<오라클 성능 고도화 원리와 해법2> Ch02-01 Nested Loops 조인
본서는 SQL 기초를 다루는 책이 아니므로 조인의 기본 개념은 설명하지 않는다. 오라클이 내부적으로 어떻게 조인을 수행하는지 원리를 설명하고, 그런 원리를 바탕으로 어떻게 쿼리 수행 성능을 향상시킬지 활용점을 밝히는 데 집중할 것이다.
오라클 성능 고도화 원리와 해법2 - Ch02-01 Nested Loops 조인
(1) 기본 메커니즘
프로그래밍을 해 본 독자라면 누구나 아래 중첩 루프문(Nested Loop)의 수행 구조를 이해할 것이고, 그렇다면 Nested Loops 조인(이하 NL 조인)도 어렵지 않게 이해할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
< C, JAVA >
for (i=0; i<100; i++){ // -- outer loop
for(j=0; j<100; j++){ // -- inner loop
// Do Anything ...
}
}
< PL/SQL >
for outer in 1..100 loop
for inner in 1..100 loop
dbms_output.put_line(outer || ' : ' || inner);
end loop;
end loop;
위 중첩 루프문과 같은 수행 구조를 사용하는 NL 조인이 실제 어떤 순서로 데이터를 액세스하는지 아래 PL/SQL문이 잘 설명해준다(스크립트 ch2.01.kt 참조).
1
2
3
4
5
6
7
8
9
begin
for outer in (select deptno, empno, rpad(ename, 10) ename from emp)
loop -- outer 루프
for inner in (select dname from dept where deptno = outer.deptno)
loop -- inner 루프
dbms_output.put_line(outer.empno || ': ' || outer.ename || ' : ' || inner.dname);
end loop;
end loop;
end;
위 PL/SQL문은 아래 쿼리와 100% 같은 순서로 데이터를 액세스하고, 데이터 출력 순서도 같다. 내부적으로 (= Recursive하게) 쿼리를 반복 수행하지 않는다는 점만 다르다.
1
2
3
select /*+ ordered use_nl (d) */ e.empno, e.ename, d.dname
from emp e, dept d
where d.deptno = e.deptno;
사실 뒤에서 설명하는 소트머지 조인과 해시 조인도 각각 Sort Area와 Hash Area에 가공한 데이터를 이용한다는 점만 다를 뿐 기본적인 조인 프로세싱은 다르지 않다.
(2) 힌트를 이용해 NL 조인을 제어하는 방법
1
2
3
select /*+ ordered use_nl(e) */ *
from dept d, emp e
where e.deptno = d.deptno
ordered 힌트는 from 절에 기술된 순서대로 조인하라고 옵티마이저에게 지시할 때 사용하고, use_nl 힌트는 NL 방식으로 조인하라고 지시할 때 사용한다. 위에서는 ordered와 use_nl(e) 힌트를 같이 사용했으므로 dept 테이블(Outer 테이블)을 기준으로 emp 테이블(Inner 테이블)과 조인할 때 NL 방식으로 조인하라는 뜻이 된다.
| Outer 테이블, Inner 테이블 |
|---|
| 조인을 설명하려면 우선 Outer와 Inner에 대한 용어 정의를 명확히 할 필요가 있다. 우선, Outer와 Inner라는 용어가 Outer 조인에 사용되는 두 테이블을 지칭할 때만 사용하는 것이 아님을 이해하기 바란다. 그런데 트레이스 파일에 사용된 용어가 표준 용어는 아니므로 크게 혼란스러워할 필요는 없다. 이벤트 트레이스는 오라클 개발자들이 디버깅 용도로 개발해 사용되어온 것이고, 가장 오래된 NL 조인의 틀에 맞추다 보니 그렇게 된 것이라고 이해하면 된다. 본서에서는 아래와 같이 정의하고 설명을 진행하기로 하겠다. 참고로, 해시 조인에서도 Build Input을 드라이빙(Drving) 테이블이라고 표현하기도 하지만 소트머지 조인에서는 그런 표현을 쓰지 않는다. |
위에서는 두 개 테이블을 조인하고 있지만 세 개 이상을 조인할 때는 힌트를 아래처럼 사용하는 것이 올바른 사용법이다.
