<오라클 성능 고도화 원리와 해법2> Ch01-05 테이블 Random 액세스 최소화 튜닝
오라클 성능 고도화 원리와 해법2 - Ch01-05 테이블 Random 액세스 최소화 튜닝
4절에서 테이블 랜덤 액세스에 의한 부하 원리에 대해 자세히 설명하였다. 본절에서는 테이블 랜덤 액세스 최소화를 위한 튜닝 방안과 사례를 소개한다.
(1) 인덱스 컬럼 추가
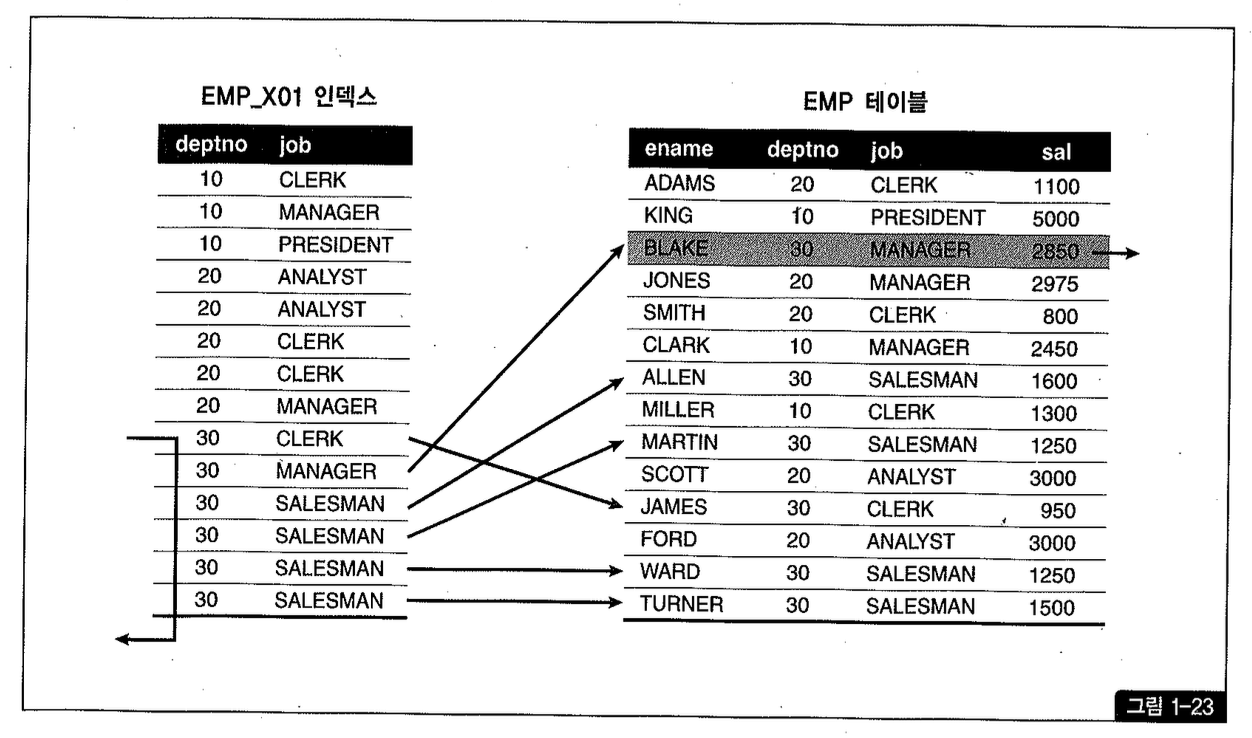
emp 테이블에 현재 PK 이외에 [deptno + job] 순으로 구성된 emp_X01 인덱스 하나만 있는 상태에서 아래 쿼리를 수행하려고 한다.


그림1-23을 보면 위 조건을 만족하는 사원이 단 한 명뿐인데, 이를 찾기 위해 테이블 액세스는 6번 발생하였다.
인덱스 구성을 [deptno + sal] 순으로 바꿔주면 좋겠지만 실운영 환경에서는 인덱스 구성을 함부로 바꾸기가 쉽지 않다. 기존 인덱스를 사용하는 아래와 같은 SQL이 있을 수 있기 때문이다.
할 수 없이 인덱스를 새로 만들어야겠지만 이런 식으로 인덱스를 추가해나가다 보면 테이블마다 인덱스가 수십개씩 달려 배보다 배꼽이 더 커지게 된다. 인덱스 관리 비용이 증가함은 물론 DML 부하에 따른 트랜잭션 성능 저하가 생길 수 있음을 쉽게 예상할 수 있다.
