<오라클 성능 고도화 원리와 해법2> Ch01-07 인덱스 스캔효율
오라클 성능 고도화 원리와 해법2 - Ch01-07 인덱스 스캔효율
1권 6장 1절에서 블록 단위 I/O 원리를 설명하면서 Random 액세스와 Sequential 액세스의 차이점을 자세히 설명했다.
Sequential 액세스는 레코드간 논리적 또는 물리적인 순서를 따라 차례대로 읽어나가는 방식을 말하고, Random 액세스는 레코드간 논리적, 물리적인 순서를 따르지 않고 한 건을 읽기 위해 한 블록씩 접근하는 방식이라고했다. 그리고 I/O 튜닝의 핵심 원리로서 아래 두가지 항목을 꼽았다.
- Sequential 액세스의 선택도를 높인다.
- Random 액세스 발생량을 줄인다.
4절에서 테이블 Random 액세스 부하원리에 대해 설명했고, 5절과 6절에선 부하 해소 원리를 설명했는데, 이는 2번 항목에 해당한다.
지금부터는 1번 Sequential 액세스의 선택도를 높이는 방법에 대해 설명하려고 한다. 즉, 테이블을 액세스하기 전, 인덱스를 Sequential 방식으로 스캔하는 단계에서 발생하는 비효율 해소 원리를 다룬다.
| Sequential 액세스 선택도 |
|---|
| 일반적인 의미에서의 선택도는 전체 레코드 중에서 조건절에 의해 선택되는 비율을 말한다. 또한, 조나단 루이스는 그의 저서 “Cost-Based Oracle Fundamentals” 에서 인덱스 액세스에 대한 비용 공식을 쉽게 설명하려고 아래 두가지 용어를 도입하였으며, 4절에서 이미 소개한 바 있다. - 유효 인덱스 선택도: 전체 인덱스 레코드 중에서 조건절을 만족하는 레코드를 찾기 위해 스캔할 것으로 예상되는 비율(%) - 유효 테이블 선택도: 전체 레코드 중에서 인덱스 스캔을 완료하고서 최종적으로 테이블을 방문할 것으로 예상되는 비율(%) 조나단 루이스가 말하는 유효 테이블 선택도가 높다면 인덱스 스캔 후 테이블 Random 액세스 비율이 높은 것이므로 앞서 선택도가 높아야 효율적이라고 한 필자의 주장과 배치된다. 하지만 본절에서 말하는 Sequential 액세스 선택도는 인덱스를 스캔한 건수 중 결과로 선택되는 비율을 말하는 것이며, 그 비율이 높아야 효율적이라는 의미는 같은 결과 건수를 내기 위해 적은 양을 읽어야 함을 이르는 것이다. |
(1) 비교 연산자 종류와 컬럼 순서에 따른 인덱스 레코드의 군집성
인덱스 스캔의 효율성을 설명하기에 앞서, 인덱스 레코드의 특성을 이해하는 게 필요하다.
테이블과는 다르게, 인덱스 레코드는 ‘같은 값을 갖는’ 레코드들이 항상 서로 군집해 있다. 그러나 ‘같은 값’을 갖는 다’라고 하면 비교가 전제되므로, 만약 비교 연산자가 조건이 아닐 때는 인덱스 레코드도 서로 흩어진 상태일 수 있다. 그림 1-37을 보면서 이해해보자.
| 선두 컬럼, 선행 컬럼 |
|---|
| 생각하기에 따라 같은 용어라고 해석될 수 있지만, 서로 헷갈리지 않도록 정리해보자. ‘선두 컬럼은 인덱스 구성상 맨 앞쪽에 있는 컬럼을 지칭할 때 사용하고, ‘선행 컬럼’은 상대적으로 앞쪽에 놓인 컬럼을 칭할 때 사용할 것이다. 선두 컬럼은 당연히 선행 컬럼에 포함된다. |
그림에서 리프 블록 아래 쪽에 있는 1부터 20까지의 숫자는 설명의 편의상 부여한 일련 번호다.
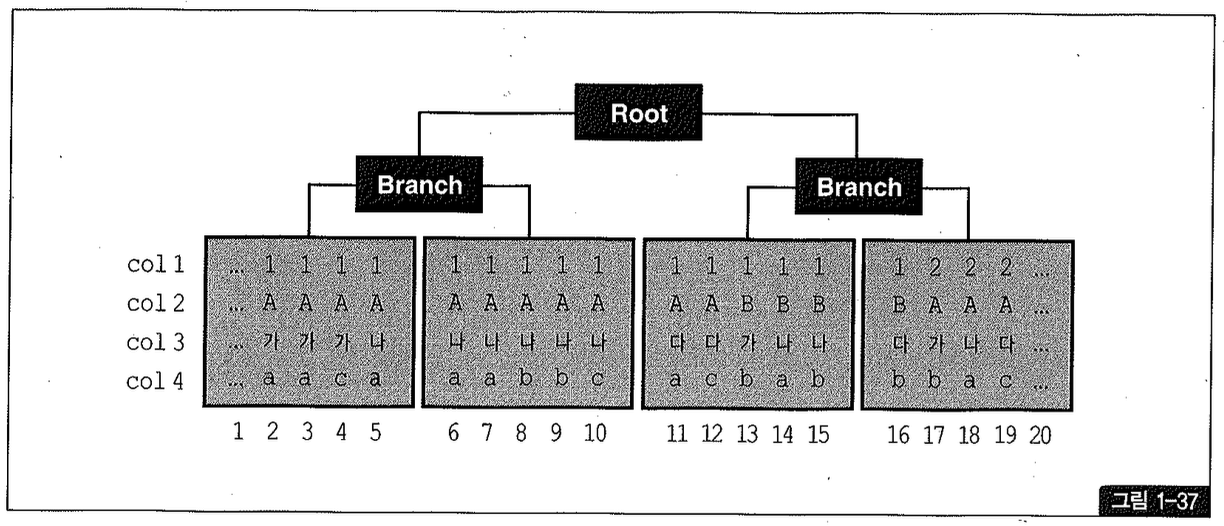
여기서 우리는 한 가지 규칙을 발견할 수 있다. 선행 컬럼이 모두 ‘=’ 조건인 상태에서 첫 번째 나타나는 범위 검색 조건까지만족하는 인덱스 레코드는 모두 연속되게 모여있지만, 그 이하 조건까지만족하는 레코드는 비교 연산자 종류에 상관없이 흩어진다(우연히 모여있을 수는 있음)는 규칙이다.
(2) 인덱스 선행 컬럼이 등치(=) 조건이 아닐 때 발생하는 비효율
Sequential 액세스 효율은 선택도에 의해 결정된다. 다르게 표현하면, 같은 결과 건수를 내는데 얼마나 적은 레코드를 읽느냐로 효율성을 판단할 수 있다.
인덱스 Sequential 액세스에 따른 선택도는 인덱스 컬럼이 조건에 모두 등치(=) 조건으로 사용될 때가 가장 높다. 리프 블록을 스캔하면서 읽은 레코드는 하나도 필터링되지 않고 모두 테이블 액세스로 이어지기 때문이다. 따라서 인덱스 스캔 단계에서의 비효율은 전혀 없다.
인덱스 컬럼 중 일부가 조건절에서 생략되거나 조건이 아니더라도, 그것이 뒤쪽 컬럼일 때는 비효율이 없다.
반면에, 인덱스 선행 컬럼이 조건에 누락되거나 between, 부등호, like 같은 범위 검색 조건이 사용되면 인덱스를 스캔하는 단계에서 비효율이 발생한다.
인덱스 선행 컬럼이 모두 ‘조건일 때 필요한 범위만 스캔하고 멈출 수 있는 것은, 조건을 만족하는 레코드가 모두 한데 모여 있기 때문이다.
(3) BETWEEN 조건을 IN-List로 바꾸었을 때 인덱스 스캔 효율
범위 점색 컬럼이 맨 뒤로 가도록 인덱스를 [아파트시세코드+평형+평형타입+인터넷매물] 순으로 변경하면 좋겠지만 운영 중인 시스템에서 인덱스 구성을 바꾸기는 쉽지 않다. 이럴 때 between 조건을 아래와 같이 IN-List로 바꿔주면 가끔 큰 효과를 얻는다.
IN-List 개수만큼 unional 브랜치가 생성되고, 각 브랜치마다 모든 컬럼을 조건으로 검색하기 때문에 앞서 선두 컬럼을 between 조건으로 비교할 때와 같은 비효율이 사라진다. 참고로, 3절에서 배운 IndexSkipScan 방식으로 유도하더라도 비슷한 효율을 얻을 수 있다.
between 조건을 IN-List 조건으로 바꿀 때 주의 사항
인덱스 선두 컬럼의 between 조건을 IN-List 조건으로 바꿀 때 주의할 점은, IN-List 개수가 많지 않아야 한다는 것이다. 그림1-39처럼 필요 없는 범위를 스캔하는 비효율은 사라지겠지만, 그림1-40처럼 인덱스 수직 탐색이 여러 번 발생하기 때문이다. IN-List 개수가 많을 때는, between 조건 때문에 리프 블록을 추가로 스캔하는 비효율 보다 IN-List 조건 때문에 브랜치 블록을 반복 탐색하는 비효율이 더 클 수 있고, 인덱스 높이(heigh)가 높을 때 특히 그렇다. (경우에 따라서는 인덱스 수직 탐색 과정에서의 일량도 상당하다. 그림1-2와 설명 참조)
인덱스 스캔 과정에서 선택되는 레코드들이 서로 멀리 떨어져 있을 때만 유용하다는 사실도 기억하기 바란다. between 조건인 선행 컬럼 때문에 많은 인덱스 리프 블록을 스캔하지만 거기서 선택되는 레코드는 소량일 때라야 IN-List로의 변환이 효과를 낸다. 왜냐면, 많은 레코드를 스캔하는 비효율이 있을지언정 블록 I/O 측면에서는 대개 소량에 그치는 경우가 많기 때문이다. 인덱스 리프 블록에는 테이블 블록과 달리 매우 많은(8KB 블록 기준으로 대략 수백개) 레코드가 담긴다.
