<오라클 성능 고도화 원리와 해법2> Ch01-02 인덱스 기본 원리
오라클 성능 고도화 원리와 해법2 - Ch01-02 인덱스 기본 원리
B*Tree 인덱스를 정상적으로 사용하려면 범위 스캔 시작 지점을 찾기 위해 루트 블록부터 리프 블록까지의 수직적 탐색 과정을 거쳐야 한다. 만약 인덱스 선두 컬럼이 조건절에 사용되지 않으면 범위 스캔을 위한 시작점을 찾을 수 없어 옵티마이저는 인덱스 전체를 스캔하거나 테이블 전체를 스캔하는 방식을 선택한다. 또한 인덱스 선두 컬럼이 조건에 사용되더라도 인덱스를 사용 못 하거나 범위 스캔이 불가능한 경우가 있다.
언제 정상적인 인덱스 사용이 가능하고, 언제 불가능한지 지금부터 살펴보자.
(1) 인덱스 사용이 불가능하거나 범위 스캔이 불가능한 경우
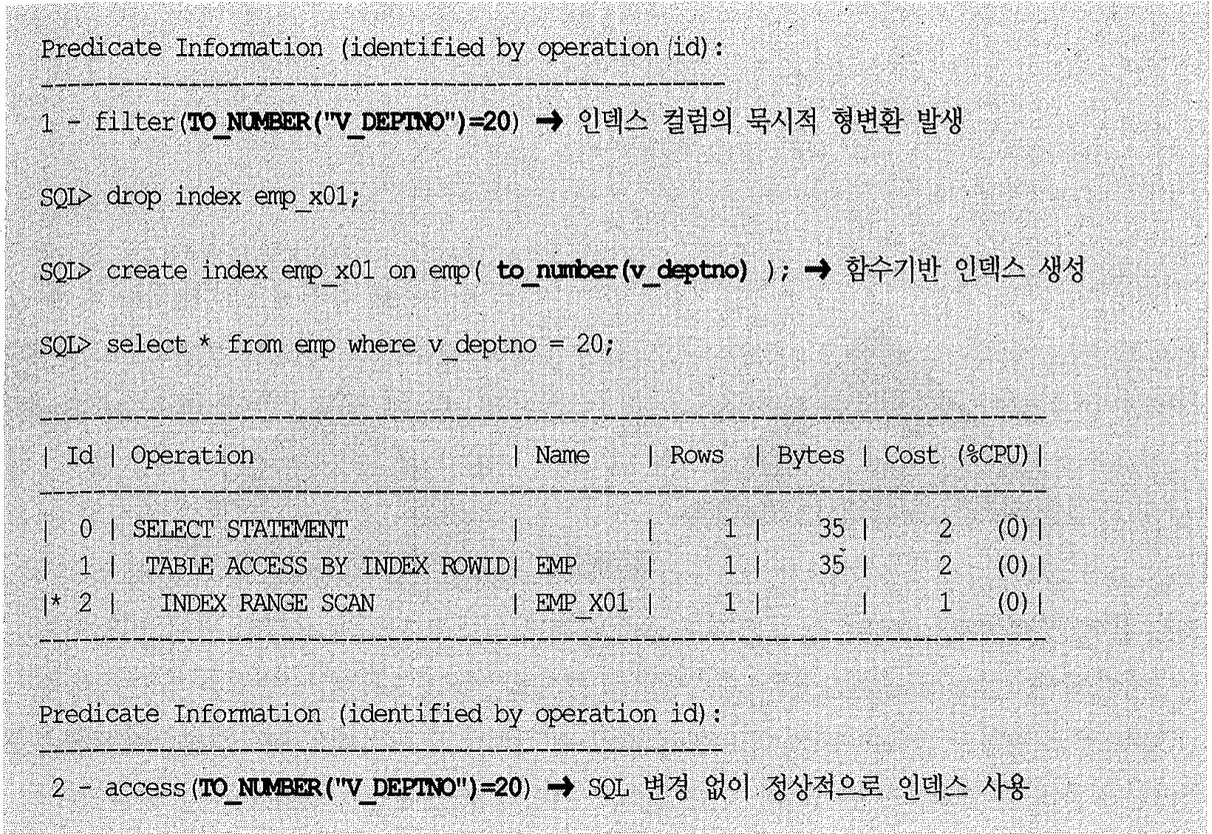
아래와 같이 인덱스 컬럼을 조건절에서 가공하면(FBI 인덱스를 정의하지 않는 한) 정상적으로 인덱스를 사용할 수 없다.

