<오라클 성능 고도화 원리와 해법2> Ch02-03 해시 조인
오라클 성능 고도화 원리와 해법2 - Ch02-03 해시 조인
(1) 기본 메커니즘
7.3 버전에서 처음 소개된 해시 조인은, 소트 머지 조인과 NIL 조인이 효과적이지 못한 상황에 대한 대안으로 개발되었다. 해시 조인은 둘 중 작은 집합(Build Input)을 읽어 Hash Area에 해시 테이블을 생성하고, 반대쪽 큰 집합(Probe Input)을 읽어 해시 테이블을 탐색하면서 조인하는 방식이다(그림2-8).
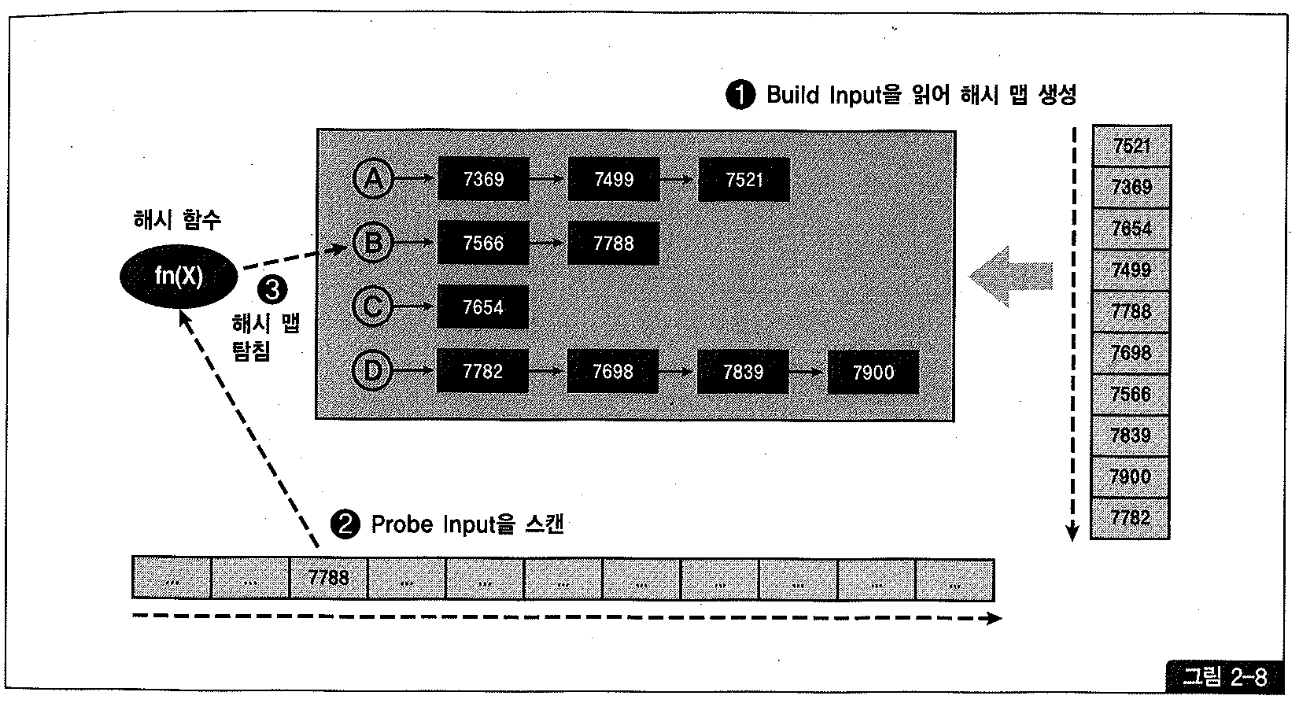
해시 테이블을 생성할 때 해시 함수를 사용한다. 즉, 해시 함수에서 반환받은 버킷 주소로 찾아가 해시 체인에 엔트리를 연결한다.
해시 테이블을 탐색할 때도 해시 함수를 사용한다. 즉, 해시 함수에서 반환받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾는다.
해시 조인은, NIL 조인 처럼 조인 과정에서 발생하는 Random 액세스 부하가 없고7) 기존 소트 머지 조인처럼 조인 전에 미리 양쪽 집합을 정렬하는 부담도 없다. 다만, 해시 테이블을 생성하는 비용이 수반된다. 따라서 Build Input이 작을 때라야 효과적이다.
- 해시 조인도 양쪽 집합을 읽는 과정에서 인덱스를 이용한다면 Random 엑세스가 발생한다.
구체적으로 말해, PGA 메모리에 할당되는 Hash Area(hash_area_size 참조)는 충분히 작아야 한다(〜In-Memory 해시 조인). 만약 Build Input이 Hash Area 크기를 초과한다면 디스크에 썼다가 다시 읽어들이는 과정을 거치기 때문에 성능이 많이 저하된다.
Build Input으로 선택된 테이블이 작은 것도 중요하지만 해시 키 값으로 사용되는 컬럼에 중복 값이 거의 없을 때라야 효과적이다. 이유는 뒤에서 자세히 설명한다.
아래는 해시 조인의 처리 메커니즘을 PL/SQL 구문으로 표현한 것이다(스크립트 Ch2_01.txt 참조).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
create cluster h# (bucket number ) hashkeys 16
hash is mod (bucket, 16); - > 클러스터( =버킷)를결정하기위해사용할해시함수
create table dept_hashtable (bucket number, deptno number (2), dname varchar2 (14) )
cluster h# (bucket);
insert into dept hashtable
select mod (deptno, 16) bucket, deptno, dname from dept;
declare
1 bucket number;
begin
for outer in (select deptno, empno, rpad (ename, 10) ename from emp)
1000 -- outer 루프
1 bucket: =mod(outer.deptno,1 6) :) 해시함수를적용해클러스터(=버킷)확인 for inner in (select deptno, aname from dept hashtable
wher ebucket=1bucke t클 러스터(=버킷)에서탐색
and deptno =outer.deptho)
100p -- inner 루프
doms output. put _nile outer. empno|' : I' louter, enamel' : 'Ilinner.dname) ; end loop;
end loop;
end;
/
NL 조인과 비교하면, Inner 루프가 Hash Area에 미리 생성해 둔 해시 테이블(또는 해시 맵)을 이용한다는 점만 다르다. 해시 테이블을 만드는 단계는 전체 범위 처리가 불가피하지만 반대쪽 Probe Input을 스캔하는 단계는 NL 조인처럼 부분 범위 처리가 가능하다.