(4) Index Skip Scan을 이용한 비효율 해소
인덱스의 선두 컬럼이 누락됐을 때뿐만 아니라 부등호, between, like 같은 범위 검색 조건일 때도 인덱스 스킵 스캔이 유용하게 사용될 수 있고, 데이터 상황에 따라서는 조건 컬럼들을 인덱스 선두에 위치시킨 것에 버금가는 효과를 얻는다.
이 쿼리를 위해서라면 ‘조건인 판매구분이 선두 컬럼에 위치하도록 아래와 같이 인덱스를 구성하는 것이 가장 효과적이다.
마지막 시도로서, 인덱스 스킵 스캔으로 유도해보자.

인덱스의 선두 컬럼이 between 조건임에도 큰 비효율 없이 단 300 블록만 읽고 일을 마쳤다. 아래 표는 네 가지 테스트 결과를 요약한 것인데, 인덱스 스킵 스캔이 IN-List보다 오히려 나아고 [판매구분+판매월] 순으로 구성된 인덱스를 사용할 때와 비교해서도 별 차이가 없다.

선두 컬럼이 between이어서 나머지 검색 조건을 만족하는 데이터들이 서로 멀리 떨어져 있을 때가, 인덱스 스킵 스캔으로써 효과를 볼 수 있는 전형적인 케이스다(불필요한 리프 블록에 대한 액세스를 Skip하고 가능성 있는 리프 블록으로 점프하는 그림 1-10 참조).
(5) 범위 검색 조건을 남용할 때 발생하는 비효율
지금까지 between을 중심으로 설명했는데, 여기서는 like 조건을 기준으로 설명을 진행하겠다. like도 between일 때와 기본 원리는 같고, 다만 스캔 범위에 약간의 차이가 생긴다. 이에 대해서는 바로 다음 항에서 설명한다.
사용자 선택에 따라 조건절이 다양하게 바뀔 때 SQL을 간편하게 작성하려고 조건절을 모두 like로 구사하는 개발팀을 종종 보는데, 해당 컬럼이 인덱스 구성 컬럼일 때는 주의가 필요하다.
이처럼 코딩을 쉽게 하려고 인덱스 컬럼에 범위 검색 조건을 남용하면 첫 번째 범위 검색 조건에 의해 스캔 범위가 대부분 결정되며, 그 다음을 따르는 조건부터는 스캔 범위를 줄이는 데에 크게 기여하지 못하므로 성능상 불리해질 수 있다.
스캔량이 적을 때는 그 차이가 미미하지만 대량일 때는 상당한 속도 차이를 보일 수 있다. 따라서 SQL을 작성할 때 주의가 요구되며, 인덱스 컬럼에 대해 비교 연산자를 신중하게 선택해야 하는 이유다.
| 범위 검색 조건만으로 구성된 쿼리 튜닝 사례 |
|---|
오래 전에 골택시 관제 시스템을 튜닝한 적이 있다. 운행 중인 택시들로부터 10초마다 송신되어온 위치 정보를 데이터베이스에 저장하고 있다가 고객으로부터 콜(Call)이 오면 반경 1km 이내의 가장 가까운 택시에게 신호를 보내는 시스템이다. 이 서비스를 위해 사용된 쿼리는 아래와 같다.  그리고 인덱스 구성은 다음과 같다.  우편번호 테이블과 조인하는 부분도 비효율이 있어서 튜닝했지만, 여기서 설명하고자 하는 핵심 내용인 아래 gis 데이터 쿼리 부분만 따로 떼서 분석해보자. 여기서 쓰인 숫자 1은 1km를 의미한다.  특징적인 것은, 조건절이 모두 between 범위 검색 조건이라는 사실이다. 따라서 인덱스 스캔 범위는 인덱스 선두 컬럼인 9 19_위도’컬럼에 대한 between 조건에 의해 거의 결정된다. 데이터 분포를 살펴보자. gis 데이터 테이블에는 당일치만 보관(전일 데이터는 백업 후 곧바로 삭제)하므로 당일 영업이 시작되는 시점에는 조회 속도가 아주 빠르다. 하지만 시간이 흘러 밤늦은 시간이 되면, 고객의 특정 위치 기준으로 위도 상 좌우 1km 이내에 평균 100만개 레코드가 쌓여 매우 느려진다. gis 위도 컬럼에 대한 between 조건에 의해 인덱스를 스캔해야 할 건수가 10만 건이나 되니 당연하지 않겠는가. 어떻게 튜닝하면 좋을까? 지금까지 설명한 인덱스 스캔 원리상 현재 데이터 모델로는 과도한 인덱스 스캔 범위를 줄일 방법은 없다. 여러 가지 고민을 하던 차에 필자와 같이 튜닝에 참여했던 동료 컨설턴트가 아이디어를 냈다. 반경 1km 이내를 한 번에 조회하지 말고 50m, 200m, 1 km 순으로 나눠서 쿼리하자는 것이다. 어차피 가장 가까운 데 위치한 하나의 택시를 찾는 게 목적이므로 그렇게 세 구간으로 나누어 쿼리하면 대부분 첫 번째 쿼리에서 찾게 된다. 따라서 기존보다 인덱스 스캔량을 1/20로 줄일 수 있어 쿼리 성능을 그만큼 향상시킬 수 있다. 실제 적용해보니 아주 성공적이었다. 아래는 반경 50m 이내에서 가장 가까운 곳에 위치한 택시를 찾는 쿼리다.  반경 200m와 1km 이내에서 가장 가까운 택시를 찾을 때는 0.05를 각각 0.2와 1로 바꿔주기만 하면 된다. 우편번호와 조인하는 부분도 눈여겨볼 필요가 있는데, 최종 건수는 항상 한 건이므로 미리 조인하지 않고 죄송한 건에 대해서만 조인하도록 변경하였다. 1권 5장에서 설명했던 데이터베이스 Call 최소화 원리에 따르면 여러 개로 나누어 실행하던 SQL을 하나로 통합하는 것이 효과적이다. 하지만 여기서는 거꾸로 하나의 SQL로 처리하던 것을 두 번, 세 번 나누어 처리함으로써 성능을 개선한 재미있는 사례다. |
(6) 같은 컬럼에 두 개의 범위 검색 조건 사용 시 주의사항
앞에서는 다른 컬럼에 각각 범위 검색 조건을 사용하는 경우를 살펴봤는데, 같은 컬럼에 두 개의 범위 검색 조건을 사용할 때도 세심한 주의가 필요하다.
도서 조회용 프로그램을 개발 중이라고 하자. 예를 들어 ‘오라클’을 키워드로 입력하면, ‘오라클’로 시작하는 모든 도서가 조회되어야 한다. 한 화면에 10개씩 출력되도록 하는 것이 업무 요건이면, 흔히 아래와 같은 패턴으로 SQL을 작성한다(스크립트 ch1.14, kt 참조).

도서명 컬럼에 인덱스가 있다면 첫 번째 rownum 조건(rownum <= 100)에 해당하는 레코드만 읽고 멈출 수 있다. count(stopikey) 오퍼레이션이 작용하기 때문이며, 사용자들이 앞쪽 일부 레코드만 주로 본다면 위 쿼리도 만족스런 속도를 보인다. 표준적인 페이지 처리 구현 패턴으로 가장 적당하다고 하겠다.
그런데 뒤쪽 어느 페이지로 이동해도 빠르게 조회되도록 구현해야 한다면? 앞쪽 레코드를 스캔하지 않고 해당 페이지 레코드로 바로 찾아가도록 해야 하는데, 아래는 첫 번째 페이지를 출력하고 나서 ‘다음’ 버튼을 누를 때의 구현 예시다.


그런데 SQL에 비효율이 없어 보이는 데도 union all 아래쪽 인덱스 스캔 단계에서만 377개 블록을 읽었다. 이유는, 도서명에 대한 범위 검색 조건이 두 개인데 그 중 like 조건을 인덱스 액세스 조건으로 사용했기 때문이다.
사용자가 키워드로 입력한 ‘오라클’ 도서를 처음부터 스캔하다가 last_book_nmi보다 큰 9개 레코드를 찾고서야 멈추었고, 사용자가 뒤쪽 페이지로 많이 이동할수록 그 비효율은 점점 커진다.
해결 방안은? ‘도서명 > last_book_nmi’ 조건이 인덱스 액세스 조건으로 사용되도록 하면 된다.
부등호 조건을 만족하는 첫 번째 레코드부터 스캔을 시작했기 때문에 인덱스에서 스캔한 블록 수가 단 2개로 줄었다.
OR-Expansion을 이용하는 방법과 주의사항
아래처럼 use_concat 힌트를 사용하면 union all을 사용할 때보다 SQL 코딩량을 줄일 수 있다. OR 조건에 대한 expansion(unional 분기)이 일어나면 뒤쪽 조건이 먼저 실행된다는 특징을 이용한 것이다.
주의할 점은, 버전에 따라 실행되는 순서가 달라진다는 사실이다. 9i까지는 I/O 비용 모델, CPU 비용 모델을 불문하고 뒤쪽에 있는 조건값을 먼저 실행하지만 10g CPU 비용 모델에서는 계산된 카디널리티가 낮은 쪽을 먼저 실행한다.
따라서 10g에서 값 분포에 상관없이 항상 뒤쪽에 있는 조건식이 먼저 처리되도록 하려면 ordered_predicates 힌트를 명시해야 한다. 자세한 설명은 4장 12절(3) 항 ‘조건절 비교 순서’를 참조하기 바란다.
rowid를 concatenation 하면 결과에 오류 발생
첫 페이지에서 출력한 마지막 rowid보다 큰 값으로 조회하는데, 문자형으로 변환되는 바람에 비교되는 값들의 순서가 서로 역전된다면 쿼리 결과 집합이 틀려질 수 있음을 이해하겠는가?