또한 아래처럼 부정형 비교를 사용해도 마찬가지다.

is not null 조건도 부정형 비교에 해당하므로 정상적인 인덱스 사용은 어렵다.

위 세 경우 모두 정상적인 인덱스 범위 스캔이 불가능할 따름이지 인덱스 사용 자체가 불가능하지는 않다. 다시 말해, Index Full Scan은 가능하다.
예를 들어, 맨 마지막 SOL의 경우 ‘부서코드’에 단일 컬럼 인덱스가 존재한다면 그 인덱스 전체를 스캔하면서 얻은 레코드는 모두 ‘부서코드 is not null’ 조건을 만족한다. 1절에서 설명했듯이 오라클은 단일 컬럼 인덱스에 null 값은 저장하지 않기 때문이다. 결합 인덱스일 때는 인덱스 구성 컬럼 중 하나라도 값이 null이 아닌 레코드는 인덱스에 포함되지만 필터링을 통해 ‘부서코드 is not null’ 조건에 해당하는 레코드를 찾을 수 있다.
인덱스 사용이 불가능한 경우도 있는데, 아래와 같이 is null 조건만으로 검색할 때가 그렇다. 단일 컬럼 인덱스는 물론이고 결합 인덱스더라도 구성 컬럼이 모두 null이라면 인덱스만 뒤져서는 완전한 결과 집합을 얻을 수 없기 때문이다.

예외적이긴 하지만 is null 조건에도 옵티마이저가 인덱스를 사용하는 경우가 있다. 아래 예를 보자. (아래는 9i에서 수집한 실행 계획이고, 10g에서는 Index Full Scan이 나타난다.)
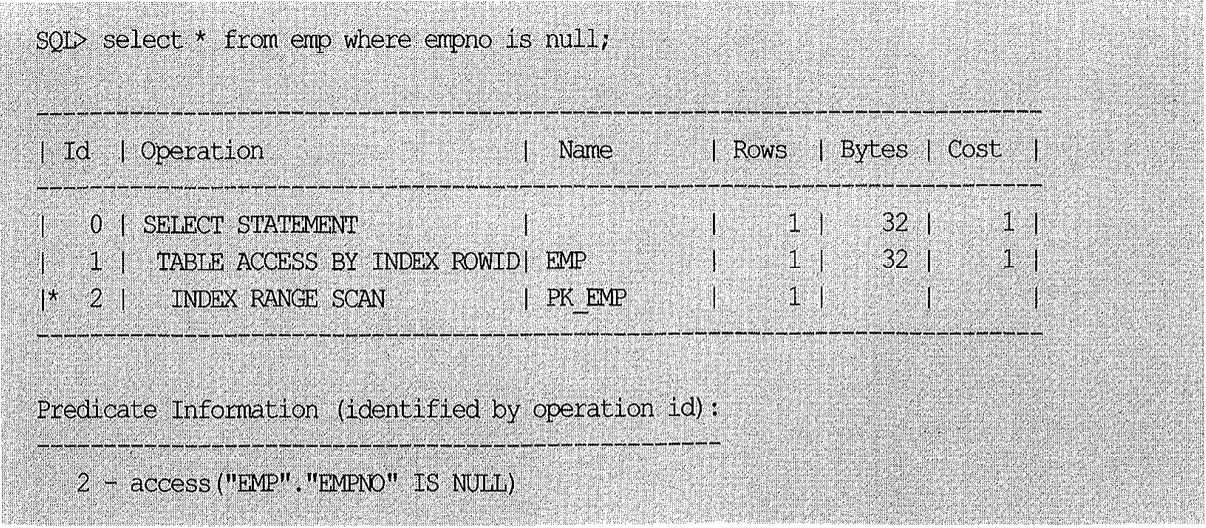
empno is null 조건만으로 검색했는데, 인덱스 액세스 조건으로 사용되었고 정상적인 Index Range Scan(또는 Index Full Scan)이 나타났다. 어떻게 된 일일까? 아래 Desc 명령을 통해 해답을 얻을 수 있다.

