 방식으로 I/O를 요청할 때 발생
대량의 데이터를 Multiblock I/O 방식으로 읽을 때 Single Block I/O보다 성능상 유리한 것은 I/O Call 발생 횟수를 그만큼 줄여주기 때문이다.
Multiblock I/O 방식으로 읽더라도 익스텐트 범위를 넘지는 못한다고 앞에서 설명했다.
익스텐트 크기 때문에 예상보다 조금 더 많은 I/O Call이 발생하긴 했지만, Single Block I/O 때 보다 훨씬 적은 양의 I/O Call이 발생하는 것을 알 수 있었다.
Single Block I/O 방식으로 읽은 블록들은 LRU 리스트 상 MRU 쪽(end)60)으로 연결되므로 한 번 적재되면 버퍼 캐시에 비교적 오랫동안 남는다. 반면, Multiblock I/O 방식으로 읽은 블록들은 LRU 리스트에서 LRU 쪽(end)에 연결되므로 적재되고 얼마 지나지 않아 버퍼 캐시에서 밀려난다. 따라서 대량의 데이터를 Full Scan 했다고 해서 사용 빈도가 높은 블록들이 버퍼 캐시에서 모두 밀려날 것을 우려하지 않아도 된다.