1
2
3
select /*+ ordered use_nl(B) use_nl(C) use_hash(D) */ *
from A, B, C, D
where ......
아래는 ordered나 leading 힌트를 기술하지 않았으므로 네 개 테이블을 NL 방식으로 조인하되 순서는 옵티마이저가 스스로 정하도록 맡기는 것이다.
1
2
3
select /*+ use_nl(A, B, C, D) */ *
from A, B, C, D
Where ......
(3) NL 조인 수행 과정 분석
자! 이제 NL 조인의 기본 알고리즘과 이를 제어하는 힌트 사용법까지 이해했다.
여기서 기억할 것은, 각 단계를 완료하고 나서 다음 단계로 넘어가는 게 아니라 한 레코드씩 순차적으로 진행한다는 사실이다. 단, orderby는 전체 집합을 대상으로 정렬해야 하므로 작업을 모두 완료한 후에 다음 오퍼레이션을 진행한다.
그림2-2를 보고나면 NL 조인의 수행 절차를 좀 더 명확히 이해할 수 있다.
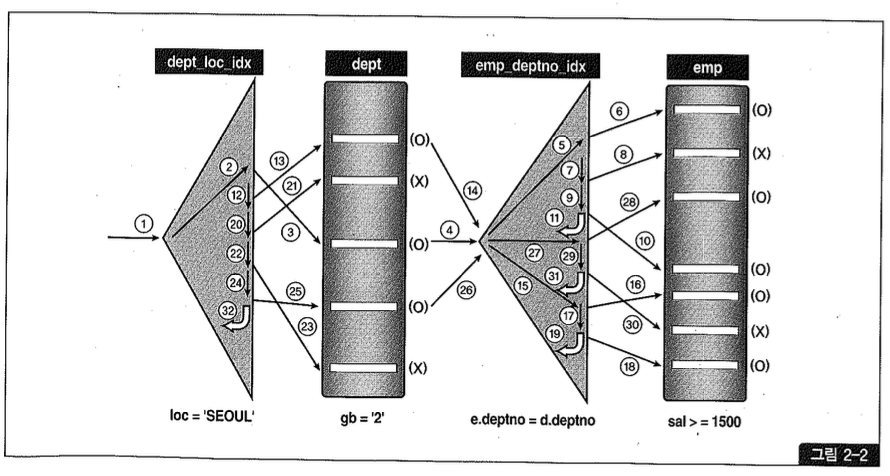
OLTP 시스템에서 조인을 튜닝할 때는 일차적으로 NL 조인부터 고려하는 것이 올바른 순서다. 우선, NL 조인의 기본 메커니즘을 따라 각 단계의 수행 일량을 분석해 과도한 Random 액세스가 발생하는 지점을 파악한다. 조인 순서를 변경해 Random 액세스 발생량을 줄일 수 있는 경우가 있고, 그렇지 못할 때는 인덱스 컬럼 구성을 변경하거나 다른 인덱스의 사용을 고려해야 한다.
여러 가지 방안을 검토한 결과 NL 조인이 효과적이지 못하다고 판단될 때 해시 조인이나 소트 머지 조인을 검토한다.
(4) NL 조인의 특징
오라클은 블록 단위로 I/O를 수행하며, 하나의 레코드를 읽으려고 블록을 통째로 읽는 Random 액세스 방식은 설령 메모리 버퍼에서 빠르게 읽더라도 비효율이 존재한다. 그런데 NL 조인의 첫 번째 특징이 Random 액세스 위주의 조인 방식이라는 점이다. 따라서 인덱스 구성이 아무리 완벽하더라도 대량의 데이터를 조인할 때 매우 비효율적이다.