empno 컬럼에 not null 제약이 있는 것에 주목하자. 테이블 전체를 스캔해도 empno is null 조건을 만족하는 레코드가 하나도 없음을 옵티마이저는 이미 알고 있기 때문에 인덱스 스캔을 통해 공집합을 반환하는 방식을 취한 것이다.
값이 null인 레코드는 인덱스에 포함되지 않으므로 이를 찾으려고 인덱스를 스캔하는 데에는 논리적인 모순이 있지만, Table Full Scan을 피하기 위한 일종의 트릭이라고 이해하면 된다. (사실은 not null 컬럼을 is null 조건으로 검색하는 사용자 쿼리 자체가 이미 모순이다.)
is null 조건을 사용하더라도 다른 인덱스 구성 컬럼에 is null 이외의 조건식이 하나라도 있으면 아래와 같이 Index Range Scan이 가능하다. (물론 인덱스 선두 컬럼이 조건에 누락되지 않아야 한다.) 인덱스 구성 컬럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장되기 때문이다. 참고로, 오라클은 null 값을 맨 뒤에 저장한다.
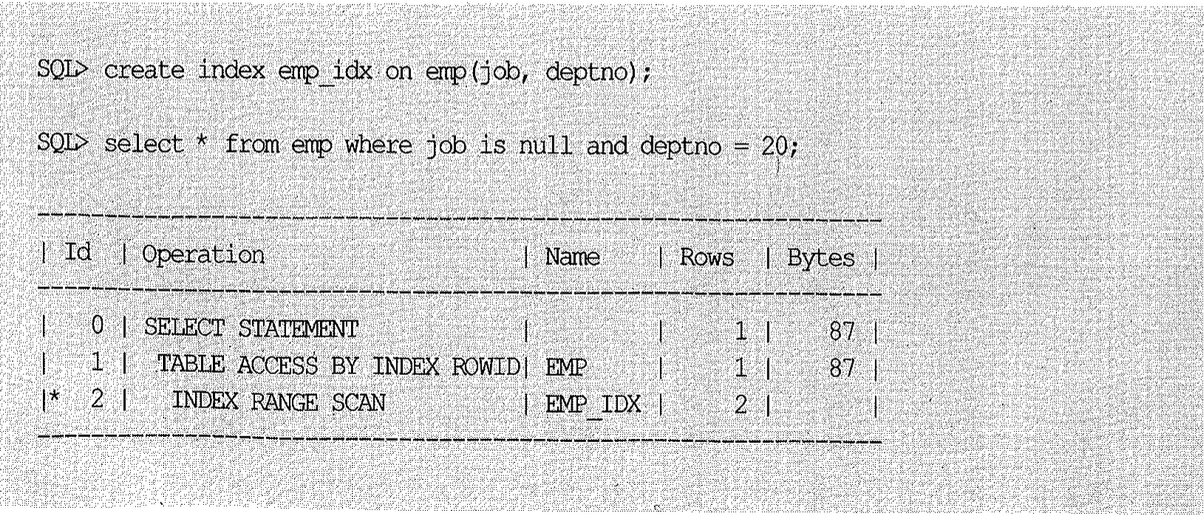

