<오라클 성능 고도화 원리와 해법2> Ch01-01 인덱스 구조
오라클 성능 고도화 원리와 해법2 - Ch01-01 인덱스 구조
(1) 범위 스캔
인덱스 구조를 설명하기에 앞서 “범위(Range)” 스캔의 의미를 살펴보자.
인덱스는 대용량 테이블에서 필요한 데이터만 빠르고 효율적으로 액세스할 목적으로 사용하는 오브젝트다. 테이블은 처음부터 끝까지 모든 레코드를 읽어야 완전한 결과 집합을 얻을 수 있지만, 인덱스는 키 컬럼 순으로 정렬돼 있기 때문에 특정 위치에서 스캔을 시작해 검색 조건에 일치하지 않는 값을 만나는 순간 멈출 수 있다. 이것이 범위 스캔(Range Scan)이 의미하는 바다.
테이블도 범위 스캔이 가능한 경우가 있다. 6절에서 설명할 IOT(Index-organized table)은 특정 컬럼 순으로 정렬 상태를 유지하며 값이 입력되므로 범위 스캔이 가능하다. 이를 제외한다면 일반적인 힙 구조 테이블(heap-organized table)에서 범위 스캔은 있을 수 없다. 정렬 상태가 유지되도록 사용자가 아무리 주의 깊게 데이터를 입력한들, 옵티마이저가 그것을 신뢰해 Table Range Scan 같은 실행 계획을 수립하진 않는다.
(2) 인덱스 기본 구조
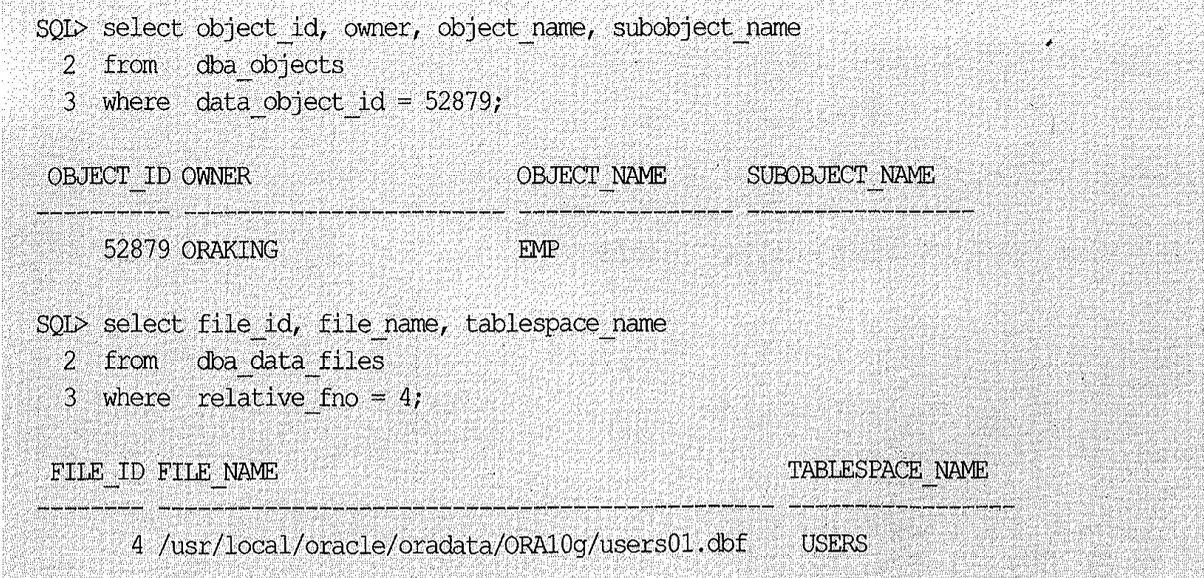
여러 종류의 인덱스 중에서 가장 일반적으로 사용되는 B*tree 인덱스 구조는 그림1-1과 같은 모습이다.