해시 조인이 인덱스 기반의 NL 조인보다 빠른 결정적인 이유는, 해시 테이블이 PGA 영역에 할당된다는데에 있다. NL 조인은 Outer 테이블에서 읽히는 레코드마다 Inner 쪽 테이블 버퍼 캐시 탐색을 위해 래치 획득을 반복하지만, 해시 조인은 래치 획득 과정 없이 PGA에서 빠르게 데이터를 탐색한다.
(2) 힌트를 이용한 조인 순서 및 Build Input 조정
해시 조인을 할 때의 실행 계획은 아래와 같다. HASH JOIN의 자식 노드 중 위쪽(dep)이 Build Input이고, 아래쪽(emp)이 Probe Input이다.
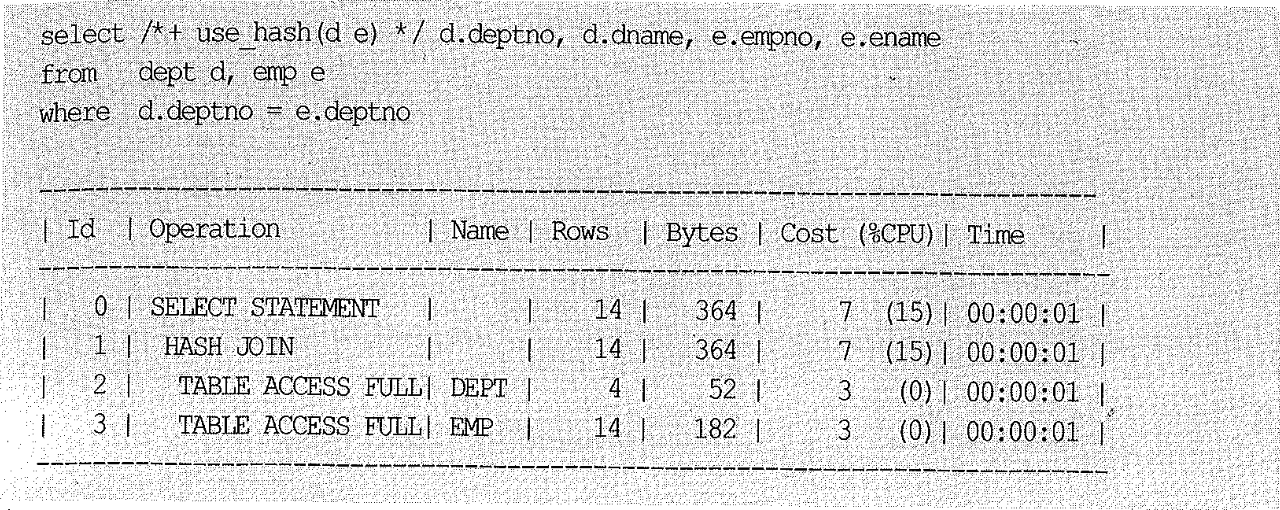
위에서는 use_hash 힌트만을 사용했으므로 Build Input을 옵티마이저가 선택했다. dept가 선택된 이유는 통계 정보상 더 작은 테이블이기 때문이다.
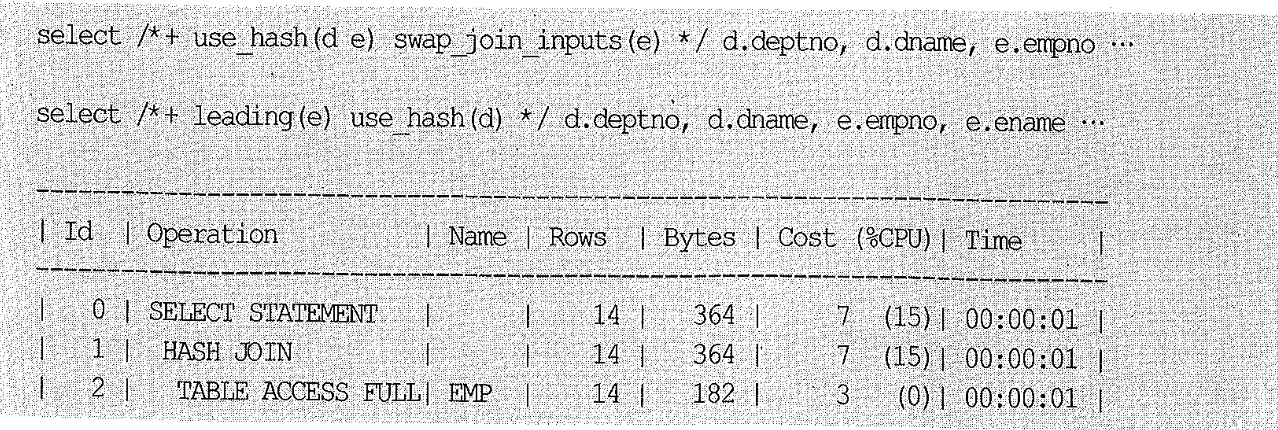
Build Input을 사용자가 직접 선택하고자 할 때는 아래와 같이 swap_join_inputs 힌트를 사용하면 되지만, 단 두 개 테이블을 해시 조인할 때는 ordered나 leading 힌트를 사용해도 된다.

(3) 두 가지 해시 조인 알고리즘
오라클은 해시 조인을 위해 두 가지 알고리즘을 사용하는데, 둘 간의 처리 메커니즘이 어떻게 다른지 살펴보자.