두 번째 특징은, 조인을 한 레코드씩 순차적으로 진행한다는 점이다. 첫 번째 특징 때문에 대용량 데이터 처리시 매우 치명적인 한계를 드러내지만, 반대로 이 두 번째 특징 때문에 아무리 대용량 집합이더라도 매우 극적인 응답 속도를 낼 수 있다. 부분 범위 처리가 가능한 상황에서 그렇다. 그리고 순차적으로 진행하는 특징 때문에 먼저 액세스되는 테이블의 처리 범위에 의해 전체 일량이 결정된다.
다른 조인 방식과 비교했을 때 인덱스 구성 전략이 특히 중요하다는 것도 NL 조인의 중요한 특징이다. 조인 컬럼에 대한 인덱스가 있는지 없느냐, 있다면 컬럼이 어떻게 구성됐느냐에 따라 조인 효율이 크게 달라진다.
이런 여러 가지 특징을 종합할 때, NL 조인은 소량의 데이터를 주로 처리하거나 부분 범위 처리가 가능한 온라인 트랜잭션 환경에 적합한 조인 방식이라고 할 수 있다.
(5) NL 조인 튜닝 실습
지금부터 SQL 트레이스 분석을 통해 실제 튜닝하는 과정을 실습해 보자.
jobs_max_sal_ix 인덱스를 스캔하고서 jobs 테이블을 액세스한 횟수가 278인데, 테이블에서 job_type=’A’ 조건을 필터링한 결과는 3건에 그친다. 불필요한 테이블 액세스를 많이 한 셈이고, 이처럼 테이블을 액세스한 후에 필터링되는 비율이 높다면 인덱스에 테이블 필터 조건 컬럼을 추가하는 것을 고려해볼 필요가 있다.
jobs_max_sal_ix 인덱스에 job_type 컬럼을 추가하고서 트레이스를 다시 확인해보니 아래와 같이 불필요한 테이블 액세스가 없어졌다.
Rows에 표시된 숫자만 보면 비효율적인 액세스가 없어 보이지만 테이블을 액세스하기 전 인덱스 스캔 단계에서의 일량을 확인하지 못했으므로 튜닝이 끝났다고 볼 수 없다.
여기서 보면 jobs_max_sal_ix 인덱스로부터 3건을 리턴하기 위해 인덱스 블록을 1,000 개 읽은 것을 알 수 있다.
튜닝 방법은? jobs_max_sal_ix 인덱스 컬럼 순서를 조정해 [job_type + max_salary] 순 으로 구성해 주면 된다. (물론 다른 쿼리에 미치는 ‘영향도 분석’ 이 선행 되어야한다.)
문제는 jobs 테이블을 읽고나서 employees 테이블과의 조인 시도 횟수다. 1,278번 조인 시도를 했지만 최종적으로 조인에 성공한 결과 집합은 5건 뿐이다.
이럴 때는 조인 순서를 바꾸는 것을 고려해볼 수 있다. 만약 hiredate 조건절에 부합하는 레코드가 별로 없다면 튜닝에 성공할 가능성이 높다.
하지만 그 반대의 결과가 나타날 수도 있다. 위에서 employees와 조인 후에 5건으로 줄어든 것은 jobs로부터 넘겨받는 job id와 hire_date 두 컬럼을 조합했을 때 그런 것이지 hire_date 단독으로 조회했을 때는 데이터량이 생각보다 많을 수 있기 때문이다.
조인 순서를 바꾸어도 별 소득이 없다면 2절과 3절에서 설명할 소트머지 조인과 해시 조인을 검토해봐야 한다.
(6) 테이블 Prefetch
지금부터 NL 조인과 관련된 몇 가지 확장 메커니즘을 살펴보자.
우선, 오라클 9.1부터 NL 조인 실행 계획에 변화가 생겼다. 아래와 같이 인덱스 rowid에 의한 Inner 테이블 액세스가 Nested Loops 위쪽에 표시되곤 하는데, 이는 해당 테이블 액세스 단계에 Prefetch 기능이 적용되었음을 표현하기 위함이다. 테이블 Prefetch에 대해서는 1권 6장에서 이미 설명하였다.

테이블 Prefetch를 제어하는 파라미터 중 하나인 _table_lookup_prefetch_size를 0으로 설정하면, 똑같은 SQL인데 아래와 같이 전통적인 방식의 NL 조인 실행 계획으로 되돌아간다.