루트(Root)를 포함한 브랜치(Branch) 블록에 저장된 엔트리에는 하위 노드 블록을 찾아가기 위한 DBA(Data Block Address) 정보를 갖고, 최말단 리프(Leaf) 블록에는 인덱스 키 컬럼과 함께 해당 테이블 레코드를 찾아가기 위한 주소 정보(rowid)를 갖는다. 리프 블록은 항상 키 컬럼 순으로 정렬돼 있기 때문에 ‘범위 스캔’이 가능하다고 앞서 설명하였다. 키 값이 같을 때는 rowid 순으로 정렬된다는 사실도 기억하기 바란다.
| LeftMost Child |
|---|
| 브랜치 노드의 각 엔트리는 키 값과 하위 노드를 가리키는 블록 주소를 갖는다. 그런데 키 값을 갖지 않는 특별한 엔트리가 하나 있는데, 각 브랜치 노드의 첫 번째 엔트리가 그렇다. 이를 ‘lmc(LeftMost Child)’라고 부르기로 하자 (그림 1-1 참조). 다른 엔트리는 자신의 키 값과 같거나 큰 값을 담은 자식 노드 블록을 가리키는 반면, lmc는 명시적인 키 값을 갖지 않더라도 ‘키 값을 가진 첫 번째 엔트리보다 작은 값’의 의미를 갖는다. 따라서 그 브랜치 블록의 자식 노드 중 가장 왼쪽 끝에 위치한 블록을 가리킨다. 아래는 브랜치 블록에 대한 Dump 내용 중 일부를 표시한 것인데, lmc는 다른 엔트리와는 별도 장소에 저장되는 것을 알 수 있다. (인덱스 구조를 단순하게 표현하려고 그림 1-1에는 다른 엔트리와 같은 선상에 그렸다.)  |
값이 null인지 경우에 상관없이 모든 레코드를 인덱스에 저장하는 DBMS가 있는가 하면 오라클은 인덱스 구성 컬럼이 모두 null인 레코드는 저장하지 않는다. 그리고(인덱스 구성 컬럼이 모두 null인 경우를 제외하면) 인덱스와 테이블 레코드간에는 서로 1:1 대응 관계를 갖는다. 참고로, 뒤에서 다시 설명하겠지만 클러스터 인덱스(Cluster Index)는 1:M 관계를 갖는다.
브랜치에 저장된 레코드 개수는 바로 하위 레벨 블록 개수와 일치한다는 점도 기억할 필요가 있다.1) 그림 1-1에서 루트 블록의 레코드가 2개이므로 바로 아래쪽 브랜치 블록도 2개다. 그림에 다 표현하지 못했지만 브랜치 블록에 놓인 레코드 개수가 총 8개이므로 리프 블록도 8개일 것이다.
인덱스 리프 노드 상의 레코드와 테이블 레코드 간에는 1:1 관계라고 했는데, 값도 서로 일치한다. 따라서 테이블 레코드에서 값이 갱신되면 리프 노드 인덱스 키 값도 같이 갱신(delete & insert)된다.
반면, 리프 노드 상의 엔트리 키 값이 갱신되더라도 브랜치 노드까지 값이 바뀌지는 않는다. 브랜치 블록에 놓인 엔트리는 자신의 키 값과 같거나 큰 값을 담는 하위 노드 블록을 포인팅하는 것 으로서, 그 키 값은 자식 노드가 갖는 값의 범위를 나타내기 때문이다. 따라서 키 값이 하위 노드의 첫번째 레코드와 정확히 일치하지 않으며, 이는 그림 1-1에 잘 표현돼있다.
참고로, 브랜치 노드는 인덱스 분할(Split)에 의해 새로운 블록이 추가되거나 삭제(다른 브랜치의 자식 노드로 이동2)) 될 때만 갱신된다.
지금까지 설명한 내용을 요약하면 다음과 같다.
- 리프 노드 상의 인덱스 레코드와 테이블 레코드 간에는 1:1 관계
- 리프 노드 상의 키 값과 테이블 레코드 키 값은 서로 일치
- 브랜치 노드 상의 레코드 개수는 하위 레벨 블록 개수와 일치
- 브랜치 노드 상의 키 값은 하위 노드가 갖는 값의 범위를 의미
이런 인덱스 구조와 특징을 정확히 이해해야만 인덱스 탐색 과정도 쉽게 이해할 수 있다.
(3) 인덱스 탐색
인덱스 탐색 과정을 수직적 탐색과 수평적 탐색으로 구분해 설명할 수 있다. 수평적 탐색은 앞서 강조했던 범위 스캔(Range Scan)을 말하는 것이며, 리프 블록을 인덱스 레코드간 논리적 순서에 따라 좌에서 우, 또는 우에서 좌로 스캔하기 때문에 ‘수평적’ 이라고 표현한다.
수직적 탐색은 수평적 탐색을 위한 시작 지점을 찾는 과정이라고 할 수 있으며, 루트에서 리프 블록까지 아래쪽으로 진행하기 때문에 ‘수직적’ 이다.