인덱스를 스캔하면서 rowid를 필터링할 때 발생하는 비효율
rowid를 이용한 액세스이므로 비효율 없이 항상 완벽한 속도를 보장할 거 같지만 그렇지 않다. rowid를 가지고는 조건으로 바로 액세스할 땐 어떤 액세스보다 빠르지만 인덱스를 스캔하면서 rowid를 필터링할 때는 아니다.
인덱스 rowid는 리프 블록에만 있기 때문에 이를 필터링하려면 일단 다른 액세스 조건만으로 리프 블록을 찾아가야 한다. 거기서 스캔을 시작해 rowid를 필터링해야 하므로 ‘도서’ 테이블에 같은 도서명을 가진 레코드가 “아주” 많다면 뒷 페이지로 이동할수록 비효율도 커진다.
비효율 없는 가장 완벽한 구현을 위해서라면 도서명idx 인덱스 뒤쪽에 도서번호(PK컬럼)를 붙이고 쿼리를 아래와 같이 바꾸면 된다.
하지만 인덱스 뒤에 PK컬럼을 붙여가며 개발하는 것이 쉽지만은 않다. 더구나 PK가 다중 컬럼으로 구성된다면 구현하기가 더 복잡해진다. 따라서 중복값이 아주 많은 경우가 아니라면 rowid를 이용하는 방안이 현실적이다.
(7) Between과 Like 스캔 범위 비교
월별로 집계된 테이블에서 2009년 1월부터 12월 데이터를 조회하고자 할 때 흔히 아래와 같이 like 연산자를 사용한다.
1
2
select * from 월별고객별판매집계
where 판매월 like '2009%';
원래 아래와 같이 between 연산자를 사용하는 것이 더 정확한 방식임에도 개발자들이 like를 더 선호하는 이유는 간단하다. like로 코딩하는 것이 더 단순하고 쉽기 때문이다.
1
2
select * from 월별고객별판매집계
where 판매월 between '200901' and '200912';
like와 between은 둘 다 범위 검색 조건으로서, 앞에서 설명한 범위 검색 조건을 사용할 때의 비효율 원리도 똑같이 적용된다. 하지만 검색을 위해 입력한 값과 테이블의 실제 데이터 상황에 따라 둘 간의 인덱스 스캔량이 달라질 수 있다. 결론부터 말해, between을 사용한다면 적어도 손해볼 일은 없다. (6장 2절에서 보겠지만 Range 파티션 테이블을 쿼리할 때도 like 보다 가능한 between 연산자를 사용하는 편이 낫다.)
between 연산자를 사용한 쿼리는, 2009년 2월 데이터는 모두 읽더라도 2009년 1월 데이터 만큼은 판매구분이 B인 데이터만 읽는다. 반면 like 연산자를 사용한 쿼리는 2009년 1월과 2월 데이터를 모두 읽어야 한다. 쿼리가 1월 데이터를 모두 스캔한 이유는, 리프 블럭에 실제 없는 값(2009)으로 조회했기 때문이다.
범위검색 조건의 스캔 시작점 결정 원리
지금부터 설명할 인덱스 스캔 시작점 결정 원리는 이해하기 쉽지 않은 내용이다. 정확한 원리를 이해하지 못하더라도 대충 어떤 의미인지를 파악하는 것만으로 충분하다고 하겠으며, 결론부터 말하면 범위 검색 조건 뒤를 따르는 조건은 스캔 범위를 줄이는 데에 영향을 미칠 수도 있고 그렇지 않을 수도 있다. 사용자가 조건 비교를 위해 입력한 값이나 테이블의 실제 데이터 상황에 따라 달라지며, 적어도 between이 like보다 더 넓은 범위를 스캔하는 경우는 없으므로 가능한 between을 사용하기 바란다는 내용이다.
인덱스 컬럼 조건에 대해 범위 검색 조건이 나타나면 이후 조건은 인덱스 스캔 범위를 줄여주지 못해 비효율이 생긴다. 하지만 방금 전에 설명했듯이 범위 검색 조건 뒤에 사용된 조건들도 제한적이나 마스캔 범위를 줄이는 데에 기여할 수 있는데, 지금부터 그 원리를 살펴보자.
먼저, 1절에서 설명한 인덱스 구조와 탐색 원리를 다시 한 번 상기하기 바란다. 그 중에서도 그림 1-2와 그에 대한 설명을 정확히 이해해야만 스캔 시작점 결정 원리를 이해할 수 있다.
| 여기서 키포인트는 실제 테이블에 존재하는 값을 수직적 탐색 조건으로 사용했다는 점이다. 만약 같은 between이더라도 쿼리6과 같이 실제 테이블에 없는 데이터 값을 입력하고 조회한 경우에는 200812’1 | B인 레코드가 담긴 가장 마지막 리프 블록부터 스캔을 시작하게 되므로 불필요하게 2009011A’ 구간까지 읽게 된다. |
반대로, like 조건이더라도 쿼리7과 같이 실제 테이블에 있는 데이터 값을 입력하고 조회할 때는 판매구분=’조건이 스캔 범위를 줄이는 데에 큰 역할을 하였다. 즉, 20090111A인 구간을 생략하고 20090111B’ 구간 만 정확히 읽는다.
(8) 선분이력의 인덱스 스캔 효율
범위 검색 조건 뒤를 이어가는 또 다른 범위 검색 조건도 인덱스 스캔 범위를 줄이는 역할을 일부 할 수 있지만 일반적으로 그 영향력은 크지 않다. 특히 항상 두 개의 부등호 조건을 함께 사용하는 선분 이력에서는15) 데이터 특성상 두 번째 부등호 조건이 스캔 범위를 줄이는 데 전혀 도움을 주지 못한다.
15 between은 두 개의 부등호(=, >=)를 함께 사용한 것과 같다.
두 개의 부등호 조건을 사용하는 선분 이력 조회의 특성을 제대로 이해하지 못해 인덱스 구성을 잘못하면 성능이 많이 나빠질 수 있다. 그리고 어느 시점을 주로 조회하느냐에 따라서도 인덱스 스캔 효율이 많이 달라지므로 인덱스 설계 및 쿼리 작성 시 매우 세심한 주의가 필요하다.
선분이력이란?
예를 들어 고객의 변경 이력을 관리할 때 이력의 시작 시점만을 관리하는 것을 ‘점이력’ 모델이라고 하고, 시작 시점과 종료 시점을 함께 관리하는 것을 ‘선분이력’ 모델이라고 한다.
점이력으로 관리할 때 PK가 [고객번호+변경일자]로 구성된다면, 선분이력으로 관리할 때는 [고객번호+시작일자+종료일자]로 구성된다. 그리고 가장 마지막 이력의 종료일자는 항상 99991231(시간까지 관리할 때는 99991231235959)로 입력해두어야 한다.
이력을 이처럼 선분 형태(예를들어, 20090501~20090613)로 관리하면 무엇보다 쿼리가 간단해진다는 것이 가장 큰 장점이다. 예를 들어, 123번 고객의 2009년 5월 5일 시점 이력을 조회하고자 할 때 아래처럼 between 조인을 이용해 간편하게 조회할 수 있다.
1
2
3
4
5
select a.고객번호, a.고객명, a.연락처, a.주소, b.연체금액, b.연체개월수
from 고객 a, 고객별연체금액 b
where a.고객번호 = '123'
and b.고객번호 = a.고객번호
and '20090505' between b.시작일 and b.종료일;
데이터를 점이력으로 관리할 때 아래처럼 서브쿼리를 이용해 복잡하게 쿼리하던 것과 비교해 보기 바란다.
1
2
3
4
5
6
7
8
9
10
select a.고객번호, a.고객명, a.연락처, a.주소, b.연체금액, b.연체개월수
from 고객 a, 고객별연체금액 b
where a.고객번호 = '123'
and b.고객번호 = a.고객번호
and b.변경일 = (
select max(변경일)
from 고객별연체금액
where 고객번호 = a.고객번호
and 변경일 = 20090505'
);
쿼리가 간단하면 아무래도 성능상 유리할 때가 많다. 대신, 이력이 추가될 때마다 기존 최종 이력의 종료일자(또는 종료일시도 같이 변경해주어야 하는 불편함이 있다. 이 때문에 DML 성능뿐만 아니라 이력 데이터를 관리(잘못된 과거 이력 데이터를 일괄 보정하는 등)하는 프로그램이 복잡해진다.
중요한 또 다른 단점은, 개체 무결성을 사용자가 직접 관리해주어야 한다는 것이다. 선분이력의 개체 무결성을 확보하려면 선분의 중복(예를들어, 5/5~5/18, 5/15~6/23 두 개의 선분이 입력되면 5/15~5/18 구간에 중복 발생)이 없어야 한다. 점이력일 때는 PK 제약을 설정하는 것만으로 개체 무결성이 완벽히 보장되지만, 선분이력일 때는 선분이 겹치거나 끊기지 않도록 방지하는 기능을 DBMS가 제공하지 않아 개체 무결성이 보장되지 않는다. PK를 [고객번호+시작일자] 또는 [고객번호+종료일자]로 구성하면 PK 중복은 피할 수 있지만 선분의 중복은 피할 수 없다는 얘기다.
선분이력의 개체 무결성은 어차피 애플리케이션에서 구현할 수 밖에 없으므로 프로그래밍할 때 동시성 제어 기법을 철저히 적용해야 하는 수고가 뒤따르고, 그럼에도 사용자가 직접 데이터를 입력/수정하는 과정에서 정합성이 깨지는 문제는(트리거를 이용하지 않는 한) 근본적인 해결이 불가능하다.