만약 다른 인덱스 구성 컬럼 중 어느 하나(위 예시에서는 deptno)에 Not Null 제약이 설정돼 있다면? 그 컬럼에 대한 조건식 유무에 상관없이 항상 Index Range Scan이 가능하다.
(2) 인덱스 컬럼의 가공
인덱스 컬럼을 가공하면 정상적인 Index Range Scan이 불가능해진다고 했다. 가장 흔한 인덱스 결림 가공 사례는 아래와 같고, 오른쪽 컬럼은 각 사례에 대한 튜닝 방안이다3).
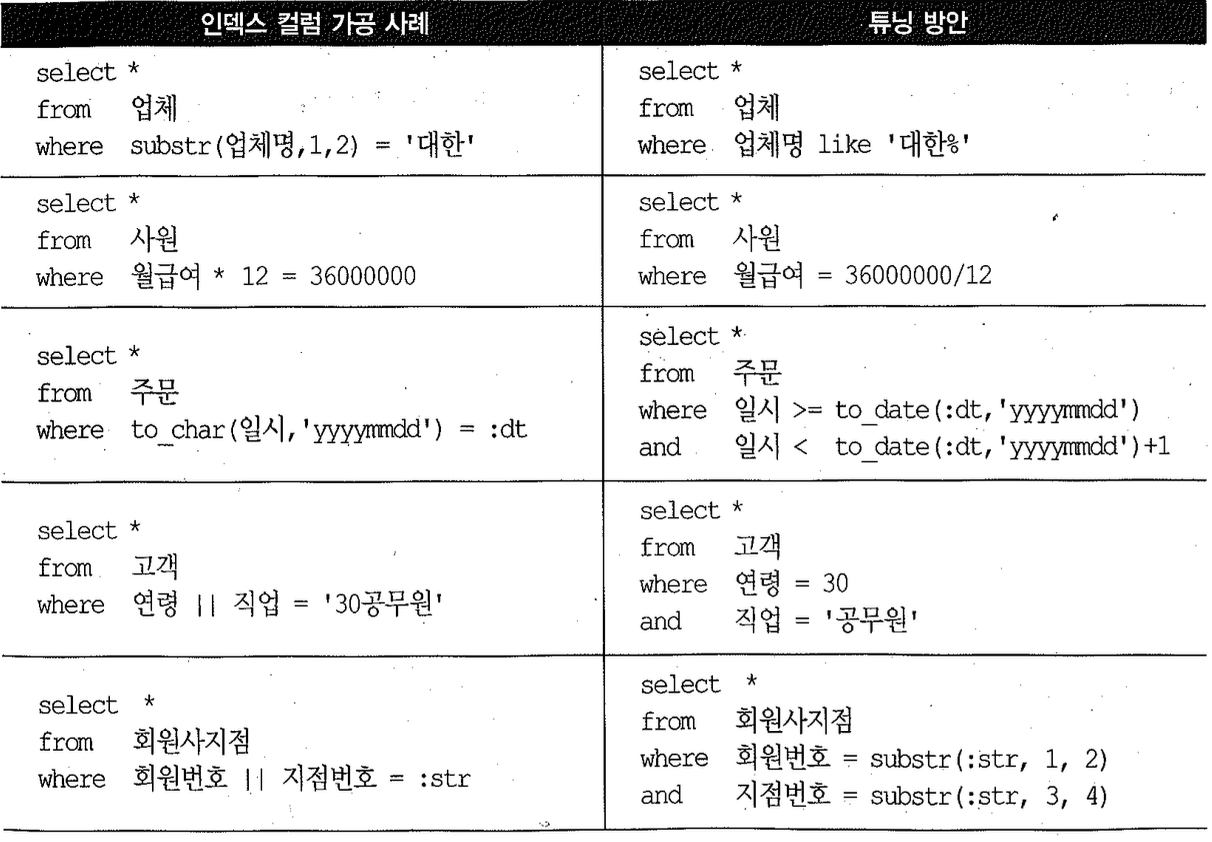
- 대용량 데이터베이스 솔루션1 (이화식 저, 엔코아 컨설팅, 1996) 참조
아래 SQL도 인덱스 컬럼을 가공한 형태인데, 쿼리가 원하는 결과는 주문 수량이 100보다 크거나 같은 경우이므로 주문 수량이 null인 경우는 원래 결과 집합에 포함되지 않는다.

그럼에도, 주문 수량이 null일 때 0으로 치환하도록 처리하고 있다. 결과 집합은 틀리지 않겠지만, 의미없이 사용된 nvl 함수 때문에 인덱스 사용이 불가능하게 돼 버렸다. 아래와 같이 바꾸면 인덱스를 정상적으로 사용하면서 같은 결과 집합을 얻을 수 있다.

아래 경우는 어떤가? 주문 수량이 null일 때 0으로 치환해서 결과 집합에 포함되도록 한 것을 보면 주문 수량이 100보다 작거나 null인 주문건을 찾고자 하는 SQL임에 틀림없다.

튜닝 시 이런 쿼리를 만나면 우선 주문 수량이 not null 컬럼은 아닌지 확인할 필요가 있다. not null 컬럼이면 nvl 함수를 제거해 간단히 문제를 해결할 수 있지만, 아닐 때는 Table Full Scan이 불가피하다. 조건을 아래와 같이 풀어쓰더라도 마찬가지다.

위 조건에 해당하는 건수가 아주 많다면 Table Full Scan이 오히려 유리한 경우이므로 고민할 필요가 없겠지만 얼마 되지 않는다면 아래와 같이 함수 기반 인덱스(FBI) 생성을 고려할 수 있다.