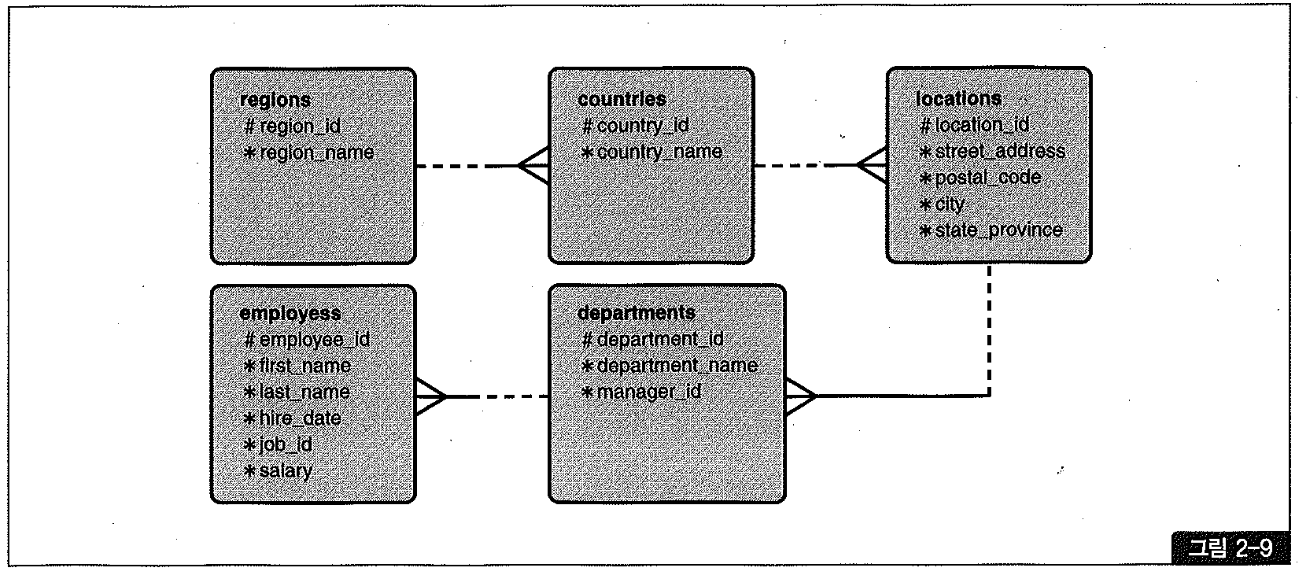
그림2-9는 오라클 설치 시 기본적으로 생성되는 HR 스키마에 있는 테이블들을 Reverse 모델링한 것이다. 아래 쿼리와 실행 계획을 분석해보자.
첫 번째 알고리즘

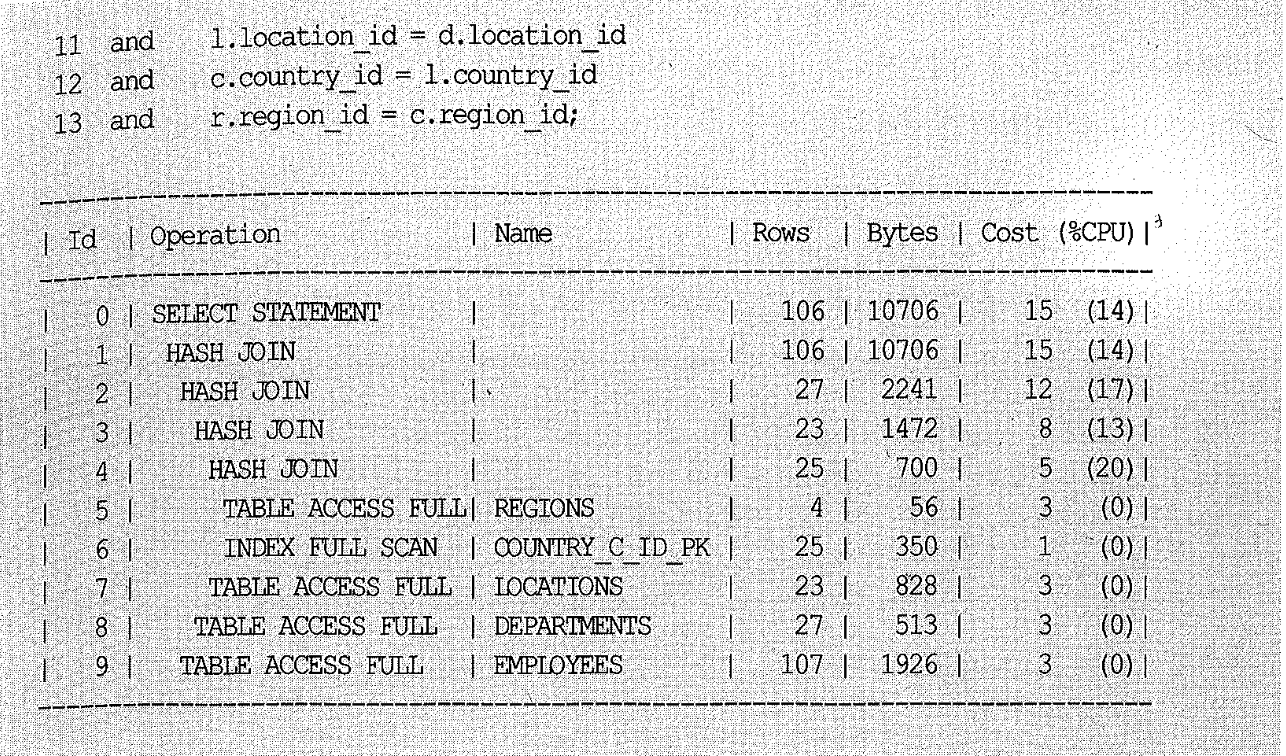
쿼리에 사용된 힌트를 보면, “regions를 기준으로 countries, locations, departments, employees 순으로 조인하되 각각 해시 조인으로 처리하라”고 지시하고 있다. ordered나 leading 힌트는 조인 순서를 결정하기 위한 것이지 해시 조인의 Build Input을 결정하기 위한 것은 아니다. 따라서 위 실행 계획을 보면 Build Input이 옵티마이저에 의해 자유롭게 결정된 것을 볼 수 있다.