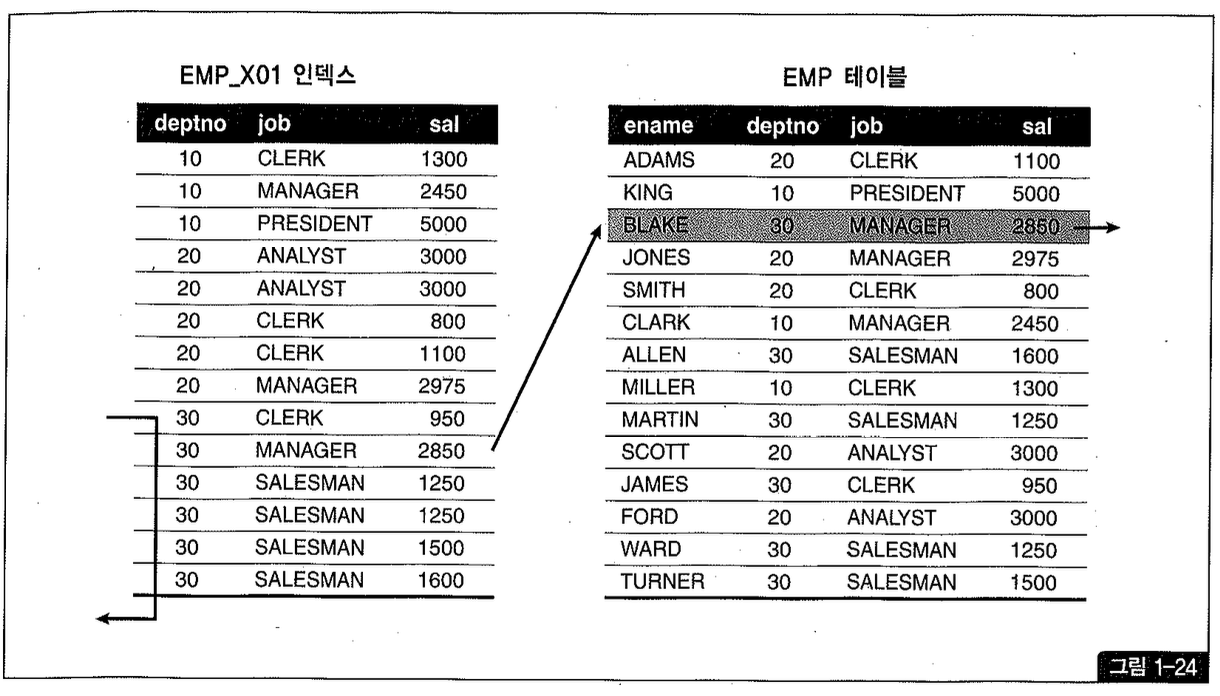
이럴 때, 그림1-24처럼 기존 인덱스에 sal 컬럼을 추가하는 것만으로 큰 효과를 거둘 수 있다. 인덱스 스캔량은 줄지 않지만 테이블 랜덤 액세스 횟수를 줄여주기 때문이다.
(2) PK 인덱스에 컬럼 추가
단일 테이블을 PK로 액세스할 때는 단 한 건만 조회하는 것이므로 테이블 랜덤 액세스도 단 1회 발생한다. 하지만 NI, 조인할 때 Inner 쪽(=right side)에서 액세스될 때는 랜덤 액세스 부하가 만치 않다. 특히 Outer 테이블에서 Inner 테이블 쪽으로 조인 액세스가 많은 상황에서 Inner 쪽 필터 조건에 의해 버려지는 레코드가 많다면 그 비효율은 매우 심각한 것일 수 있다.
아래 쿼리는 emp를 기준으로 NI를, 조인하고, 조인에 성공한 14건 중 10oc = NEW YORK 인 레코드만 취하므로 최종 결과 집합은 3건뿐이다.