튜닝 사례 1
인덱스 컬럼을 가공한 것이 원인이 돼 성능 이슈가 발생했던 실제 사례를 소개하려고 한다. 첫 번째 사례의 인덱스 구성은 다음과 같다.

아래는 튜닝 전 쿼리다

지수 구분 코드가 ‘1’이면서 지수 업종 코드가 ‘001’이거나, 지수 구분 코드가 ‘2’이면서 지수 업종 코드가 ‘003’ 인 레코드를 찾는 쿼리다. 그런데 PK 인덱스 선두 컬럼을 가공하는 바람에 이 인덱스를 사용할 수 없게 되어 거래 일자만으로 구성된 X01 인덱스를 사용했거나 Full Table Scan으로 처리됐을 것이다.
쿼리를 아래와 같이 바꿔주면 PK 인덱스를 정상적으로 사용할 수 있는데도, 개발자는 아마 IN-List를 이런 식으로 기술할 수 있다는 사실을 몰랐던 거 같다.

튜닝 사례 2
두 번째 사례의 인덱스 구성은 다음과 같다.

아래는 튜닝 전 쿼리와 SQL 트레이스에서 추출한 Row Source Operation이다.

인덱스 컬럼을 가공하는 바람에 Table Full Scan 으로 처리된 것을 볼 수 있다.
위 decode 문을 분석해 논리적으로 동일한 결과를 리턴하도록 아래와 같이 조건 재구성해 주면 정상적인 인덱스 스캔이 가능해진다. (정정대상접수번호=Ipad(‘ ‘,14) 조건에 해당하는 데이터는 많지 않다. 그리고 금감원 접수번호가 null 허용 컬럼이면 nvl 처리가 필요하겠지만 not null 컬럼이다.

(3) 묵시적 형변환
여기서 퀴즈를 하나 풀어보자.


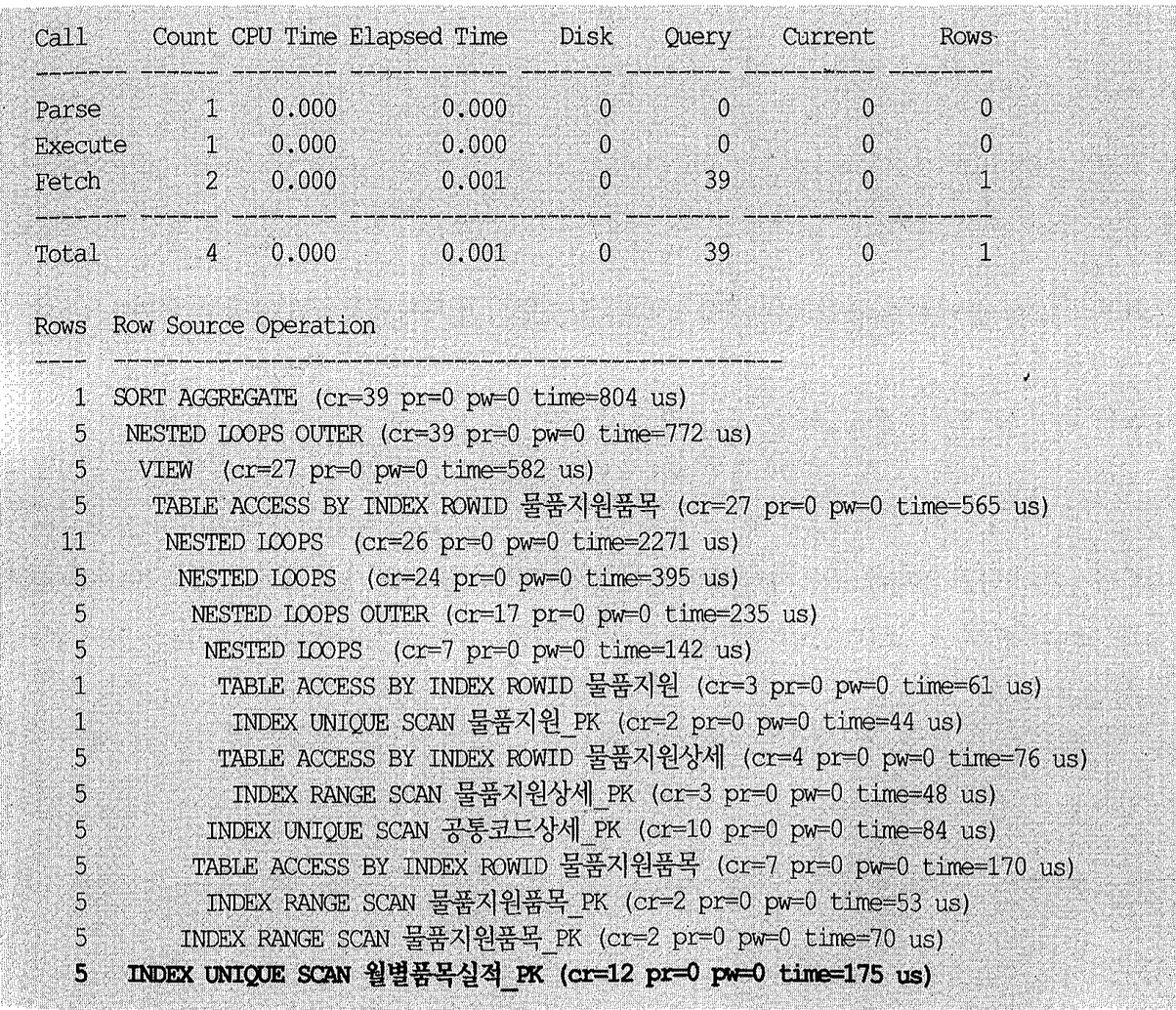
위 Row Source Operation 맨 하단을 보면 월별품목실적_PK 인덱스를 Full Scan하고 있고, I/O 대부분이 거기서 발생했음을 알 수 있다. 여기에 해당하는 부분이 쿼리 맨 아래쪽 세 개 조인 조건인데, 물품지원품목코드, 영업조직, 대상연월 모두 ‘=’ 조건인 데다가 이 세 컬럼으로 구성된 인덱스가 아래와 같이 컬럼 순서만 다를 뿐 두 개나 있다.