RDBMS 설계 사상에 맞지 않게 PK값이 변경된다는 사실도 자주 시비의 대상이 되곤한다. PK 제약만으로는 개체 무결성이 보장되지 않으니 인덱스 스캔 효율이라도 높이기 위해 통상 PK 구성에 시작일자와 종료일자가 모두 포함되도록 설계하기 때문이다. [고객번호+시작일자] 또는 [고객번호+종료일자]로 PK를 구성한 상태에서 update/insert 순서를 잘 조절하면 PK값이 변경되지 않도록 구현할 수는 있지만, 그 때는 시작일자와 종료일자를 모두 포함한 인덱스를 별도로 생성해주어야 한다. 선분이력 모델과 관련해 이처럼 많은 이슈들이 존재하지만 본서는 모델링을 다루는 책이 아니므로 더 이상 깊이 설명하지는 않겠다.
선분이력 기본 조회 패턴
조금 전 선분이력 조회를 간단히 살펴보았는데, 선분이력에 자주 사용되는 기본 조회 패턴을 정리해보자. 조인을 포함한 선분이력 조회와 튜닝 방안에 대해서는 2장에서 다루며, 여기서는 단일 테이블 조회만을 기준으로 설명한다.
가장 기본적인 패턴으로 과거, 현재, 미래임의 시점을 모두 조회할 수 있도록 하려면 아래처럼 쿼리를 작성하면 된다. 예를들어, 2004년 12월 31일치 데이터를 조회하려면 dt 변수에 ‘20041231’ 을 입력하면 된다.
1
2
3
4
5
select 연체개월수, 연체금액
from
고객별연체금액
where 고객번호= '123'
and :dt between 시작일 and 종료일
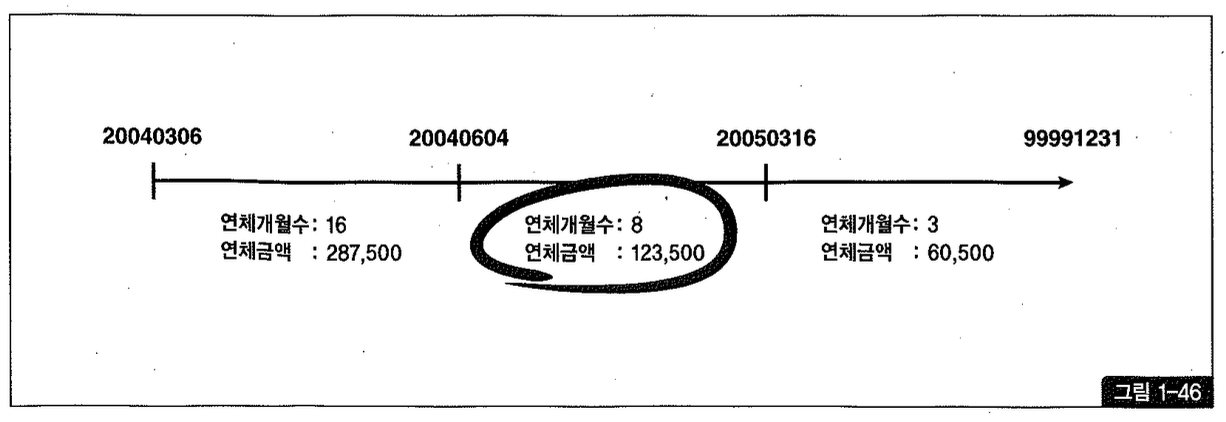
고객번호='123' 에 해당하는 세 개의 이력 레코드가 각각 하나의 선분이라고 할 때, 세 개의 선분을 하나의 수평선상에 연결해 그려보면 그림 1-46과 같다. 그 중 2004년 12월 31일 값이 속한 구간은 가운데이며, between 검색을 통해 쉽게 찾아낼 수 있다.
현재 시점을 조회할 때는 ‘99991231’ 상수 조건을 이용해 아래와 같이 느 조건으로 검색하는 것이 성능상 유리하다.
1
2
3
4
5
select 연체개월수, 연체금액
from
고객별연체금액
where 고객번호='123'
and 종료일= 19991231
물론 맨 마지막 이력 레코드는 종료일에 ‘9991231’ 을 넣는다는 약속을 전제로 하며, 선분이력이 갖는 이점을 제대로 활용하려면 꼭 그렇게 값은 넣어야만 한다.
주의할 것은, 선분이력 테이블에 정보를 미리 입력해두는 경우가 종종 있고 그럴 때는 현재 시점을 위와 같은 식으로 조회해선 안된다. 예를들어, 고객별 연체 변경 이력을 지금 등록하지만 그 정보의 유효 시점이 내일일 때는 아래와 같이 sysdate 와 between 조건을 사용해야 한다.
1
2
3
4
5
select 연체개월수, 연체금액
from
고객별연체금액
where 고객번호= '123'
to_char(sysdate, 'yyyymmdd') between 시작일 and 종료일
선분이력을 미리 입력해두는 더 흔한 사례는 다음과 같다. 상품 가격 정보가 익일 0시부터 바뀐다고 할 때, 가격을 변경하는 Job을 걸어놓더라도 정확히 12시에 트리거링된다는 보장이 없다. 그 뿐만 아니라 update가 시작되고 커밋되기까지 그 짧은 순간에 진행된 주문 트랜잭션은 이전 가격을 기준으로 거래되어 데이터 일관성에 문제가 생길 수 있다. 그럴 때 시작일시가 익일 0시인 선분 레코드를 미리 등록해놓는다면 그런 현상을 미연에 방지할 수 있다.
선분이력 기본 조회 패턴에 대해 살펴봤고, 지금부터는 선분이력 인덱스의 스캔 효율을 높이는 방법에 대해 살펴보자.
[시작일+종료일] 구성일 때 최근 시점 조회
인덱스가 [고객번호+시작일+종료일] 순으로 구성된 상태에서 아래와 같이 특정 고객에 대한 최근 시점 연체 정보를 조회한다고 하자.
1
2
3
4
5
select *
from 고객별연체금액
where
고객번호='123'
and '20050131' between 시작일 and 종료일
위 between 조건을 부등호로 풀어쓰면 아래와 같다.
1
2
3
4
where 고객번호='123'
and
시작일 <= '20050131' and
종료일 >= '20050131'
조건인 고객번호 다음 인덱스 컬럼(시작일)이《=조건이므로 2005년 1월 31일 이전 이력 레코드를 모두 스캔해야 하며, 시작일 컬럼에 표시한 점선이 그 범위를 나타내고 있다.
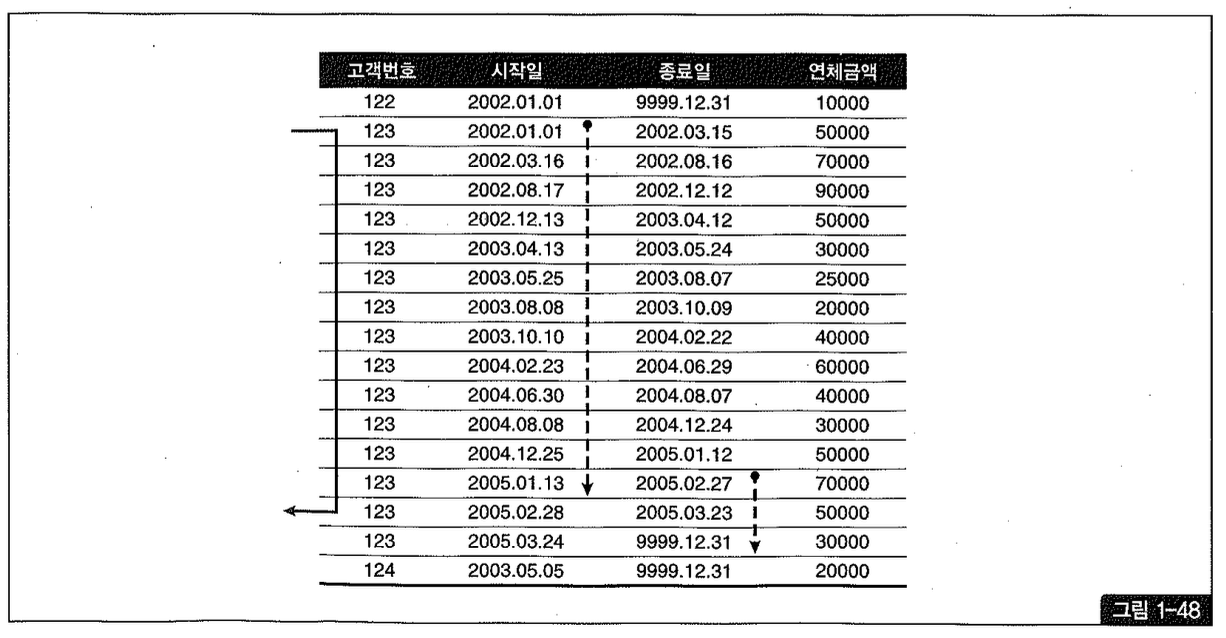
마찬가지로 종료일 컬럼에 표시한 점선이 종료일 조건을 위해 스캔해야 할 범위를 나타낸 것이고, 시작일보다 훨씬 적은 범위지만 그 선두 컬럼인 시작일 조건이 부등호(《=)이기 때문에 스캔 범위를 줄이는데에 기여하지 못한다.
다행히 종료일이 인덱스 컬럼에 포함되어 있기 때문에 테이블 Random 액세스 없이 인덱스 내에서 필터링할 수 있다. 문제는, 종료일까지 필터링한 최종 레코드는 언제나 한 건 뿐인데도 불구하고 이력 레코드가 많이 쌓인 고객일수록 그 한 건을 찾기 위해 많은 인덱스 레코드를 스캔해야 한다는 데에 있다.
그럴 때 아래와 같이 index_desc 힌트를 주고 rownum 《= 1 조건을 추가해주면, 인덱스를 거꾸로 한 건만 스캔하고 원하는 이력 레코드를 빠르게 찾을 수 있다.
1
2
3
4
5
6
select /*+ index_desc(a idx01) */ *
from 고객별연체금액 a
where 고객번호='123'
and
'20050131' between 시작일 and 종료일
and rownum<= 1
만약 인덱스를 생성할 때 시작일 컬럼에 desc 옵션을 준다면, rownum 《= 1 조건 만 사용해도 된다.