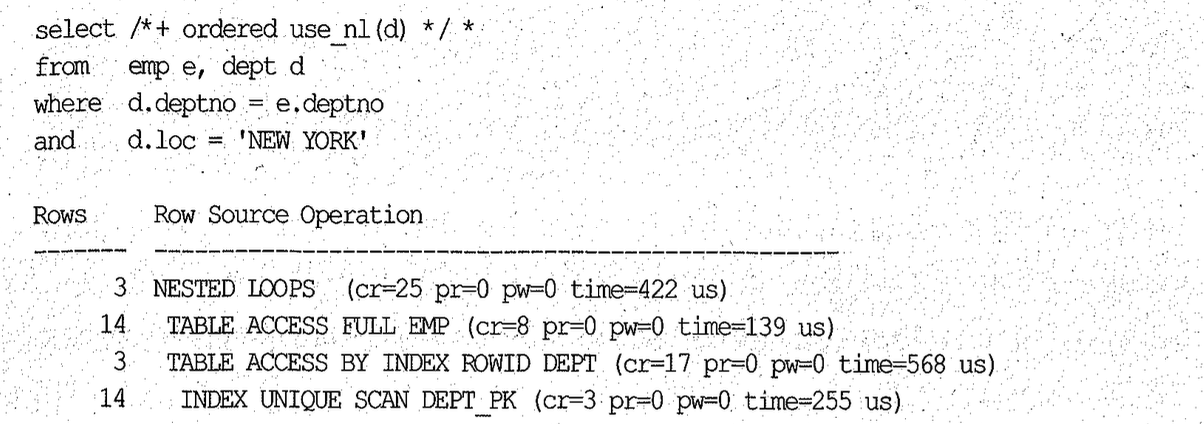
dept_pk 인덱스에 10c 컬럼을 추가하면 불필요한 11번의 랜덤 액세스를 없앨 수 있지만 PK 인덱스에는 컬럼을 추가할 수가 없다. 그러다 보니 [PK 컬럼 + 필터 조건 컬럼] 형태의 새로운 Non-Unique 인덱스를 추가하는 경우가 종종 있다. 그럴 때 Non-Unique 인덱스를 이용해 PK 제약을 설정한다면 인덱스 개수를 줄일 수 있다.
PK 제약에는 중복값 확인을 위한 인덱스가 반드시 필요하다. 인덱스가 없다면 값이 입력될 때마다 테이블 전체를 읽어중복값 존재 여부를 체크해야 하기 때문이다. 하지만 중복 체크를 위해 반드시 Unique 인덱스가 필요한 것은 아니며, Non-Unique 인덱스로도 가능하다. Non-Unique 인덱스를 이용하면 중복 여부를 체크할 때 one-plus 스캔이 발생하는 약간의 비효율이 있기는 하지만 무시할 만하다.
PK 제약을 위해 Non-Unique 인덱스를 사용하도록 하는 방법은 다음과 같다.

(3) 컬럼 추가에 따른 클러스터링 팩터 변화
인덱스에 컬럼을 추가함으로써 테이블 랜덤 액세스 부하를 줄이는 효과가 있지만 인덱스 클러스터링 팩터가 나빠지는 부작용을 초래할 수도 있다.
그런데 컬럼을 추가하고 나니 인덱스 클러스터링 팩터가 689에서 33,843로 나빠졌다. 이유가 무엇일까?
1절에서 설명한 바와 같이 인덱스 내에서 키값이 같은 레코드는 rowid 순으로 정렬된다. 그런데 여기에 변별력이 좋은 object name 같은 컬럼을 추가하면 rowid 이전에 object name 순으로 정렬되므로 클러스터링 팩터를 나쁘게 만드는 요인으로 작용한다.
결론적으로, object type처럼 변별력이 좋지 않은 컬럼 뒤에 변별력이 좋은 다른 컬럼을 추가할 때는 클러스터링 팩터 변화에 주의를 기울여야 한다.
(4) 인덱스만 읽고 처리
테이블을 접근했을 때 필터 조건에 의해 제외되는 레코드가 많을 때, 인덱스에 컬럼을 추가함으로써 얻는 성능 향상을 살펴봤다. 그런데 테이블 랜덤 접근이 많더라도 필터 조건에 의해 제외되는 레코드가 거의 없다면 그곳에 비효율은 없다. 이때는 어떻게 튜닝해야 할까?
이때는 아예 테이블 접근이 발생하지 않도록 모든 필요한 컬럼을 인덱스에 포함시키는 방법을 고려해볼 수 있다. MS-SQL Server에서 사용하는 용어긴 하지만 그런 인덱스를 ‘Covered 인덱스’라 부르고, 인덱스만 읽고 처리하는 쿼리를 ‘Covered 쿼리’라고 한다.
(5) 버퍼 Pinning 효과 활용
오라클의 경우, 한 번 입력된 테이블 레코드는 절대 rowid가 바뀌지 않는다. 즉, 레코드 이동이 발생하지 않는다. 따라서 아래와 같이 미리 알고 있던 테이블 rowid 값을 이용해 레코드를 조회하는 것이 가능하다. 해당 레코드가 지워지지 않는다면 말이다.
