<오라클 성능 고도화 원리와 해법2> Ch02-04 조인 순서의 중요성
오라클 성능 고도화 원리와 해법2 - Ch02-04 조인 순서의 중요성
조인 순서에 따라 쿼리 수행 성능이 달라질 수 있는데, 먼저 NIL 조인부터 살펴보자. 10만 고객을 관리하는 ‘고객’ 테이블과 세 종류(신용카드, 자동이체, 지로)의 납입 방법을 관리하는 ‘납입방법’ 테이블이 있다. 이 두 테이블을 조인하는 아래 SQL을 NIL 방식으로 조인할 때, 어떤 테이블을 먼저 드라이빙하는 것이 유리할까? 양쪽 모두 조인 컬럼에 인덱스를 갖고 있다.
1
2
3
select /*+ use_nl(a b) */ a.납입방법명, b.*
from 납입방법 a, 고객 b
where b.납입방법코드 = a.납입방법코드
필터 조건이 없을 때
NL 조인에서는 무엇보다 Random 액세스 발생량에 의해 성능이 좌우되는데, 먼저 고객 테이블을 드라이빙하는 경우를 보자.
1
2
3
select /*+ leading(o) use_nl(a) */ a.납입방법명, b.*
from 납입방법 a, 고객 b
where b.납입방법코드 = a.납입방법코드
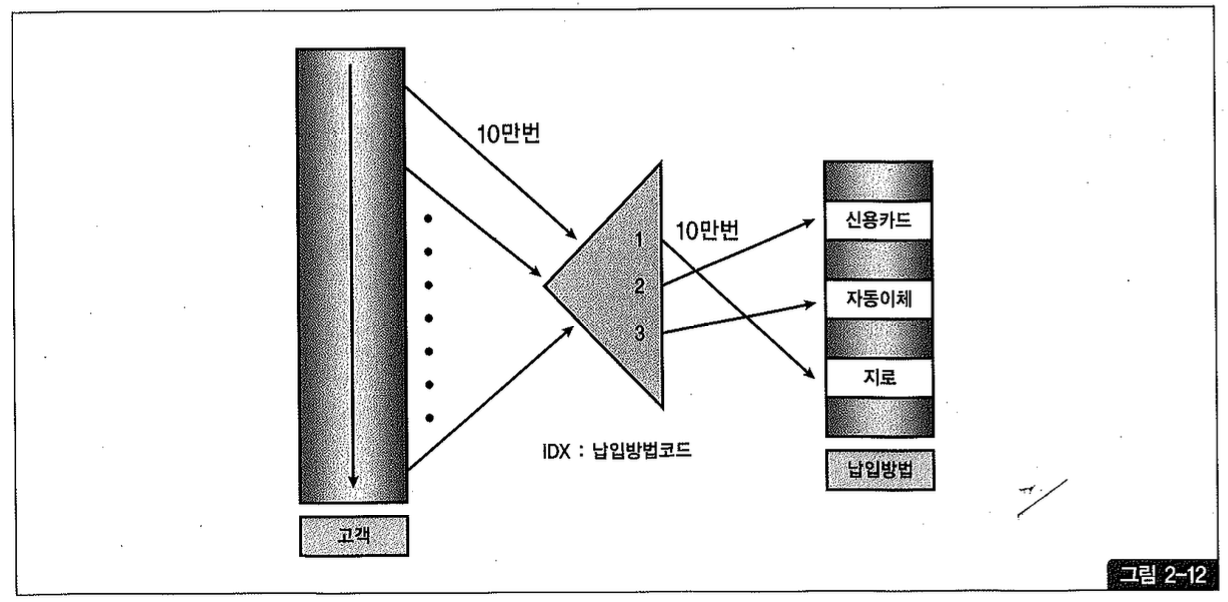
그림 2-12를 보면 고객 테이블에서 납입방법코드 인덱스로 조인 액세스할 때 10만 번의 Random 액세스가 발생하고, 납입방법 테이블로 액세스할 때 다시 10만 번의 Random 액세스가 발생한다. 따라서 총 20만 번의 Random 액세스가 발생한다.
이번에는 납입방법 테이블을 먼저 드라이빙하는 경우를 보자.