[시작일+종료일] 구성일 때 과거 시점 조회
인덱스 구성은 똑 같이 [고객번호 + 시작일 + 종료일]인 상태에서 이번에는 아주 오래된 과거의 연체 정보를 조회하는 경우를 살펴보자.
1
2
3
4
select *
from 고객별연체금액
where 고객번호 = '123'
and '20020930' between 시작일 and 종료일
위 between 조건을 부등호로 풀어쓰면 아래와 같다.
1
2
where 고객번호 = '123'
and 시작일 <= '20020930' and 종료일 >= '20020930'
’=’ 조건인 고객번호 다음 인덱스 컬럼(시작일)이 <= 조건이지만 2002년 9월 30일 이전에 속한 레코드가 얼마 없어 그림 1-49에서 시작일 컬럼에 점선으로 표시한 만큼 소량의 레코드만 스캔하면 된다.
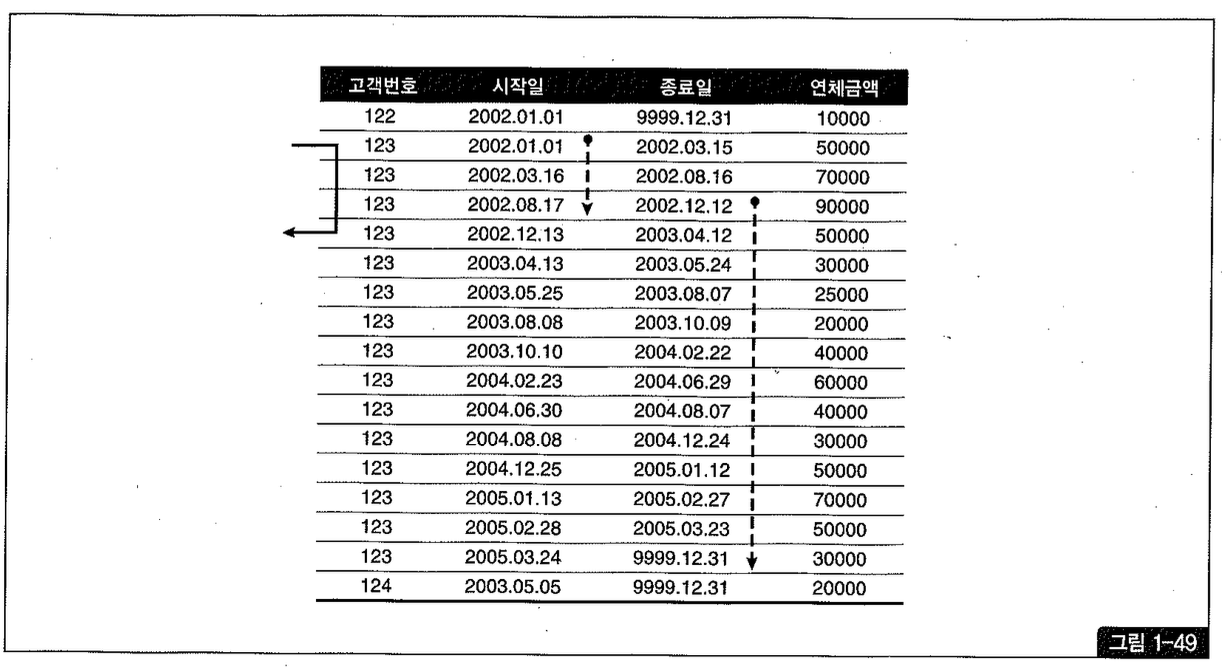
스캔량이 얼마 되진 않지만 아래와 같이 index desc 힌트를 주고 rownum <= 1 조건을 추가한다면 스캔 범위를 단 한 건으로 줄일 수 있다.
1
2
3
4
5
6
7
select /*+ index desc(a idx01) */ *
from 고객별연체금액 a
where
고객번호 = '123'
and
'20020930' between 시작일 and 종료일
and rownum <= 1
[종료일+시작일] 구성일 때 최근 시점 조회
이번에는 인덱스 구성을 [고객번호+종료일+시작일] 순으로 바꾼 상태에서 아래와 같이 특정 고객의 최근 시점 연체 정보를 조회하는 경우를 살펴보자.
1
2
3
4
5
select *
from 고객별연체금액
where 고객번호='123'
and
'20050131' between 시작일 and 종료일
위 between 조건을 부등호로 풀어쓰면 아래와 같다.
1
2
3
4
where 고객번호='123'
and
시작일 <= '20050131'
and 종료일 >= '20050131'
’=’ 조건인 고객번호 다음 인덱스 컬럼(종료일)이 >= 조건이므로 2005년 1월 31일 이후 이력 레코드를 모두 스캔해야하지만, 이 범위에 속한 레코드가 얼마 되지 않아 그림 1-50에서 종료일 컬럼에 점선으로 표시한 만큼만 스캔하면 된다.
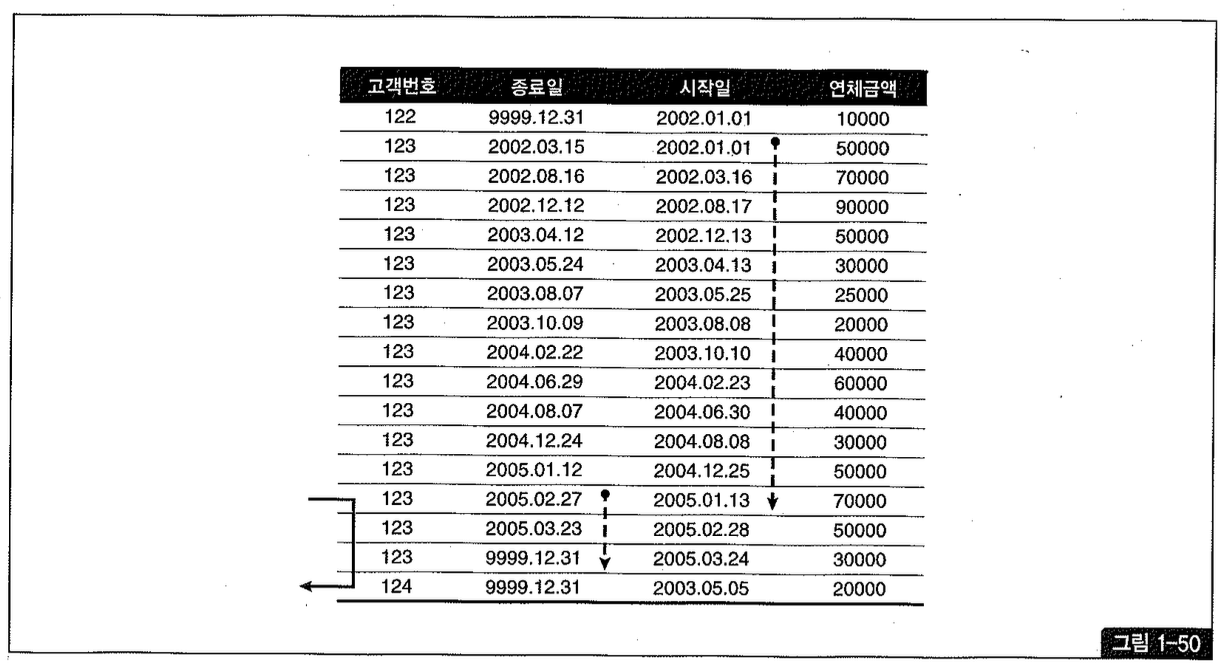
스캔량이 얼마 되진 않지만 아래와 같이 rownum <= 1 조건을 추가해 준다면 스캔 범위를 단 한 건으로 줄일 수 있다.
1
2
3
4
5
6
7
select *
from 고객별연체금액 a
where
고객번호= '123'
and
'20050131' between 시작일 and 종료일
and rownum <= 1
[종료일+시작일] 구성일 때 과거 시점 조회
인덱스 구성은 똑같이 [고객번호+종료일+시작일]인 상태에서 이번에는 아주 오래된 과거의 연체 정보를 조회하는 경우를 살펴보자.
1
2
3
4
5
6
7
select *
from
고객별연체금액
where
고객번호= '123'
and
'20020930' between 시작일 and 종료일
위 between 조건을 부등호로 써서 풀어쓰면 아래와 같다.
1
2
3
4
where 고객번호='123'
and
시작일 <= '20020930'
and 종료일 >= '20020930'
’=’ 조건인 고객번호 다음 인덱스 컬럼(종료일)이 >= 조건이므로 2002년 9월 30일 이후 이력 레코드를 모두 스캔해야하며, 그림 1-51에서 종료일 컬럼에 표시한 점선이 그 범위를 나타내고 있다.