위 쿼리는 emp_pk 인덱스 전체를 스캔해 얻은 레코드를 rowid 순으로 정렬한 뒤, 한 건씩 순차적으로(emp 테이블을 액세스하는 방식) 조회하고 있는데, 여기서 재미있는 상상을 해볼 수 있다. 만약 위처럼 User ROWID에 의한 테이블 액세스 시에도 버퍼 Pinning 효과가 나타난다면 어떨까?
Random 액세스 비효율은 한 건을 읽기 위해 블록을 통째로 읽기 때문에 발생하는 것인데, 위와 같은 쿼리에 버퍼 Pinning 효과까지 나타난다면 한 번 액세스로 블록 안에 있는 모든 레코드를 다 읽어들이는 셈이 된다. CF가 가장 좋을 때 인덱스 손익분기점이 90% 이상에서 결정되는 것도 그때문이었다.
따라서 그런 효과가 나타나기만 한다면 인덱스를 통해 아무리 많은 테이블 레코드를 액세스해도 Random 액세스에 의한(=I/O 측면에서의) 비효율은 거의 존재하지 않게 되고, SQL 튜닝 시 가장 자주 사용되는 기법 중 하나가 될 것이다.
(6) 수동으로 클러스터링 팩터 높이기
테이블에는 데이터가 무작위로 입력되는 반면, 그것을 가리키는 인덱스는 정해진 키(key) 순으로 정렬되기 때문에 대개 CF가 좋지 않게 마련이다. CP가 나쁜 인덱스를 이용해 많은 양의 데이터를 읽어야 할 때, SQL 튜닝이 가장 어렵다.
그럴 때, 해당 인덱스 기준으로 테이블을 재생성함으로써 CR을 인위적으로 좋게 만드는 방법을 생각해볼 수 있고, 실제 해보면 그 효과가 매우 극적이다.
주의할 것은, 인덱스가 여러 개인 상황에서 특정 인덱스를 기준으로 테이블을 재정렬하면 다른 인덱스의 CH가 나빠질 수 있다는 점이다. 다행히 두 인덱스 키 컬럼간에 상관관계가 높다면(예를 들어, 직급과 금예) 두 개 이상 인덱스의 CF가 동시에 좋아질 수 있지만 그런 경우가 아니라면 CF가 좋은 인덱스는 테이블 당 하나뿐이다.
따라서 인위적으로 CF를 높일 목적으로 테이블을 Reorg 할 때는 가장 자주 사용되는 인덱스를 기준으로 삼아야 하며, 혹시 다른 인덱스를 사용하는 중요한 쿼리 성능에 나쁜 영향을 주지 않는 지 반드시 체크해봐야 한다.
그리고 이 방법을 주기적으로 수행해야 한다면 데이터베이스 관리 비용이 증가하므로 테이블과 인덱스를 Rebuild 하는 부담이 적고 효과가 확실할 때만 사용하는 것이 바람직하다.
차세대 시스템 구축 시 주의사항
회사마다 차세대 시스템을 구축하는 목적이 다양하지만(예를 들어, 업무 프로세스 개선, 데이터 품질 개선 등) 그 중 빠지지 않는 것이 성능 개선이다.
차세대 시스템을 구축할 때는 그래서 기존보다 더 고급 사양의 하드웨어 시스템을 도입하고 SQL 튜닝도 실시해보지만 오히려 성능이 예전만 못한 경우가 외로 많다. 심지어 모델 변경을 최소화했는데도 말이다. 왜 그럴까?
여기에 CIP와 관련해서 주목해야할 중요한 시사점이 한 가지 있는데, 원인을 분석해보면 과거 시스템으로부터 데이터를 이관하는 과정에서 CF가 오히려 나빠진 데서 기인한다. 기존에 운영되던 시스템은 트랜잭션이 발생하는 순서대로 데이터가 입력되는 반면 데이터를 이관할 때는 병렬 쿼리를 많이 활용하기 때문에 데이터를 무작위로 흩어놓는 경향이 있다. 이는 애플리케이션 전반에 걸쳐 테이블 Random I/O 횟수를 증가시키고, 결과적으로 디스크 I/O 발생량과 경합을 증가시키는 요인으로 작용한다.
따라서 데이터 이관시에는 ASIS 대비 TOBE 시스템의 CF가 나빠지지 않았는지 조사하고, 그 결과에 따라 적절한 조치를 취해주어야 한다. 모든 테이블을 대상으로 삼기는 현실적으로 어렵겠지만, 적어도 자주 사용되는 거래 데이터에 대해서는 반드시 필요한 조치라고 하겠다.