그림 1-1에서 ‘CLARK’ 을 찾는 과정을 자세히 들여다보자
- 먼저 루트 블록을 스캔하면서 왼쪽 브랜치 블록(1800AFC)으로 갈지 오른쪽 브랜치 블록(18002E5)으로 갈지를 결정한다. ‘(lmc)’는 ‘KT’ 보다 작은 모든 값을 의미하고, ‘KI’는 ‘KI’ 보다 크거나 같은 모든 값을 의미하기 때문에 지금 찾고자 하는 ‘CLARK’을 위해서는 왼쪽 브랜치 블록으로 이동한다. (두 번째 엔트리가 ‘KI’보다 크거나 “같은” 값을 의미하지만, 현재 찾고 있는 값이 정확히 ‘KI’일 때는 왼쪽 브랜치로 이동한다. 그 이유는, 그림 1-2와 함께 잠시 후에 설명한다.)
- 찾아간 브랜치 블록을 스캔하면서 그 다음 찾아갈 인덱스 블록을 탐색한다. ‘CLARK’ 이 ‘BER’ 보다 크고 ‘FO’ 보다 작으므로 이번에는 두번째 레코드가 가리키는 블록 주소(18000A7)로 찾아간다.
- 이제 도착한 곳은 리프 블록이므로 거기서 ‘CLARK’ 을 찾거나 못 찾거나 둘 중 하나다. 찾으면 수평적 탐색 과정으로 넘어가고, 못찾으면 거기서 인덱스 탐색을 마친다. 여기서는 ‘CLARK’을 찾게 되므로 이어서 수평적 탐색, 즉 범위 스캔을 진행한다.
- 인덱스 리프 블록을 스캔하면서 값이 ‘CLARK’인지 확인한다.
- ‘CLARK’이면 거기서 얻은 rowid(00000B1C.O01E.0004)를 이용해 해당 테이블 레코드를 찾아가 필요한 다른 컬럼 값들을 읽는다. 만약 쿼리에서 인덱스 컬럼만 필요로 한다면 이 과정은 생략된다.
- 4번과 5번 과정을 반복하다가 검색 조건을 만족하지 못하는 레코드를 만나는 순간 멈춘다.
브랜치 블록 스캔
방금 설명한 인덱스 탐색 과정 중 1번과 2번에서 브랜치 블록을 스캔할 때는 뒤에서부터 스캔하는 방식이 유리하다. 왼쪽 브랜치 블록(1800AFC)을 예로 들면, 뒤에서부터 스캔할 때는 ‘CLARK’보다 작은 첫 번째 레코드(‘BER’)를 만나는 순간 바로 하위 블록으로 내려가면 되지만, 앞에서부터 스캔할 때는 ‘CLARK’보다 크거나 같은 첫 번째 레코드(‘FO’)를 만나는 순간 멈춰서 한 칸 뒤로 이동해야하기 때문이다.
하지만 오라클이 실제로 뒤쪽부터 스캔하는지는 필자도 알 수가 없다. 어쩌면 값을 거꾸로 입력해두고서 앞쪽부터 스캔할지도 모를 일이지만, 앞으로 인덱스 스캔 과정을 설명할 때는 뒤쪽부터 스캔한다고 가정하기로 하자.