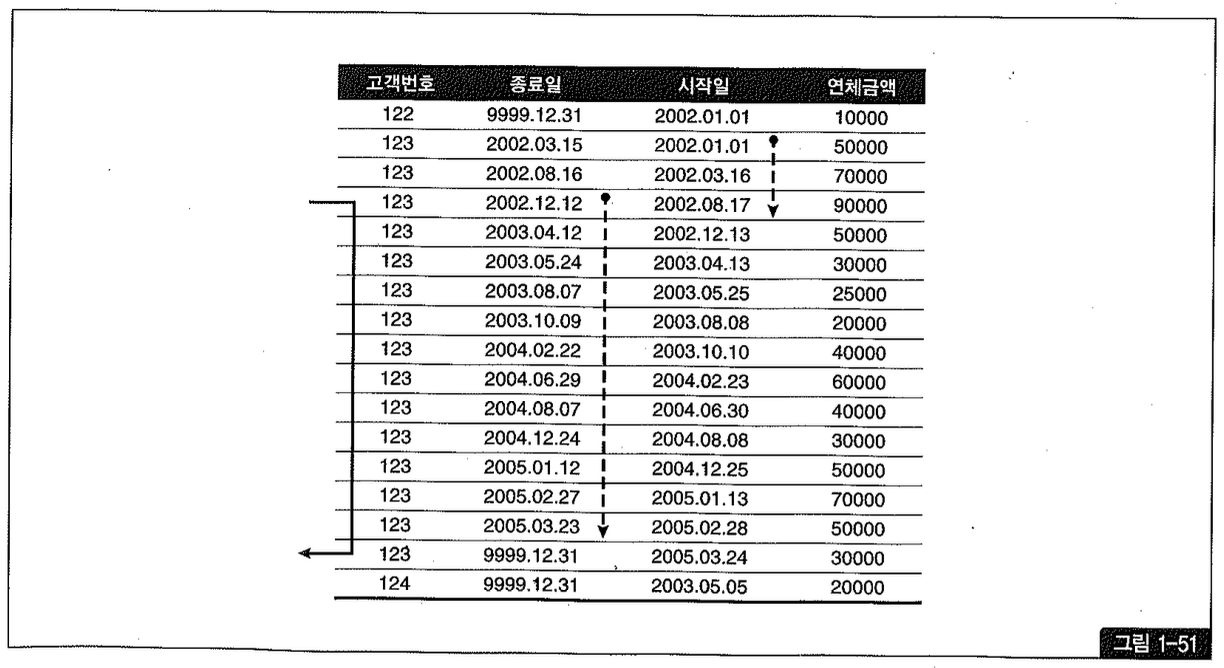
종료일 조건 때문에 스캔해야 할 범위가 아무리 넓더라도 아래와 같이 rownum <= 1 조건을 추가해 준다면 단 한 건만 스캔하고도 원하는 이력 레코드를 빠르게 찾을 수 있다.
1
2
3
4
5
6
select *
from
고객별연체금액a
where
고객번호= '123'
and '20020930' between 시작일 and 종료일 and rownum <= 1
중간 시점 조회
최초 이력이나 최근 이력을 조회하는 것이 아니라 중간 시점(예를 들어, 203년 10월 10일) 이력을 조회할 때는 인덱스 구성을 어떻게 하든 그림 1-52에서 보는 것처럼 어느 정도의 비효율을 감수해야만 한다.
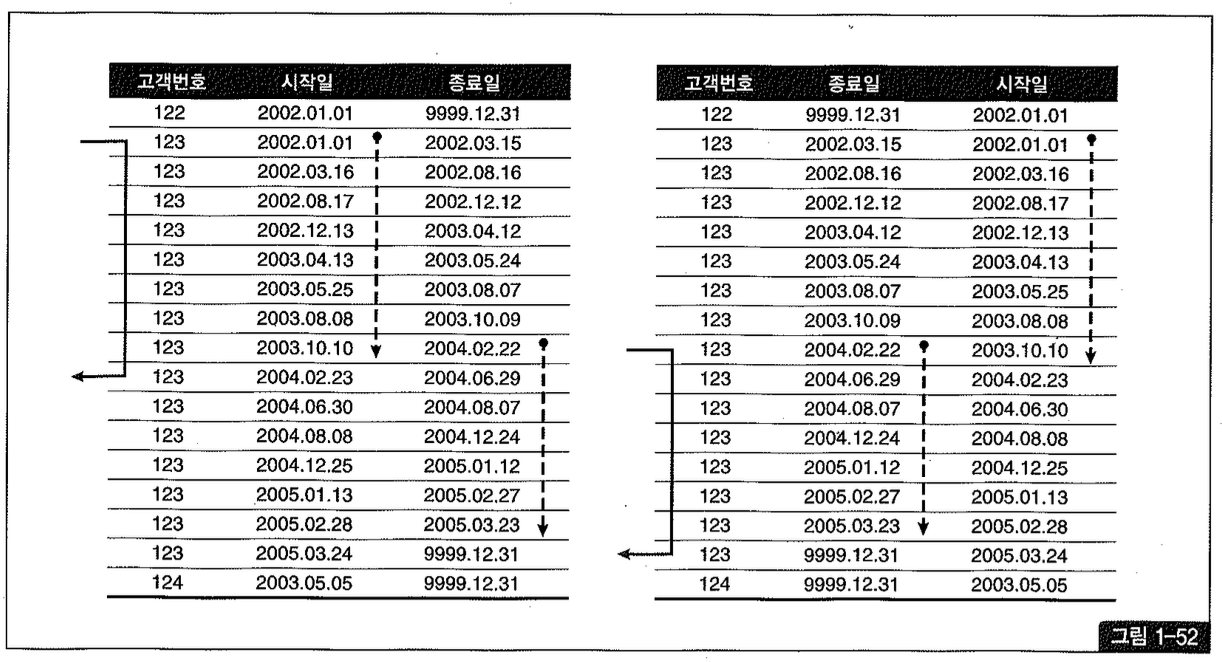
하지만 중간 시점을 조회할 때도 아래처럼 rownum <= 1 조건을 활용하면 단 한 건만 스캔하고도 원하는 이력 레코드를 빠르게 찾을 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 인덱스 구성이 [고객번호+시작일+종료일] 일 때
select
/*+ index desc a( idx x01) */ *
from
고객별연체금액 a
where
고객번호= '123'
and
'20031010' between 시작일 and 종료일 and
rownum <= 1
-- 인덱스 구성이 고객번호+종료일+시작일] 일 때
select *
from 고객별연체금액 a
where 고객번호= '123'
and
'20031010' between 시작일 and 종료일 and rownum <= 1
선분 이력 스캔 효율을 높이는 방법 요약
복잡하다고 느낄 것이므로 지금까지 설명한 내용을 요약해보자.
선분 이력처럼 between 검색 조건이 사용될 때는 어느 시점을 주로 조회하느냐에 따라 인덱스 구성 전략을 달리 가져가야 한다. 최근 데이터를 주로 조회한다면 [종료일+시작일) 순으로 구성하는 것이 효과적이며, 오래된 과거 데이터를 주로 조회한다면 [시작일+종료일] 순으로 구성하는 것이 효과적이다.
rownum과 index_desc 힌트를 적절히 사용하면 인덱스 구성이 어떻든지 간에 항상 필요한 한 건만 스캔하도록 할 수 있다. 인덱스 구성이 [시작일+종료일] 일 때는 index.desc 힌트와 rownum <= 1 조건을 추가해주고, [종료일+시작일] 일 때는 rownum=1 조건만 추가해주면 된다.
중간 시점을 조회할 때도 이 방식을 사용하면 인덱스 구성과 상관없이 빠르게 데이터를 찾을 수 있다.
업무적으로 미래 시점 데이터를 미리 입력하는 경우가 없다면, 현재 시점 데이터(=가장 마지막 예를 조회할 때는 between을 사용하기보다 “종료일=9991231” 조건을 사용하는 것이 효과적이다.
여기서는 단일 선분 이력 테이블을 조회할 때의 스캔 효율을 높이는 방법에 대해서만 살펴봤고, 다른 테이블과 between 조인할 때 생기는 성능 이슈와 해법에 대해서는 2장 조인 원리와 활용편에서 다룬다.
(9) Access Predicate와 Filter Predicate
인덱스를 경유해 테이블을 액세스할 때는 아래와 같이 최대 3가지 Predicate 정보가 나타날 수 있다.
- 인덱스 단계에서의 Access Predicate (id=4 access 부분)
- 인덱스 단계에서의 Filter Predicate (id=4 filter 부분)
- 테이블 단계에서의 Filter Predicate (id=1 filter 부분)
인덱스를 경유하지 않고 테이블 전체를 스캔할 때는 아래와 같이 항상 Filter Predicate 단 하나만 나타날 수 있다.
- 테이블 단계에서의 Filter Predicate (id=3 filter 부분)
1번 ‘인덱스 단계에서의 Access Predicate’는 인덱스 스캔 범위를 결정하는 데에 영향을 미치는 조건절을 의미한다. 앞에서 설명했다시피 인덱스 컬럼에 대한 조건절은, 설령 범위 검색 조건을 뒤 따르는 조건(위 쿼리에서 sal >= 1000)이거나 선행 컬럼이 조건에서 누락될지라도(위 쿼리에서 comm) = 300, 액세스 범위를 결정하는 데에 기여하므로 대부분 Access Predicate에 포함된다.
아래 경우에는 인덱스 스캔 범위를 결정하는 데에 전혀 영향을 미치지 않기 때문에 Access Predicate에서 제외된다.
- 좌변 컬럼을 가공한 조건절
- 위 쿼리에서 trim(e.ename) = ‘ALLEN’
- 왼쪽 ‘%’ 또는 양쪽 ‘%’ 기호를 사용한 like 조건절
- 위 쿼리에서 ename like ‘AL%’
- 같은 컬럼에 대한 조건절이 두 개 이상일 때, 인덱스 액세스 조건으로 선택(위 쿼리에서 job like ‘SALE%’) 되지 못한 다른 조건절
- 위 쿼리에서 job between ‘A’ and Z
위와 같은 경우를 제외하면 앞에서 누차 강조했듯이, 수직적 탐색 과정에서 모든 인덱스 컬럼을 비교조건으로 사용한다는 사실을 반드시 기억하기 바란다. 물론 수평적 탐색 종료지점을 결정하는 비교조건으로도 사용된다.
2번 ‘인덱스 단계에서의 Filter Predicate’는 테이블로의 액세스 여부를 결정짓는 조건절을 의미한다. 첫 번째 나타나는 범위 검색 조건 부터 이 후 모든 조건 컬럼들이 여기에 포함되며, 조건절에서 누락된 컬럼 뒤쪽에 놓인 인덱스 컬럼들도 포함한다.
테이블 액세스 단계에서의 Filter Predicate(인덱스를 경유한 3번이나 경유하지 않은 4번 둘 대)는 테이블을 액세스하고 나서 최종 결과 집합으로의 포함 여부를 결정짓는 조건절을 의미한다.