위 실행 계획을 따르면, 아래와 같이 네 번의 조인 과정을 거친다.
- id 4번 해시 조인: 「regions」를 해시 테이블로 빌드(Build)하고, countries를 읽어 해시 테이블을 탐색(Probe)하여 조인 수행
- id 3번 해시 조인: 「regions와countries」조인 결과를 해시 테이블로 빌드하고, locations를 읽어 해시 테이블을 탐색하여 조인 수행
- id 2번 해시 조인: 「regions & countries & locations」조인 결과를 해시 테이블로 빌드하고, departments를 읽어 해시 테이블을 탐색하면서 조인 수행
- id 1번 해시 조인: 「regions & countries & locations & departments」조인 결과를 해시 테이블로 빌드하고, employees를 읽어 해시 테이블을 탐색하면서 조인 수행
ordered나 leading 힌트의 역할은 조인 순서를 결정하는데에 있지만, 처음 조인되는 두 집합(regions와 countries) 간에 Build Input을 정하는데에는 영향을 미친다. 1번을 제외한 나머지 2~4번(실행 계획 id 1~3번)에 대한 Build Input을 사용자가 직접 조정하고자 할 때는 아래와 같이 swap_join_inputs 힌트를 사용하면 된다.
두 번째 알고리즘
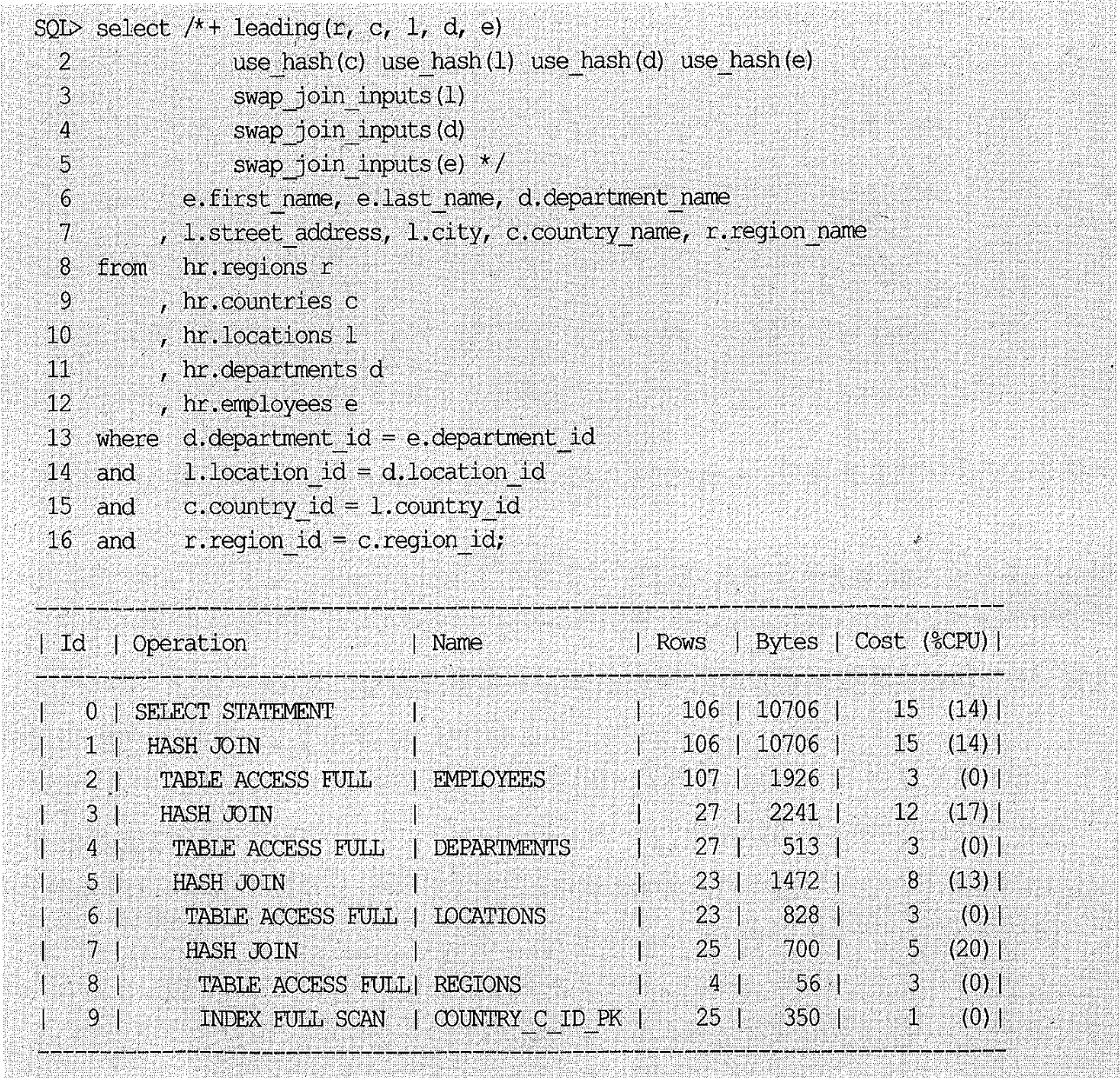
위 실행 계획도 네 번의 조인 과정을 거치지만 앞에서는 사뭇 다른 방식으로 처리되며, NL 조인 처럼 순차적으로 진행하는 것이 특징이다.
- 해시 테이블 생성: employees, departments, locations, regions 4개 테이블에 대한 해시 테이블을 먼저 생성한다.
- id 7번 해시 조인: countries에서 한 건을 읽어 regions 해시 테이블을 탐색한다.