그럼에도 인덱스를 정상적으로 Range Scan하지 못하고 Index Full Scan으로 처리한 이유는 무엇일까? 튜닝된 결과를 보기 전에 독자 스스로 고민해 보는 시간을 갖기 바란다. 참고로, 모든 조인 컬럼의 데이터 타입은 varchar2이다.
자! 이제 이유를 설명해보자. 아래 조인 조건에 해답이 있다면 쉽게 이해할 수 있겠는가?

2장 조인 원리에서 다시 자세히 설명하겠지만, NL Outer 조인은 조인 순서가 고정돼 항상 Outer 테이블이 먼저 드라이빙된다. 위 쿼리는 따라서 인라인 뷰로 처리한 x쪽 집합이 먼저 읽히고 y쪽 월별품목실적 조인 컬럼에 값이 제공하게 된다.
그런데 위 조인 절에서 대상 연월, 파트너 지원 요청 일자 모두 varchar2 컬럼이라고 했다. varchar2 컬럼에 숫자값을 더하거나 빼는 연산을 가하면 내부적으로 숫자형으로 형변환이 일어난다. 즉, x 쪽 파트너 지원 요청 일자 컬럼에서 앞 6자리 연월을 취하고 1을 차감하는 과정에서 숫자 형으로 묵시적 형변환이 일어나는 것이다.
그러고나서 이번에는 y쪽 대상 연월 컬럼이 숫자형으로 형변환된다. 왜냐하면, 숫자형과 문자 형이 비교될 때는 숫자형이 우선시되기 때문이다. 대부분 아래와 같은 형태로 변환이 이루어 지고, 결과적으로 인덱스 컬럼을 가공한 셈이 된다.

튜닝을 위해 조건을 아래와 같이 바꾸고 다시 실행해보았다.

조건절을 약간 변경했을 뿐인데 아래에서 보듯 결과는 천양지차다.
쿼리 옵티마이저에 의해 일어나는 내부적인 형변환 원리를 이해하고 조인 컬럼의 데이터 타입을 일일이 따져보지 않으면 문제점을 쉽게 발견하기 어려운 튜닝 사례다. (사실 위 SQL은 튜닝 과정에서 성능 문제뿐 아니라 프로그램 버그까지 찾아준 사례인데, 문제가 된 원래의 조건에서 파트너 지원 요청 일자가 2008년 1월에 속한 일자이면 2007년 12월이 아닌 2008년 00월을 반환하기 때문이다.)
묵시적 형 변환 사용 시 주의 사항
묵시적 형변환은 방금 본 것처럼 인덱스 사용을 막을 수 있어 주로 성능 측면에서 언급된다. 하지만 쿼리 수행 도중 에러가 발생하거나 결과가 틀릴 수 있다는 측면이 더 중요할 수도 있다.
예를 들어 아래와 같이 숫자형 컬럼(n_col)과 문자형 컬럼(v_col)을 비교하면 문자형 컬럼이 숫자형으로 변환되는데, 만약 문자형 컬럼에 숫자로 변환할 수 없는 문자열이 들어있으면 쿼리 수행 도중 에러가 발생한다.