(10) Index Fragmentation
Delete 작업 때문에 인덱스가 불균형( Unbalanced ) 상태에 놓일 수 있다고 설명한 자료들을 볼 수 있다. 즉, 다른 리프 노드에 비해 루트 블록과의 거리가 더 멀거나 가까운 리프 노드가 생길 수 있다는 것인데, 오라클에서 이런 현상은 절대 발생하지 않는다.
B-tree 인덱스의 ‘B’는 Balanced의 약자로서, 인덱스 루트에서 리프 블록까지 어떤 값으로 탐색하더라도 읽는 블록 수가 같음을 의미한다. 즉, 루트로부터 모든 리프 블록까지의 높이( height ) 가 동일하다.
불균형( Unbalanced )은 생길 수 없지만 Index Fragmentation에 의한 Index Skew 또는 Sparse 현상이 생기는 경우는 종종 있고, 이는 인덱스 스캔 효율에 나쁜 영향을 미칠 수 있다.
Index Skew
Index Skew는 인덱스 엔트리가 왼쪽 또는 오른쪽에 치우치는 현상을 말한다. 예를 들어, 아래와 같이 대량의 delete 작업을 마치고 나면 그림 1-53처럼 인덱스 왼쪽에 있는 리프 블록들은 텅 비는 반면 오른쪽 블록들은 꽉 찬 상태가 된다(스크립트 chL17. 참조).
1
2
3
4
5
6
7
SQL> create table t as select rownum no from dual connect by level <= 1000000 ;
SQL> create index t_idx on t(no) potfree 0;
SQL> delete from t where no <= 500000 ;
SQL> commit ; -> 이 시점에 freelist로 반환되지만 인덱스 구조는 그대로 남는다.
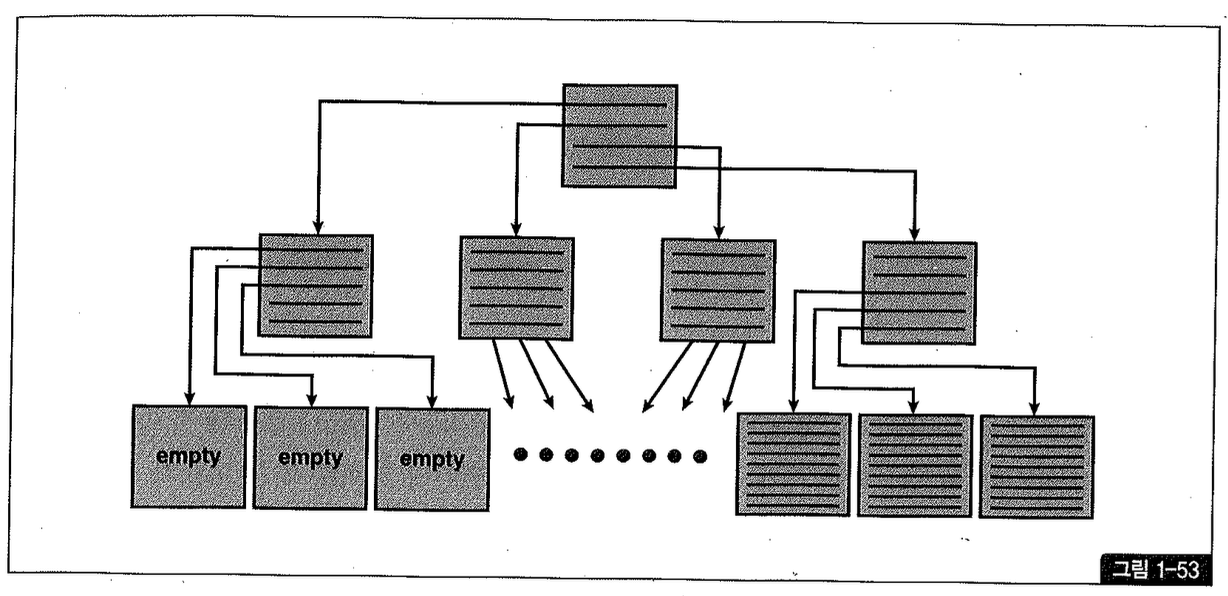
텅 빈 인덱스 블록은 커밋하는 순간 freelist로 반환되지만 인덱스 구조 상에는 그대로 남는다. 상위 브랜치에서 해당 리프 블록을 가리키는 엔트리가 그대로 남아 있어 인덱스 정렬 순서상 그 곳에 입력될 새로운 값이 들어오면 언제든 재사용될 수 있다. (재사용되더라도 이 경우에는 곧바로 freelist에서 제거되지 않으며 나중에 빈 블록을 찾기 위해 freelist를 스캔하는 프로세스에 의해 정리된다. )
새로운 값이 하나라도 입력되기 전 다른 노드에 인덱스 분할이 발생하면 그것을 위해서도 이들 블록이 재사용된다. 이때는 상위 브랜치에서 해당 리프 블록을 가리키는 엔트리가 제거되어 다른쪽 브랜치의 자식 노드로 이동하고, freelist에서도 제거된다.
레코드가 모두 삭제된 블록은 이처럼 언제든 재사용 가능하지만, 문제는 다시 채워질 때까지 인 텍스 스캔 효율이 낮다는 데에 있다.
위와 같은 Index Skew 때문에 성능이 나빠지는 경우는 대개 Index Full Scan 할 때다.
대량의 데이터를 매일 지웠다가 새로 입력하는 통계성 테이블일 때는 Index Skew가 발생하지 않도록 트랜잭션 패턴에 신경을 써야한다.
PK 인덱스 왼쪽에 놓인 상당수 리프 블록들이 delete 문을 통해 모든 레코드가 지워지더라도 커 밋하기 전까지는 freelist로 반환될 수 없다. 따라서 곧바로 insert 과정에서 빈 블록이 많이 필요함에도 앞서 지운 블록들을 사용할 수 없어 새로운 공간을 할당받게된다.
물론 빈 블록들은 그 다음 날 insert 과정에서 재사용되겠지만 delete 문에 의해 지워지는 블록 들이 새로 생긴다. 결국 인덱스 왼쪽의 많은 블록들이 항상 빈 상태로 남아 인덱스 스캔 효율을 떨어뜨리게된다.
반면 아래와 같이 delete 문 직후에 커밋을 수행하면 지워진 블록들이 곧바로 insert 과정에 재 사용된다. Index Skew를 두려워해 트랜잭션을 짧게 정의하는 것이 바람직하지 않지만 이 경우는 일반 사용자가 접근 하지 않는 야 간 에 배 치 프 로 그램 을 통 해 서 만 관 리 되 는 통 계 성 테 이 블 이 므 로 아래와 같이 처리해도 무방할 것이다. (업무적인 중요도와 트랜잭션이 실패했을 때 재생 가능한지 등에 따라 판단하기 바란다. )
1
2
3
4
5
6
7
8
9
delete Ecom 일별고객별판매집계 where 판매일시 < trunc(sysdate) - 2;
commit;
insert into 일별고객별판매집계
select to_char(sysdate,'yymmdd'),고객번호,Sum(판매량),Sum(판매금액) from 판매
where 판매일시 between trunc(sysdate) and trunc(sysdate+1) - 1/24/60/60 group by 고객번호;
commit;
필자가 방문했던 어떤 회사는 문장 단위로 커밋하는데도 아래와 같이 insert 문을 먼저 수행하 는 바람에 Index Skew 현상을 겪고 있었다.
1
2
3
4
5
6
7
8
9
insert into 일별고객별판매집계
select to_char(sysdate, 'yymmdd'),고객번호,Sum(판매량),Sum(판매금액) from 판매
where 판매일시 between trunc(sysdate) and trunc(sysdate+1) - 1/24/60/60 group by 고객번호;
commit;
delete rom일별고객별판매집계 where 판매일시 < trunc(sysdate) - 2;
commit;
insert 문에 의해 Skew가 해소되었다가 곧이은 delete 문에 의해 왼쪽 리프 노드가 또 다시 지워진다. 따라서 insert 문과 delete 문 수행 순서를 바꾸지 않는 한 인덱스 왼쪽 리프 노드는 항상 빈 상태일 것이다.
Index Sparse
Index Sparse는 그림 1-54처럼 인덱스 블록 전반에 걸쳐 밀도(density)가 떨어지는 현상을 말한다.
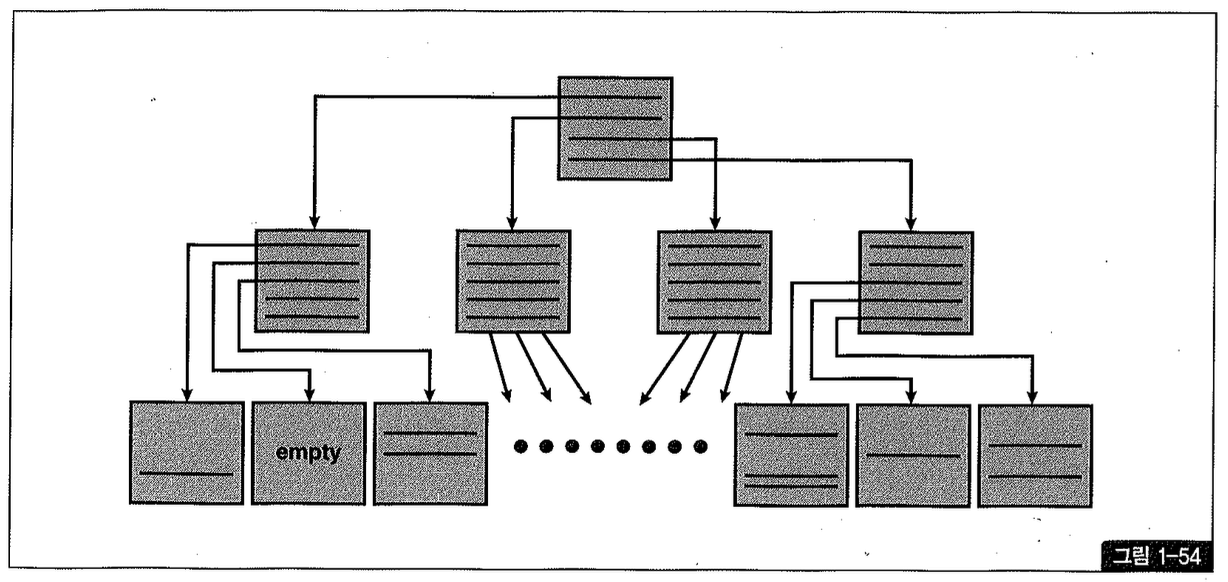
예를들어, 아래와 같은 형태로 delete 작업을 수행하고 나면 tidx 블록의 밀도는 50% 정도밖에 되지 않는다. 100만 건 중 50만 건을 지우고 나서도 스캔한 인덱스 블록 수가 똑같이 2,001개인 것을 확인하기 바란다 (스크립트 Chi-17.t 참조).