- id 5번 해시 조인: 2번에서 조인에 성공한 레코드는 locations 해시 테이블을 탐색한다.
- id 3번 해시 조인: 3번에서 조인에 성공한 레코드는 departments 해시 테이블을 탐색한다.
- id 1번 해시 조인: 4번에서 조인에 성공한 레코드는 employees 해시 테이블을 탐색한다.
- 2~5번 과정을 countries 테이블(여기서는 인덱스)을 모두 스캔할 때까지 반복한다.
이 실행 계획은 가장 큰 employees 테이블을 해시 테이블로 생성하였으므로 처음 옵티마이저가 선택한 실행 계획보다 효율적이지 못하다.
이번에는 departments를 기준으로 employees - locations - countries - regions 순으로 조인하되, employees를 Probe Input으로 삼고 나머지는 모두 Build Input이 되도록 실행 계획을 조정해보자.
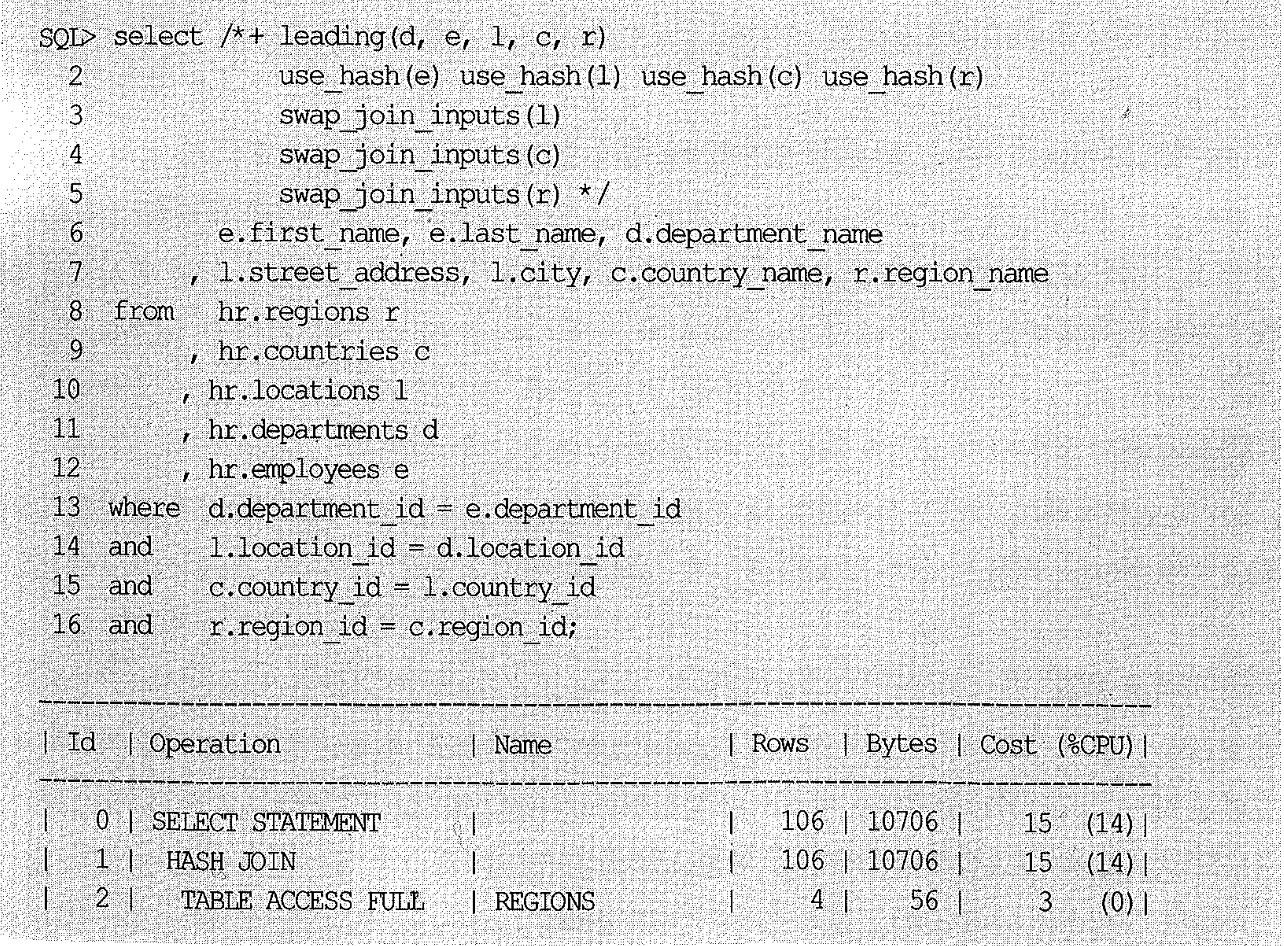

employees를 스캔하면서 departments, locations, countries, regions에 대한 해시 테이블을 차례로 탐색하면서 조인을 수행하는 것을 알 수 있다.
그림2-9를 보면 employees가 최하위 자식 엔티티로서 가장 크고, 그 위쪽에 있는 엔티티들은 모두 작은 코드성 테이블이다. 따라서 위와 같은 알고리즘으로 수행된다면 작은 테이블로 빠르게 해시 테이블을 생성하고 나서, 큰 테이블에서 일부 레코드만 스캔하다가 조인을 멈출 수도 있다. 즉, NL 조인의 가장 큰 장점인 부분 범위 처리를 해시 조인에서도 갖게되는 것이다. (물론 해시 테이블로 빌드되는 작은 테이블은 전체범위처리가 불가피하다.)
(4) Build Input이 Hash Area를 초과할 때 처리 방식
해시 조인은 해시 테이블을 Hash Area에 담을 수 있을 정도로 Build Input이 충분히 작을 때야 효과적이라고 했다. 만약 In-Memory 해시 조인이 불가능할 때 오라클은 어떤 방식으로 해시 조인을 처리할까?