참고로, like로 비교할 때만큼은 아래와 같이 숫자형이 문자형으로 변환되므로 위와 같은 에러는 발생하지 않는다.

에러가 발생하지 않더라도 묵시적 형변환 때문에 결과 오류가 생기는 사례도 있다. 아래와 같이 scott.emp 테이블에서 직원들 급여 수준을 조회해보았다.

가장 적게 받는 직원 급여가 800이고, 가장 많이 받는 직원 급여는 5,000인 것으로 조회되었다. 가장 많이 받는 직원은 당연히 ‘PRESIDENT’ 였을 것으로 예상되어 이를 제외하고 가장 많이 받는 직원의 급여(imax_sal2)도 함께 조회한 것을 볼 수 있다. 그런데 평균 급여인 2,073에도 못미치는 950인 것으로 나타났다.
뭔가 이상하다 싶어 아래와 같이 레코드 단위로 조회해보니 ‘PRESIDENT’를 제외한 두 명의 ‘ANALYST’ 급여가 3,000으로서 가장 높았다.

앞서 집계 쿼리에서 왜 잘못된 수치가 반환된 것일까? 오라클이 decode 함수를 처리할 때 내부적으로 사용하는 묵시적 형변환 규칙 때문이다.
decode(a, b, c, d)를 처리할 때 ‘a = b’이면 c를 반환하고, 아니면 d를 반환한다. 이때 출력된 값의 데이터 타입은 세 번째 인자 c에 의해 결정된다. 따라서 c가 문자형이고 d가 숫자형이면 내부적으로 d가 문자형으로 변환된다.
decode 함수가 가진 또 하나의 규칙은 c 인자가 null 값이면 varchar2로 취급한다는 사실이다. (이외에도 다양한 규칙이 존재하므로 매뉴얼을 통해 decode 함수에 대한 설명을 반드시 숙지하기 바란다.)
이제 앞선 쿼리 결과가 잘못된 원인을 이해하겠는가? 세 번째 인자가 null 값이므로 네 번째 인자 sal을 문자열로 변환했을 때의 가장 큰 값(950)을 출력했던 것이다. 아래와 같이 데이터 타입을 명시적으로 일치시켜주면 위와 같은 오류를 피할 수 있다.


묵시적 형변환은 사용자가 코딩을 쉽게 하도록 도울 목적으로 대부분 DBMS가 제공하는 기능4)이지만 위와 같은 부작용을 피하려면 가급적 이 기능에 의존하지 말 것을 당부한다.
- 타입 체크를 엄격히 하는 DBMS도 있다. 예를 들어, Sybase IQ는 비교되는 값 또는 컬럼 간에 데이터 타입이 일치하지 않으면 컴파일 시점에 에러를 발생시킨다.
문자형과 숫자형이 만나면 숫자형으로, 문자형과 날짜형이 만나면 날짜형으로 변하는 등 데이터 타입간 우선순위 규칙이 존재하지만 이를 굳이 외울 필요도 없다. 쿼리 성능뿐만 아니라 올바른 결과 집합을 얻기 위해서라도 명시적으로 변환 함수를 사용하는 게 바람직하기 때문이다. 성능을 위해서라면 인덱스 컬럼과 비교되는 반대쪽을 인덱스 컬럼 데이터 타입에 맞춰주면 된다.
함수기반 인덱스(FBI) 활용
만약 개발 완료 시점에 성능 이슈가 발생했는데 원인이 묵시적 형변환에 있었고 프로그램을 일일이 바꿀 만큼 시간적 여유가 없다면 아래처럼 함수기반 인덱스(FB)를 이용해 급한 불을 끌 수 있다. 하지만 그다지 권장할 만한 해법은 못되므로 추후 일정을 잡아 반드시 개선해야 할 일이다. (스크립트 ch1_02.txt 참조).