1
2
3
select /*+ leading(a) usenl(b) */ a.납입방법명, b.*
from 납입방법 a, 고객 b
where b.납입방법코드 = a.납입방법코드
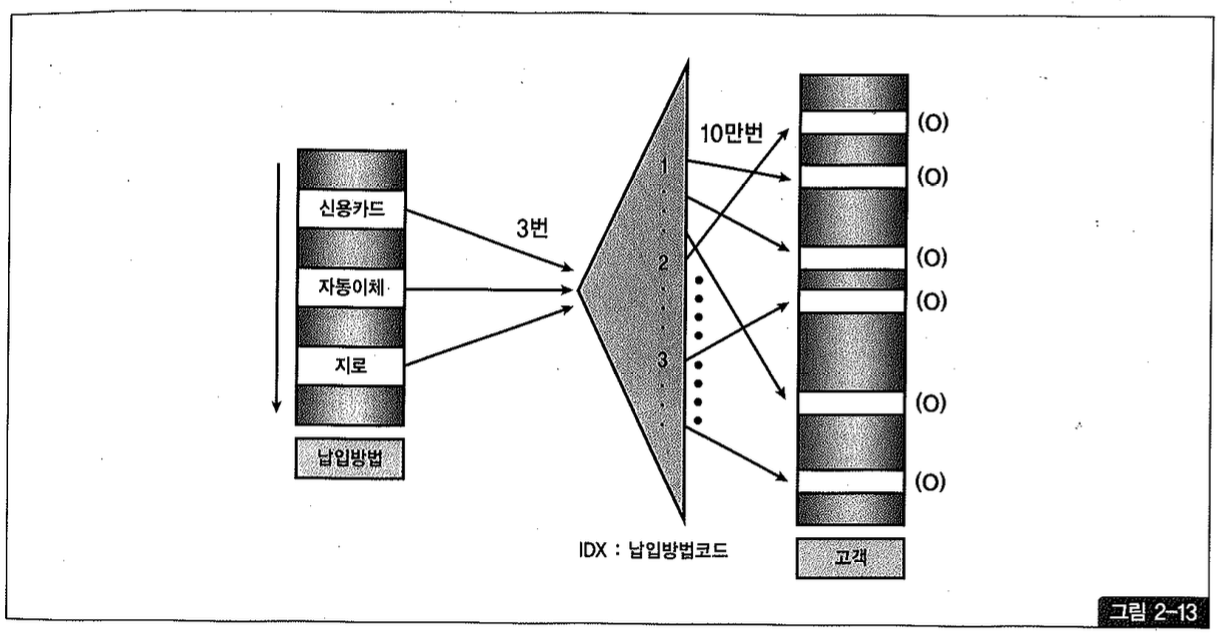
그림 2-13을 보면, 납입테이블에서 고객쪽 납입방법코드 인덱스로 조인을 시도할 때 3번의 Random 액세스가 발생한다. 고객 테이블을 액세스할 때는 10만 번의 Random 액세스가 발생해, 총 100,003번의 Random 액세스가 발생한다.
다른 필터 조건이 없는 상황에서는 작은 쪽(=쪽) 집합을 드라이빙하는 것이 유리함을 알 수 있다.
필터조건이 있을 때
이번에는 거주지역이 ‘부산’인 고객만을 대상으로 조회할 때의 일량을 분석해보자. 부산 지역 고객은 전체 중 10%에 해당하는 1만 명이고, 고객 테이블 거주지역 컬럼에 인덱스가 있다.
아래는 고객 테이블을 먼저 드라이빙하는 경우다.
1
2
3
4
select /*+ leading(a) use_nl(b) */ a.납입방법명, b.*
from 납입방법 a, 고객 b
where b.납입방법코드 = a.납입방법코드
and b.거주지역 = '부산'
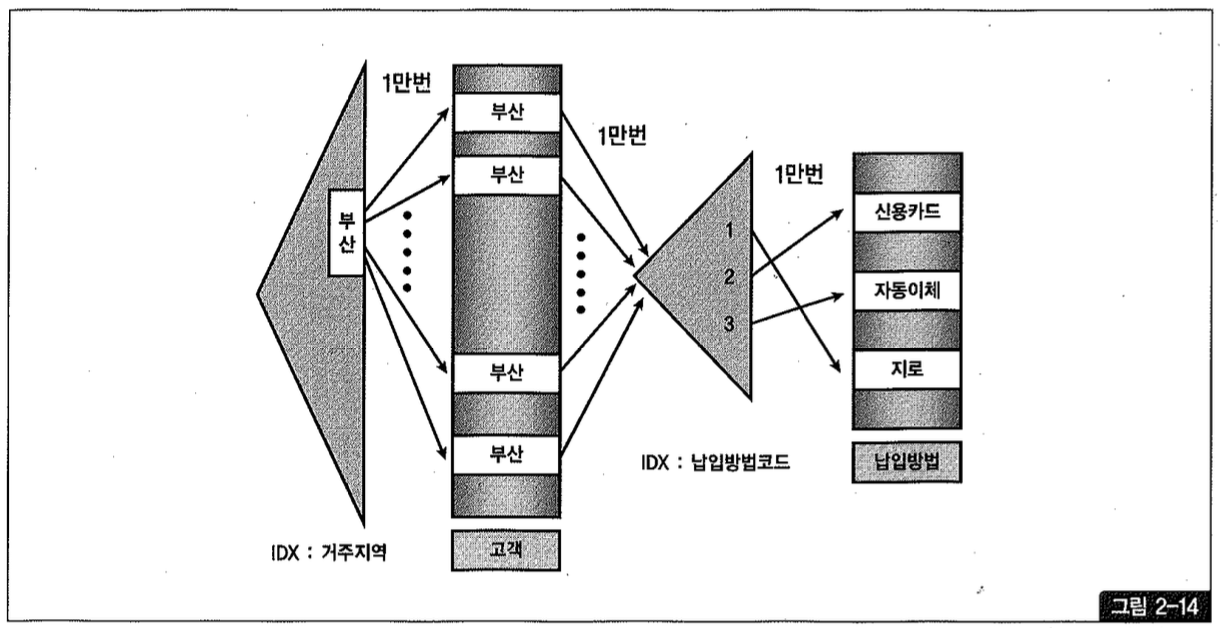
그림 2-14를 보면, 거주지역 인덱스를 통해 고객 테이블을 액세스할 때 1만 번의 Random 액세스가 발생한다. 이어서 납입방법코드 인덱스로 조인 액세스할 때 1만 번의 Random 액세스가 발생하고, 납입방법 테이블을 액세스할 때도 1만 번의 Random 액세스가 발생한다. 따라서 총 3만 번의 Random 액세스가 발생한다.