Grace 해시 조인
In-Memory 해시 조인이 불가능할 때 오라클은 ‘Grace 해시 조인’ 이라고 알려진 조인 알고리즘을 사용하는데, 이는 아래 두 단계로 나누어진다.
1. 파티션 단계
조인 되는 양쪽 집합(- 조인 이외 조건을 만족하는 레코드) 모두 조인 컬럼에 해시 함수를 적용하고, 반환된 해시 값에 따라 동적으로 파티셔닝을 실시한다. 독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝을 생성하는 단계다.
파티션 단계에서 양쪽 집합을 모두 읽어 디스크 상의 Temp 공간에 일단 저장해야하므로 In-Memory 해시 조인보다 성능이 크게 떨어지게 된다.
2. 조인 단계
파티션 단계가 완료되면 각 파티션 짝(pair)에 대해 하나씩 조인을 수행한다. 이때, 각각에 대한 Build Input과 Probe Input은 독립적으로 결정된다. 즉, 파티션하기 전 어느 쪽이 작은 테이블이었는 지에 상관 없이 각 파티션 짝(pail) 별로 작은 쪽 파티션을 Build Input으로 선택해 해시 테이블을 생성한다.
해시 테이블이 생성되고 나면 반대쪽 파티션 레코드를 하나씩 읽으면서 해시 테이블을 탐색하며, 모든 파티션 짝에 대한 처리가 완료될 때까지 이런 과정을 반복한다.
Grace 해시 조인은 한마디로, 분할정복(Devide & Conquer) 방식이라고 말할 수 있다. 실제로는 벤더마다 조금씩 변형된 형태의 Hybrid 방식을 사용하지만 두 개의 큰 테이블을 해시 조인하는 기본 알고리즘은 Grace 해시 조인에 바탕을 두고 있다.
Hybrid 해시조인
앞서 설명한 기본적인 Grace 해시조인을 그대로 따른다면, 디스크 I/O 부하가 상당히 심할 것이다. 조인에 성공할 가능성이 없는 대상 집합까지 일단 디스크에 모두 쓰고, 나중에 다시 디스크로부터 읽어 조인해야하기 때문이다. 이런 단점을 보완하기 위해 여러 가지로 변형된 최적화 알고리즘이 사용되는데, 오라클이 사용하는 Hybrid 해시조인은 아래와 같은 방식이다.
- 두 테이블 중 작은 쪽을 Build Input으로 선택하고 Hash Area에 해시 테이블을 생성하기 시작한다. 이때 두 개의 해시 함수를 적용하는데, 첫번째 해시값으로는 레코드를 저장할 파티션(= 버킷)을 결정하고, 두번째 해시값은 나중(8번 단계)에 실제 조인할 때를 위해 레코드와 함께 저장해둔다.
- 해시 테이블을 생성하는 도중에 Hash Area가 꽉차면 그 중 가장 큰 파티션=버켓을 테스크 엔기록한다.
- 해시 테이블을 완성하기 위해 Build Input을 계속 읽는 동안 이미 디스크에 기록된 파티션에 해당되는 레코드는 디스크 파티션에 기록한다.
- 다시 Hash Area가 다 차면 이번에도 가장 큰 파티션을 디스크에 기록한다.
- 이렇게 첫번째 테이블에 대한 파티셔닝 단계가 끝나면 파티션 크기가 작은 순으로 메모리를 채운다. (~ 가능한 많은 파티션을 Hash Area에 담음으로써 6번 단계의 성공률을 높이기 위함이다.)
- 이제 두번째 테이블을 읽기 시작하는데, 이때도 두개의 해시 함수를 사용한다. 읽혀진 레코드의 첫번째 해시값에 해당하는 파티션이 현재 메모리에 있다면 그 파티션을 스캔하고, 거기서 조인 레코드를 찾으면 곧바로 결과 집합에 포함시킨다. 이때 첫번째 해시값으로 곧바로 파티션을 스캔하는 것이 아니라 뒤에서 설명할 비트-벡터 필터링을 거쳐 선택된 레코드만 파티션을 스캔하고, 선택되지 않은 레코드는 그냥 버린다.
- 비트-벡터 필터링을 통과했지만 메모리에서 매칭되는 파티션을 찾지 못하면 Build Input을 파티셔닝할 때와 같은 방식으로 해시 파티셔닝한다. 즉, 첫번째 해시값으로 레코드가 저장될 파티션을 결정하고, 두번째 해시값과 함께 디스크로 저장된다. 여기서, 6번 단계에서 비트-벡터 필터링을 거친 레코드만 디스크에 기록하게된다는 사실에 주목하자.
- 7번 과정까지 마치고 나면 양쪽 테이블 모두 같은 해시 함수로써 파티셔닝했기 때문에 같은 해시값을 갖는 레코드끼리는 같은 파티션 짝(pain)에 놓이게 되었다. 이제 각 파티션 짝에 대해 하나씩 조인을 수행하기만 하면 되는데, 앞에서 설명했듯이 각 파티션 짝(pain) 별로 작은 쪽 파티션을 Build Input으로 선택해 해시 테이블을 생성한다. 이때, 1번과 7번 단계에서 저장해둔 두번째 해시값이 이용된다.
- 모든 파티션에 대해 8번과정을 반복함으로써 해시조인을 마친다.
Recursive 해시조인(=Nested-loops 해시조인)
디스크에 기록된 파티션 짝(pain)끼리 조인을 수행하려고 작은 파티션’을 메모리에 로드하는 과정에서 또 다시 가용 Hash Area를 초과하는 경우가 발생할 수 있다. 그럴 때는 추가적인 파티셔닝 단계를 거치게 되는 데, 이를 ‘Recursive 해시조인’ 이라고 한다.
Recursive 해시조인을 ‘Multipass 해시조인’이라고도 하며, 참고로 디스크 쓰기가 발생했지만 Multipass 오퍼레이션을 거치지 않는 경우를 ‘One pass 해시조인’ 이라고 한다. 그리고 디스크를 전혀 사용하지 않은 In-Memory 해시조인을 ‘Optimal 해시조인’ 이라고 한다.