새로운 포맷의 실행 계획이 나타난다고 항상 테이블 Prefetch가 작동하는 것은 아니다. 단지 그 기능이 활성화되었음을 의미할 뿐이다. Prefetch 방식으로 디스크 블록을 읽었는데 실제 버퍼 블록 액세스로 연결되지 못한 채 메모리에서 밀려나는 비율이 높다면, 실행 계획은 그대로인 채 내부적으로 기능이 비활성화되기 때문이다.
참고로, Prefetch 기능이 실제 작동할 때면 db file sequential read 대기 이벤트 대신 db file parallel reads 대기 이벤트가 나타난다.
Prefetch는 디스크 I/O와 관련 있다. 디스크 I/O를 수행하려면 비용이 많이 들기 때문에 한 번의 I/O Call이 필요한 시점에, 곧이어 읽을 가능성이 큰 블록들을 캐시에 미리 적재해두는 기능이다. 한 번의 I/O Call로써 여러 Single Block I/O를 동시에 수행한다. 이 기능에 대한 자세한 설명은 1권을 참조하기 바란다.
NL 조인에서 항상 새 포맷의 실행 계획이나 타날 수 있는 것은 아니다. 기본적으로 Outer 쪽 인덱스를 Unique Scan 할 때는 작동하지 않는다. 이 경우를 제외하면 언제든 새 포맷의 실행 계획이 나타날 수 있는데, 정리하면 다음과 같다.
- Inner 쪽 Non-Unique 인덱스를 Range Scan 할 때는 테이블 Prefetch 실행 계획이 항상 나타난다.
- Inner 쪽 Unique 인덱스를 Non-Unique 조건(모든 인덱스 구성 컬럼이 조건이 아닐 때)으로 Range Scan 할 때도 테이블 Prefetch 실행 계획이 항상 나타난다.
- Inner 쪽 Unique 인덱스를 Unique 조건(모든 인덱스 구성 컬럼이 ‘=’ 조건)으로 액세스 할 때도 테이블 Prefetch 실행 계획이 나타날 수 있다. 이때 인덱스는 Range Scan으로 액세스한다. 테이블 Prefetch 실행 계획이 안 나타날 때는 Unique Scan으로 액세스한다.
(7) 배치 I/O
오라클 11g에서 시작된 배치 I/O 메커니즘에 대해서는 아직 공식적으로 알려진 바가 없지만, 아래 실행 계획이 의미하는 바와 같이 Inner 쪽 인덱스만으로 조인을 하고 나서 테이블과의 조인(나중에 일괄 처리하는 메커니즘)인 것으로 추정된다.
테이블 액세스를 나중에하지만 부분 범위 처리는 정상적으로 작동한다. 따라서 인덱스와의 조인을 모두 완료하고 나서 테이블을 액세스하는 것이 아니라 일정량씩(아마도 Fetch Call 단위) 나누어 처리하는 것을 알 수 있다.
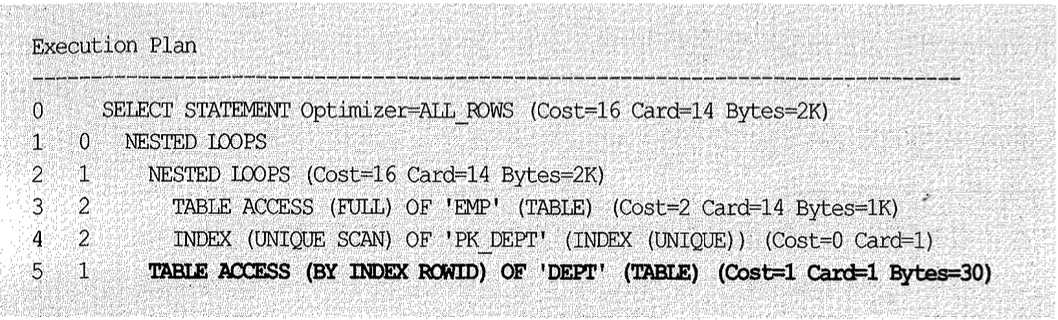
배치 I/O 방식을 표현한 위 실행 계획을 풀어서 설명하면 아래와 같다:
- 드라이빙 테이블에서 일정량의 레코드를 읽어 Inner 쪽 인덱스와 조인하면서 중간 결과 집합을 만든다.