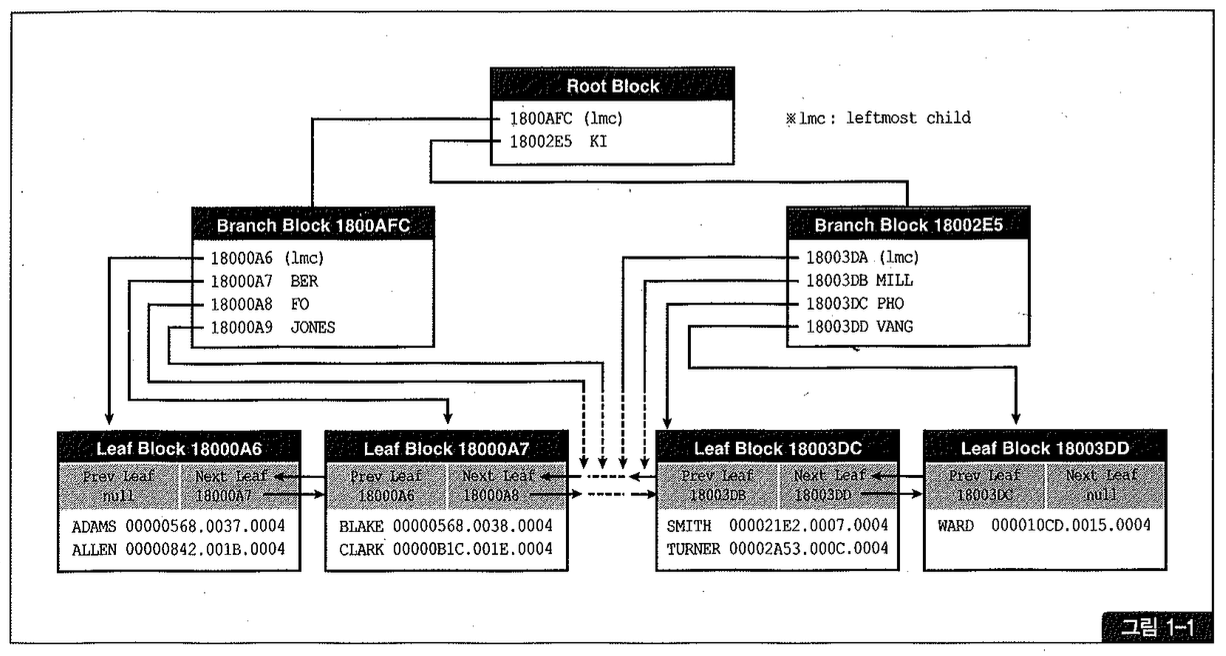
브랜치 블록을 따라 수직적 탐색을 진행할 때는 찾고자 하는 값보다 키 값이 작은 엔트리를 따라 내려간다는 사실도 기억할 필요가 있다. 그림 1-2처럼 중복 값이 많은 인덱스를 탐색해 나가다보면 그 이유를 자연스럽게 이해할 수 있다.
그림 1-2에서 인덱스를 통해 값이 3인 레코드를 찾는다고 하자. 그러면 ①번 루트 블록에서 lmc가 가리키는 ②번 브랜치 노드로 따라 내려가야 한다. 만약 같은 값인 3을 따라 ③번 브랜치로 내려가면 ②번 브랜치 끝에 놓인 3을 놓치게 되기 때문이다.
이제 도착한 ②번 브랜치에서 맨 뒤쪽 3부터 거꾸로 스캔하다가 2를 만나는 순간 리프 블록으로 내려간다. 거기서 키 값이 3인 첫 번째 레코드를 찾아 오른쪽으로 리프 블록을 스캔해나가면 조회 조건을 만족하는 값을 모두 찾을 수 있다.
결합 인덱스 구조와 탐색
결합(Composite, Concatenated) 인덱스 구조도 간단히 살펴보자. 그림 1-3은 emp 테이블에 [deptno+sal] 컬럼 순으로 생성한 결합 인덱스를 도식화한 것이다.
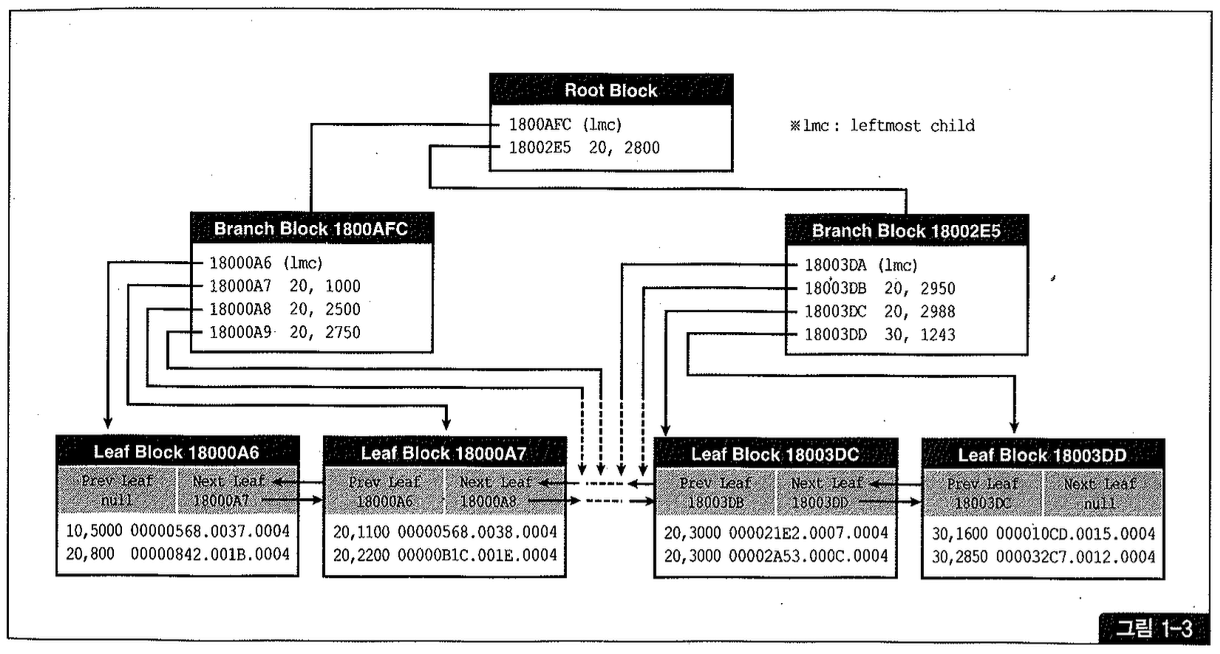
‘deptno=20 and sal >= 2000’ 조건으로 쿼리할 때 deptno가 20인 첫 번째 레코드(그림 1-3에서 첫 번째 리프 블록 두 번째 레코드)가 스캔 시작점이라고 생각하기 쉽다. 하지만 그림 1-3에서 두 번째 리프 블록, 그 중에서도 두 번째 레코드부터 스캔이 시작된다는 사실을 반드시 기억하기 바란다. 7절에서 좀 더 자세한 원리를 설명하겠지만 이는 수직적 탐색 과정에서 deptno 뿐만 아니라 sal 값에 대한 필터링도 같이 이루어지기 때문이다. 그리고 마지막 블록 첫 번째 레코드에서 스캔을 멈추게 될 것이다.
(4) ROWID 포맷