비트-벡터 필터링
Hybrid 조인 5~6번 단계를 거치는 동안 가능한 메모리 상에서 조인을 완료하므로 두번째 테이블이 디스크에 기록되는 양을 상당히 줄일 수 있다.
여기에 오라클은 비트-벡터 필터링(bit-vectoring) 기법까지 사용하는데, 조인 성공 가능성이 없는 파티션 레코드는 아예 디스크에 기록되지 않게 하려는 것이다.
앞서 설명한 Hybrid 해시조인 과정 중 6번 단계에서, 비트-벡터 필터링을 통해 디스크에 기록할 필요가 있는 값인지를 알 수 있다. 좀 복잡한 내용일 수 있지만 지금부터 비트-벡터 필터링 원리에 대해 살펴보자.
오라클은 Build Input을 읽어 해시테이블을 생성할 때 두 개의 해시 함수를 사용한다고 했는데, 특정 레코드가 저장될 해시 버킷이 결정되면 그와 동시에 그 두 해시값에 상응하는 비트-벡터도 1로 설정한다.
그림 2-10은 비트-벡터를 표현한 것으로서 f(m) 해시함수에 의해 다섯 개의 비트가 할당되었고 각각 A, B, C, D, E 다섯 개의 해시값과 매핑된다. 또한 f(a) 해시함수에 의해 세 개의 비트가 할당되었고 각각 1, 2, 3 세 개의 해시값과 매핑된다.
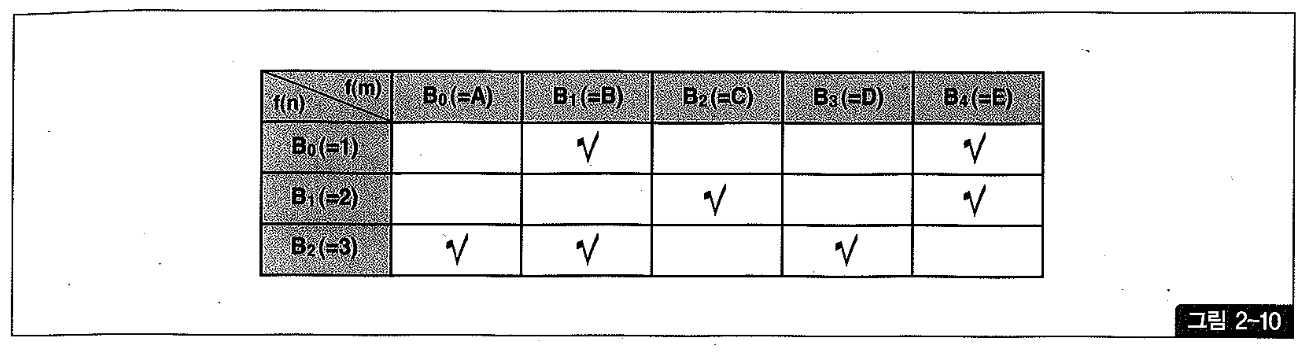
해시테이블 생성과정에서 특정 레코드가(m) 해시함수로부터 C, f(n) 해시함수로부터는 2를 리턴받았다고 하자. 그러면 해시값 C에 해당하는 버킷에 그 레코드를 저장하면서(두번째 해시함수로부터 얻은 값 2도 함께 저장), 비트-벡터 2행 3열에 있는 비트도 1(positive)로 설정한다.
이런식으로 Build Input에 대한 해시테이블을 생성하면서 파티셔닝을 완료하고 나면 두번째 테이블을 디스크로 해시파티셔닝해야하는데, 그에 앞서 비트-벡터 필터링을 통해 디스크에 기록하지 않아도 될 레코드인지를 가려낼 수 있다.
예를들어, 두번째 테이블에서 읽은 조인키값을 f(m)과 f(n) 두 해시함수에 적용해 얻은 값이 C와 2라면 2행 3열의 비트값이 1이므로 나중에 조인에 성공할 가능성이 있다. 따라서 디스크에 기록한다.
다른 조인키값에 대한 해시값이 우연히 같을 수 있다. 따라서 비트-벡터가 1로 설정돼있다고 해서 상응하는 파티션에 실제로 조인되는 레코드가 존재한다는 것을 보장하지는 않는다.
반대로, 비트-벡터가 0(negative)이면 상응하는 파티션에 조인되는 레코드가 없다는 것만큼은 확신할 수 있다. 예를들어, 두 해시함수에서 얻은 값이 각각 D와 2라면 2행 4열의 비트값 ‘0’ 이므로 그 레코드는 디스크에 기록하지 않아도 된다.
이런식으로 나중에 조인단계에서 실패할 수밖에 없는 레코드를 디스크에 기록하지 않고 버린다면, 이를 다시 읽어들여 조인하지 않아도 되므로 GraceHash 조인의 성능을 크게 향상시킬 수 있다.
(5) Build Input 해시키값에 중복이 많을 때 발생하는 비효율
잘 알다시피 해시 알고리즘의 성능은 해시 충돌(collision)을 얼마나 최소화할 수 있는지에 달려 있으며, 이를 방지하려면 그만큼 많은 해시 버킷을 할당해야만 한다. 개념적으로 설명하기 위해 그림2-8에는 하나의 버킷에 여러 키값이 달리는 구조로 표현하였지만, 가능하면 오라클은 충분히 많은 개수의 버킷을 할당함으로써 버킷 하나당 하나의 키값만 갖게 하려고 노력한다.
그런데 해시 버킷을 아무리 많이 할당하더라도 해시 테이블에 저장할 키 컬럼에 중복값이 많다면 하나의 버킷에 많은 엔트리가 달릴 수밖에 없다. 그러면 해시 버킷을 아무리 빨리 찾더라도 해시 버킷을 스캔하는 단계에서 많은 시간을 허비하기 때문에 탐색 속도가 현저히 저하된다.