지워진 자리에 인덱스 정렬 순서에 따라 새로운 값이 입력되면 그 공간은 재사용되지만 위와 같은 대량의 delete 작업이 있고 난 후 한동안 인덱스 스캔 효율이 낮다는 데에 문제가 있다.
왼쪽, 오른쪽, 중간 어디든 Index Skew처럼 블록이 아예 텅 비면 곧바로 freelist로 반환되어 언제 재사용되지만, Index Sparse는 지워진 자리에 새로운 값이 입력되지 않으면 영영 재사용되지 않을 수도 있다. 총 레코드 건수가 일정한데도 인덱스 공간 사용량이 계속 커지는 것은 대개 이런 현상에 기인한다.
Index Rebuild
Fragmentation 때문에 인덱스 크기가 계속 증가하고 스캔 효율이 나쁠 때는 아래와 같이 coalesce 명령을 수행해주면 된다.
coalesce 명령을 수행하면 인덱스 분할과 반대의 작업이 일어난다. 즉, 여러 인덱스 블록을 하나로 병합(merge)하고, 그 결과로서 생긴 빈 블록들은 freelist에 반환한다16). coalesce 명령을 수행해도 인덱스 세그먼트에 할당된 미사용 공간(HWM 아래쪽에서 freelist에 등록된 블록과 HWM 위쪽 미사용 블록)은 반환되지 않는다. Index Fragmentation를 해소하면서 공간까지 반환하려면 아래와 같이 shrink 명령을 수행하면 된다. 단, shrink는 ASSM에서만 작동한다.
SOL> alter index t_idx shrink space;
- 인덱스 분할은 트랜잭션 중에 동적으로 일어나지만 인덱스 병합은 명령어를 통해 수동으로만 가능하다.
만약 아래와 같이 compact 옵션을 지정하면 공간은 반환하지 않으므로 coalesce와 같은 명령어가 된다.
SOL> alter index t_idx shrink space compact;
coalesce나 shrink는 레코드를 건건이 지웠다가 다시 입력하는 방식을 사용하므로 작업량이 많을 때는 rebuild 명령을 사용하는 편이 나을 수 있다.
1
2
SQL> alter index t_idx rebuild;
SQL> alter index t_idx rebuild online;
위와 같은 방식으로 인덱스 구조를 슬림(slim)화하면 저장 효율이나 스캔 효율은 좋아지지만 일반적으로17) 인덱스 블록에는 어느정도 공간을 남겨두는 것이 좋다. 인덱스 블록에 공간이 전혀 없으면 인덱스 분할이 자주 발생해 DMIL, 성능을 떨어뜨리기 때문이다18).
- Right-Growing 인덱스가 아닌 경우를 말한다. 맨 우측 리프 블록에만 값이 입력되는 Right-Growing 인덱스일 때는 pctfree를 0으로 설정하는 것이 좋다.
- 1권 2장 5절 ‘오라클 Lock’ 중 ‘(5) TX Lock > 인덱스 분할’ 참조
인덱스 분할 때문에 Shared 모드 enㅂ: TX - index contention 대기 이벤트가 자주 나타난다면 pctfree를 높게 설정하는 것을 고려할 수 있다! 하지만 pctfree를 높게 설정하는 것만으로는 전혀 효과가 없다. 인덱스에서의 pctfree는 인덱스를 처음 생성하거나 rebuild 할 때만 적용되기 때문이다. 따라서 인덱스 분할에의한 경합을 줄이려면 pctfree를 높이고 나서 인덱스를 rebuild 해야 한다.
하지만 그 효과는 일시적이다. 언젠가 빈 공간이 다시 채워지기 때문이며, 결국 적당한 시점마다 rebuild 작업을 반복하지 않는 한 근본적인 해결책이 되지는 못한다.
인덱스를 rebuild 하는데 걸리는 시간과 부하도 무시할 수 없다. 그나마 서비스 다운타임( planned downtime )을 확 보 할 수 있는 상황이라면 적당한 pctfree 옵션과 함께 인덱스를 rebuild 해서 나쁠 것은 없지만, 24시간 가용성이 요구되는 시스템이라면 얘기가 다르다. 인덱스를 rebuild 하는 동안 시스템에 주는 부하가 적지 않고, online rebuild 기능(coalesce, Shink 포함)을 이용하더라도 트랜잭션에 다소 경합을 일으키기 때문이다.
인덱스 스캔 효율 측면에서 보더라도, 대량의 delete 작업이 없으면 주기적으로 rebuild하지 않더라도 그다지 나쁘지 않다.
따라서 아래와 같이 예상효과가 확실할 때만 인덱스 rebuild를 고려하는 것이 바람직하다.
- 인덱스 분할에의한 경합이 현저히 높을 때
- 자주 사용되는 인덱스 스캔 효율을 높이고자 할 때. 특히 NIL 조인에서 반복 액세스되는 인덱스 높이(meigh 가 증가했을 때
- 대량의 delete 작업을 수행한 이후 다시 레코드가 입력되기까지 오랜 기간이 소요될 때
- 총 레코드 수가 일정한데도 인덱스가 계속 커질 때
| 인덱스 freelist |
|---|
| 테이블에서의 pctfree와 pctused는 각각 freelist에서 제외되는 시점과 다시 등록되는 시점을 지정하는 파라미터다. 테이블은 Heap 방식으로 데이터를 입력하므로 매번 freelist를 참조해 데이터 삽입이 가능한 블록을 찾아야 한다. 반면, 인덱스는 정렬된 구조로 자료를 삽입하므로 값이 입력될 때마다 freelist를 참조하지 않아도 된다. 인덱스 구조를 탐색해 정렬 순서에 따라 정해진 곳에 레코드를 삽입하기 때문이며, 인덱스 freelist는 인덱스 분할로 빈 블록이 필요할 때만 참조한다. 이처럼 테이블과 인덱스간에 pctfree의 의미와 작동방식이 서로 다르며, 인덱스에 pctused 파라미터가 없는 것도 특징적이다. ##### PCTFREE 테이블에서의 pctfree는 블록에 더 이상 insert가 발생하지 못하도록 freelist로부터 제외되는 시점을 지정하는 것이다. 그렇게 남겨진 빈 공간은 나중에 update를 위해 사용된다. 인덱스에서의 pctfree는 용도가 다르다. 인덱스가 생성되는 시점에 공간을 꽉 채워두면 나중에 인덱스 분할이 빈번하게 발생하므로 이를 방지하려고 pct free가 필요하다. 이 옵션은 인덱스 최초 생성 또는 재생성 시점에만 적용되며, 지정한 비율만큼 공간을 남겨두었다가 나중에 insert를 위해 사용된다. ##### PCTUSED freelist에서 제거된 테이블 블록에 빈 공간이 일정 수준 이상 확보됐을 때 만 다시 freelist에 등록되도록 하기 위해 pct used 파라미터가 필요하다. insert, delete가 자주 발생하는 테이블에 pctfree와 pctused 합이 100에 가깝다면 freelist 변경이 자주 발생하게 된다. 예를 들어, pctfree가 10이고 pctused가 80이면 freelist에서 제거된 블록에 10% 정도 delete가 발생하는 순간 해당 블록을 다시 freelist에 등록해야 한다. 반대로, delete가 적게 발생한다면 pctfree와 pctused를 100에 가깝도록 설정해야 테이블 블록 저장 효율을 높일 수 있다. 인덱스에는 Pctused 파라미터가 아예 없다. 이유는, 인덱스에서 빈 공간은 항상 재사용 가능하기 때문이다. 예를 들어, 1부터 10까지의 값을 입력하면 인덱스에는 1부터 10까지의 값이 정렬된 채로 입력된다. 이때 5를 지우고 commit한 후에 5를 다시 입력하면 앞서 지워진 그 공간을 남겨둘 하등이 유가 없다. 바로그 곳에 삽입하면 된다. 정리하면, 테이블에서의 freelist는 insert가 가능한 블록을 관리한다. 100 - pctfree 만큼의 공간이 차면 freelist에서 제거되고, pctused 만큼만 남기고 레코드가 모두 지워질 때 다시 freelist에 등록된다. 인덱스에서의 freelist는 인덱스 분할에 사용 가능한 빈 블록들을 관리한다. 기억할 점은, delete에 의해 비워진 인덱스 블록은 커밋 시점에 freelist에 반환되지만 insert 시점에 다시 값이 입력되더라도 곧 바로 freelist에서 제거되지 않는다는 사실이다. freelist에 그대로 두었다가 인덱스 분할 때문에 freelist를 스캔하는 프로세스에 의해 정리된다. 즉, freelist에서 얻은 블록이 비어있지 않으면 다른 블록을 재요청하기 전에 일단 해당 블록을 freelist에서 제거하는 방식이며, 이는 커밋 시점에 수행해야 할 일량을 최소화하기 위한 것이다. 만약 값을 입력하고 커밋할 때마다 freelist를 관리해주어야 한다면 fastcommit 메커니즘에 문제가 생길지도 모른다. |