rowid에는 데이터 파일 번호, 블록 번호, 로우 번호 같은 테이블 레코드의 물리적 위치 정보를 포함한다. 테이블 레코드를 찾아가는 데 필요한 주소 정보이므로 테이블 자체에 저장되는 것이 아니라 인덱스에 저장된다. 필요하면 rowid를 출력해볼 수 있지만 그 값이 테이블에 실제 저장되어 있지는 않다. 즉, pseudo 컬럼이다.
그럼 인덱스를 거치지 않는 쿼리에서 rowid를 요구할 때면 어떻게 그 값을 출력할까? 오브젝트 및 데이터 파일 번호, 그리고 그 파일 내에서의 상대적인 블록 번호가 데이터 블록 헤더에 저장돼 있기 때문에 전혀 어렵지 않다. 레코드를 읽는 시점에, 현재 도달한 블록 헤더와 각 레코드에 할당된 슬롯 번호를 이용해 충분히 가공해낼 수 있는 것이다.
그러면 인덱스에 저장되는 rowid는 얼마만큼의 공간을 차지할까? 오라클 7 버전까지 rowid는 내부적으로 6바이트 크기를 차지하며, 파일 번호, 블록 번호, 로우 번호로 구성된다.
그러다가 오라클 8부터는 rowid 크기를 10바이트로 증가시켰다. 데이터베이스에 저장해야 할 데이터량이 점차 증가해 더 많은 데이터 파일을 관리할 필요가 생겼고, 파티션 같은 기능을 지원하기 위해 오브젝트 번호까지 저장할 필요가 생겼기 때문이다. rowid를 10 바이트로 늘림으로써 오라클은 tera-byte를 넘어 peta-byte 단위의 데이터를 저장할 수 있게 되었다.
하지만, 항상 10바이트로 저장하는 것은 아니어서 테이블과 인덱스 유형에 따라 여전히 6바이트를 사용하기도 한다. 예를 들어, 아래 경우는 rowid가 기존처럼 6바이트 공간을 차지한다.
- 파티션되지 않은 일반 테이블에 생성한 인덱스
- 파티션된 테이블에 생성한 로컬 파티션(Local Partitioned) 인덱스
반면, 아래 경우는 10바이트를 차지하며, 이런 사실은 인덱스 블록 덤프를 통해 쉽게 확인할 수 있다.