- 중간 결과 집합이 일정량 쌓이면 Inner 쪽 테이블 레코드를 액세스한다. 이때 테이블 블록을 버퍼 캐시에서 찾으면 바로 최종 결과 집합에 담고, 못 찾으면 중간 집합에 남겨둔다.
- 2번 과정에서 남겨진 중간 집합에 대한 Inner 쪽 테이블 블록을 디스크로부터 읽는다. 이때 Multiple Single Block I/O 방식을 사용한다.
- 버퍼 캐시에 올라오면 테이블 레코드를 읽어 최종 결과 집합에 담는다.
- 모든 레코드를 처리하거나 사용자가 Fetch Call을 중단할 때까지 1~4번 과정을 반복한다.
이것은 Outer 테이블로부터 액세스되는 Inner 쪽 테이블 블록에 대한 디스크 I/O Call 횟수를 줄이기 위해, 테이블 Prefetch에 이어 추가로 도입된 메커니즘이다. 이 메커니즘이 작동하도록 유도하려면 nlilbatching 힌트를 사용하면 된다. 만약 이 방식을 원치 않을 때는 nonlilbatching 또는 nlipretetch 힌트를 사용하면 된다. 그러면 테이블 Prefetch 방식으로 전환된다.
주목할 것은, 위 방식을 사용할 때 Inner 쪽 테이블 블록이 모두 버퍼 캐시에서 찾아지지 않으면(버퍼 캐시 히트율 < 10%) 즉, 실제 배치 I/O가 작동한다면 데이터 정렬 순서가 달라질 수 있다는 사실이다. 모두 버퍼 캐시에서 찾을 때는(버퍼 캐시 히트율 = 10%) 이전 메커니즘과 똑같은 정렬 순서를 보인다. 테이블 Prefetch 방식이나 전통적인 방식으로 NL 조인할 때는 디스크 I/O가 발생하든 안 하든 데이터 정렬 순서가 항상 일정하다.
(8) 버퍼 Pinning 효과
앞서 설명한 테이블 Prefetch와 배치 I/O 기능이 도입된 시점과 맞물려 버퍼 Pinning 기능에 변화가 생기다보니 9i와 11g에서 나타난 NL 조인 실행 계획 변화를 버퍼 Pinning 효과로 설명하는 자료들을 종종 볼 수 있는데, 이 둘 간에 직접적인 연관성은 없다.
8i에서 나타난 버퍼 Pinning 효과
테이블 블록에 대한 버퍼 Pinning 기능이 작동하기 시작했다. 단, 하나의 버퍼 블록만 Pinning 한다. 그리고 하나의 Fetch Call을 완료하는 순간 Pin을 해제한다. 자세한 수행 원리는 1장 4절 (2) 항 후반부를 참조하기 바란다.
이 기능은 NL 조인에서 Non-Unique 조건으로 Inner 쪽 테이블을 액세스할 때도 똑같이 작용한다. 따라서 Inner 쪽 인덱스를 통해 액세스되는 테이블 블록이 계속 같은 블록을 가리키면 논리 VOI(CR Gets)가 추가로 발생하지 않는다.
중요한 사실은, 하나의 Outer 레코드에 대한 Inner 쪽과의 조인을 마치고 다른 레코드를 읽기 위해 Outer 쪽으로 돌아오는 순간 Pin을 해제한다는 점이다. 따라서 8i에서 Pinning 기능을 정확히 테스트하려면 Inner 쪽을 한 번 액세스할 때마다 여러 개의 테이블 레코드를 읽도록 데이터를 구성해야 한다. 클러스터링 패터가 좋아야 그 효과도 확실하며, 9i 이상 버전에서도 마찬가지다. AL 조인에서도 하나의 Fetch Call을 완료하면 Pin을 해제한다.