Build Input의 해시 키 컬럼에는 중복값이 (거의) 없어야 해시조인이 빠르게 수행될 수 있음을 이해할 것이다. Build Input 해시 키값에 중복이 많을 때 성능이 얼마나 저하되는지 실제 사례를 통해 살펴보자.
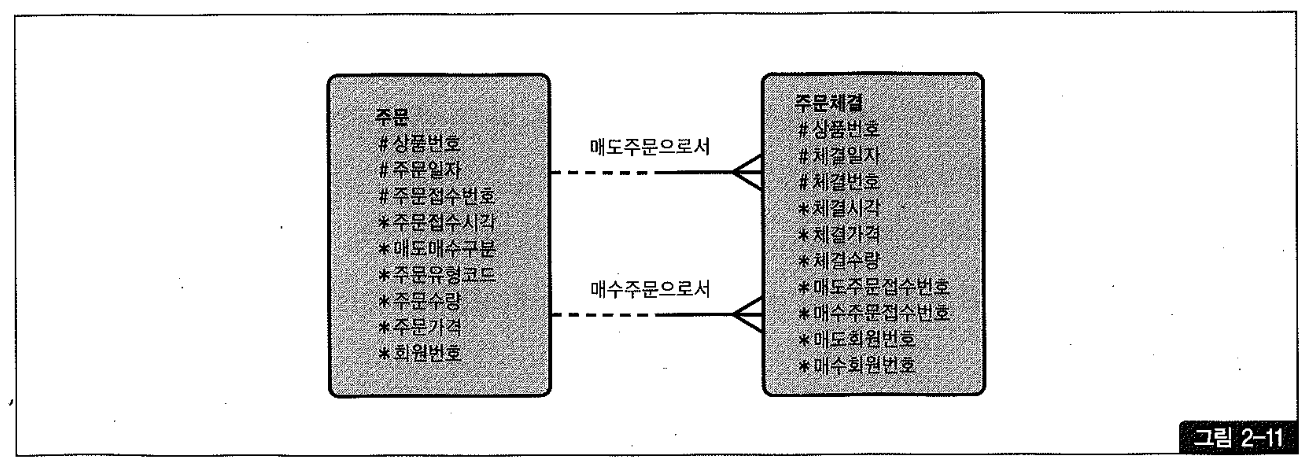
상품번호가 상수 또는 변수 조건으로 입력되지 않았을 때, 즉 특정 체결일자의 전체 상품을 대상으로 조회할 때 해시 테이블이 어떤 모습일지, 성능은 얼마나 나빠질지 상상해보기 바란다.
주문 체결 테이블을 두 번 읽었지만 아래 트레이스 결과를 보면 쿼리 수행 속도는 71초에서 0.165초로 줄었다. 튜닝해법은 이처럼 원리를 이해하는 데에서 나오기 마련이다.
(6) 해시조인 사용 기준
해시조인 성능을 좌우하는 두 가지 키포인트는 다음과 같다.
- 한쪽 테이블이 Hash Area에 담길 정도로 충분히 작아야 함
- Build Input 해시 키 컬럼에 중복값이 거의 없어야 함
위 두 가지 조건을 만족할 때라야 해시조인이 가장 극적인 성능 효과를 낼 수 있음을 앞에서 살펴보았다.
그럼, 해시조인을 언제 사용하는 것이 효과적인지 그 선택 기준을 살펴보자.
- 조인 컬럼에 적당한 인덱스가 없어 NL조인이 비효율적일 때
- 조인 컬럼에 인덱스가 있더라도 NL조인 드라이빙 집합에서 Inner 쪽 집합으로의 조인 액세스량이 많아 Random 액세스 부하가 심할 때
- 소트머지조인하기에는 두 테이블이 너무 커 소트 부하가 심할 때
- 수행 빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대용량 테이블을 조인할 때
앞쪽 세 가지 사항은 이미 설명한 내용이므로 생략하기로 하고, 마지막 항목을 강조하면서 해시조인에 대한 설명을 마치려고 한다.
해시조인이 등장하면서 소트머지조인의 인기가 많이 떨어졌다고 했는데, 그만큼 해시조인이 빠르기 때문이다. 해시조인이 워낙 빠르다 보니 모든 조인을 해시조인으로 처리하려는 유혹에 빠지기 쉬운데, 이는 매우 위험한 생각이 아닐 수 없다.
수행시간이 짧으면서 수행빈도가 매우 높은 쿼리(- OLTP성 쿼리의 특징이기도 함)를 해시조인으로 처리한다면 어떤 일이 발생할까? NL 조인에 사용되는 인덱스는 (Drop하지 않는 한) 영구적으로 유지되면서 다양한 쿼리를 위해 공유 및 재사용되는 자료구조다. 반면, 해시테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸하는 자료구조다.
따라서 수행빈도가 높은 쿼리에 해시조인을 사용하면 CPU와 메모리 사용률을 크게 증가시킴에 따라 SQL memory manager workarea, row cache objects, simulator hash latch, cache buffers Chains 같은 지 경합이 발생해 시스템 동시성을 떨어뜨리게 된다.
따라서 해시조인은 ①수행빈도가 낮고 ②쿼리 수행시간이 오래 걸리는 ③대용량 테이블을 조인할 때(-> 배치 프로그램, DW, OLAP성 쿼리의 특징이기도 함) 주로 사용해야 한다. OLTP 환경이라고 해시 조인을 쓰지 못할 이유는 없지만 이 세 가지 기준(①~③)을 만족하는지 체크해 봐야 한다.
단적으로 말해, OLTP환경에서 1초 걸리는 쿼리를 0.1초로 단축시킬 목적으로 해시조인을 쓰는 것은 가급적 자제하라는 뜻이다. 1초 걸리는 퀴리인데 업무 요건상 0.1초로 단축시켜달라는 업무 담당자의 요청이 있었다면 이는 틀림없이 수행빈도가 매우 높은 쿼리임에 틀림없다. 따라서 해시조인으로는 부적격이다.