- 파티션 테이블에 생성한 글로벌 파티션(Global Partitioned) 인덱스
- 파티션 테이블에 생성한 비파티션(Non Partitioned) 인덱스
오라클 8부터 내부적으로 rowid 사이즈가 달라지면서 외부로 출력되는 rowid 포맷도 달라졌고, 이렇게 달라진 새로운 rowid 포맷을 ‘확장(Extended) rowid 포맷’이라고 부른다. 반면, 이전에 사용되던 포맷은 ‘제한(Restricted) rowid 포맷’이라고 부르게 되었다. 그리고 내부적으로 몇 바이트로 저장되든 애플리케이션에서 출력해 보면 둘 다 18자리인데, 구성 내용은 조금다르다.
오라클 7 버전까지 사용하던 ‘제한 rowid 포맷’ 은 아래 3개의 구성 요소로 이루어진다.
- 데이터 파일 번호(4자리) 로우가 속한 데이터 파일 번호로서, 데이터베이스 내에서 유일한 값임
- 블록 번호(8자리) 해당 로우가 저장된 데이터 블록 번호이며, (테이블 스페이스가 아니라) 데이터 파일 내에서의 상대적 번호임
- 로우 번호(4자리) 블록 내에서 각 로우에 붙여진 일련번호로서, 0부터 시작됨
각 구성 요소의 자리수를 더하면 16자리지만 구분자(delimiter)로 사용하는 ‘.(dot)’ 기호를 포함해 18자리 문자열로 출력되며, 순서는 블록.로우.데이터파일순이다.

오라클 8 버전부터 사용되기 시작한 ‘확장 rowid 포맷’ 은 제한 rowid 포맷에 데이터 오브젝트 번호를 더해 4개의 구성 요소로 이루어진다.
- 데이터 오브젝트 번호(6자리) 데이터베이스 세그먼트를 식별하기 위해 사용되는 데이터 오브젝트 번호
- 데이터 파일 번호(3자리) 로우가 속한 데이터 파일 번호(테이블 스페이스 내에서의 상대적인 파일 번호)
- 블록 번호(6자리) 해당 로우가 저장된 데이터 블록 번호이며, (테이블 스페이스가 아니라) 데이터 파일 내에서의 상대적 번호임
- 로우 번호(3자리) 블록 내에서 각 로우에 붙여진 일련번호로서, 0부터 시작됨
애플리케이션에 출력할 때는 별도의 구분자 없이 연속된 18자리 문자열 포맷을 사용하며, 순서는 (데이터 오브젝트)(데이터 파일)(블록)(로우) 순이다. 오라클 8 이상에서 여전히 6바이트 rowid를 사용할 수 있다고 했지만, 출력되는 포맷은 10바이트 rowid의 그것과 같다.

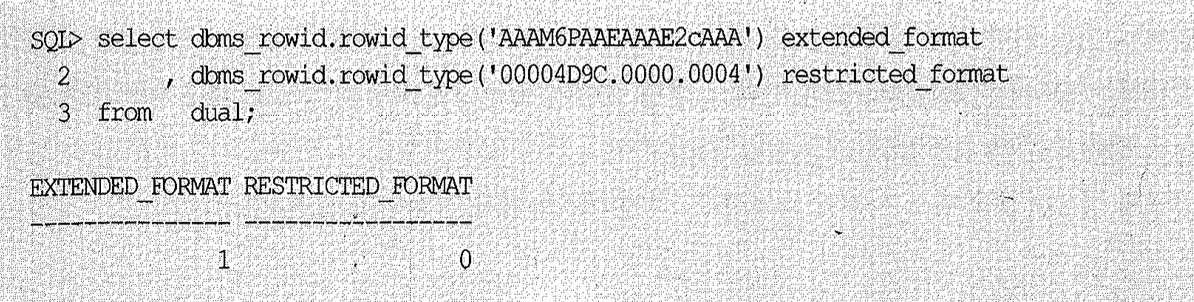
출력된 확장 rowid를 자릿수만큼 잘라서 디코딩(Decoding)하면 각 구성 요소에 대한 정보를 얻어낼 수 있지만, 아래와 같이 dbms_rowid 패키지를 사용하면 훨씬 쉽다. 확장 rowid 포맷을 제한 rowid 포맷으로 바꿔서 표현해 주는 기능도 있다(스크립트 ch1_01.txt 참조).


출력된 rowid 포맷이 둘 중 어느 타입에 속하는지 눈으로도 어렵지 않게 확인할 수 있지만 rowid_type 함수에서 리턴된 값(0 또는 1)을 이용해 구분할 수 있다.
아래는 rowid 문자열에서 추출한 데이터 오브젝트 번호와 데이터 파일 번호를 이용해 해당 오브젝트와 데이터 파일에 대한 정보를 조회하는 방법을 예시한 것이다.