9i에서 버퍼 Pinning 효과
9i부터 Inner 쪽 인덱스 루트 블록에 대한 버퍼 Pinning 효과가 나타나기 시작했다. 단, 두 번째 액세스되는 순간 Pinning 한다.
테이블 블록 버퍼에 대한 Pinning도 8i와 똑같이 작동한다. 앞에서도 언급했지만 Inner 쪽을 한 번 액세스할 때마다 Non-Unique 인덱스로 여러 개 테이블 레코드를 읽을 때 라야 이 기능이 효과를 발휘한다. 9i부터 Inner 쪽이 Non-Unique 인덱스일 때는 테이블 액세스가 항상 NIL 조인 위 쪽에 올라가므로 (~ 테이블 Prefetch 포맷) 이 때는 항상 버퍼 Pinning 효과가 나타나는 셈이다.
반면, 테이블 Prefetch에서 설명했듯이 Inner 쪽 Unique 인덱스를 Unique 조건으로 액세스할 때는 테이블 액세스가 NL 조인 위쪽으로 잘 올라가지 않는다. 그리고 이 때는 Unique 액세스이므로 Inner 쪽에서 한 건만 읽고 바로 Outer 테이블 쪽으로 돌아간다. 따라서 버퍼 Pinning 효과가 나타날 수가 없다.
그러므로 테이블 액세스가 NIL 조인 위 쪽으로 올라가는 9i에서의 실행 계획 변화를 버퍼 Pinning 효과와 연관시켜 해석하는 오류를 범하기 쉽다.
Inner 쪽 Unique 인덱스를 Unique 조건으로 액세스할 때도 테이블 액세스가 NIL 조인 위 쪽으로 올라가는 경우가 있다고 했고, 그냥 지나쳐왔지만 그때의 버퍼 Pinning 효과를 이미 앞에서 보았다. (6)항에서 테이블 Prefetch를 설명하면서 예시했던 트레이스 결과에서 ‘지분 보고’ 테이블을 NL 조인 아래쪽에서 액세스할 때보다 위쪽에서 액세스할 때 53개 블록을 덜 읽은 것을 확인하기 바란다. 총 332번 액세스하는 동안 NIL 조인 아래쪽에 있을 때는 332(=98-606)개 블록을 읽었고, 위 쪽에 있을 때는 279(=1231-952)개 블록을 읽었다.
10g에서 버퍼 Pinning 효과
Inner 쪽 인덱스 루트 블록과 테이블 블록을 Pinning 하는 기능이 여전히 작동하면서도 한 가지 새로운 기능이 추가되었다. Inner 쪽 테이블을 Index Range Scan을 거쳐 NL 조인 위쪽에서 액세스할 때는, 하나의 Outer 레코드에 대한 Inner 쪽과의 조인을 마치고 Outer 쪽으로 돌아와도 테이블 블록에 대한 Pinning 상태를 유지한다.
만약 Inner 쪽 테이블이 한 블록 뿐일 때 10g에서의 새로운 버퍼 Pinning 기능이 작동한다면 NIL 조인이 진행되는 동안 논리적인 블록 I/O는 단 1회만 발생할 것이다.
11g에서 나타난 버퍼 Pinning 효과
1장 5절(5)항에서 설명한 바와 같이 11g에서는 User Rowid로 테이블 액세스할 때도 버퍼 Pinning 효과가 나타난다.
또한 NL 조인에서 Inner 쪽 루트 아래 인덱스 블록들도 Pinning하기 시작했다. 배치 I/O 기능이 나타남과 동시에 이 기능이 추가되다 보니 11g에서의 NIL 조인 실행 계획 변화가 인덱스 블록 버퍼 Pinning과 관련 있다고 오해하기 쉽다.
nonlilbatching 또는 niprefetch 힌트를 사용해 테이블 Prefetch 포맷으로 실행 계획을 유도해보면 이때도 인덱스 블록 IVO가 적게 나타나는 것을 관찰할 수 있다. 즉, 인덱스 블록 버퍼 Pinning 효과는 배치 I/O 실행 계획과 상관없이 나타난다.