똑같은 쿼리인데, 이번에는 납입방법 테이블을 먼저 드라이빙할 때를 살펴보자.
1
2
3
4
select /*+ leading(a) use_nl(b) */ a.납입방법명, b.*
from 납입방법 a, 고객 b
where b.납입방법코드 = a.납입방법코드
and b.거주지역 = '부산'
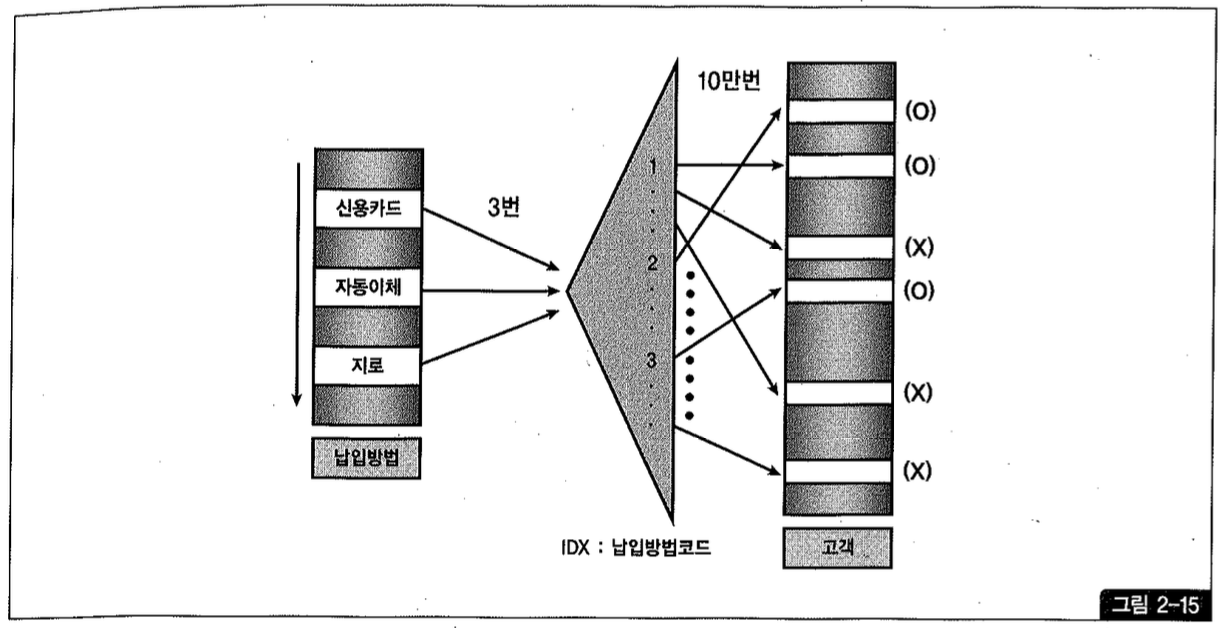
그림 2-15를 보면, 그림 2-13과 똑같은 일량(100,003번의 Random 액세스)인 것을 알 수 있다. 다만, 여기서는 고객 테이블 쪽으로 많은 액세스가 있었지만 거주지역=’부산’ 조건에 의해 90% 가량이 버려지므로 비효율이 존재한다.
인덱스에 거주지역’ 컬럼을 추가해보자.
1
2
3
4
select /*+ leading(a) use_nl(b) */ a.납입방법명, b.*
from 납입방법 a, 고객 b
where b.납입방법코드 = a.납입방법코드
and b.거주지역 = '부산'
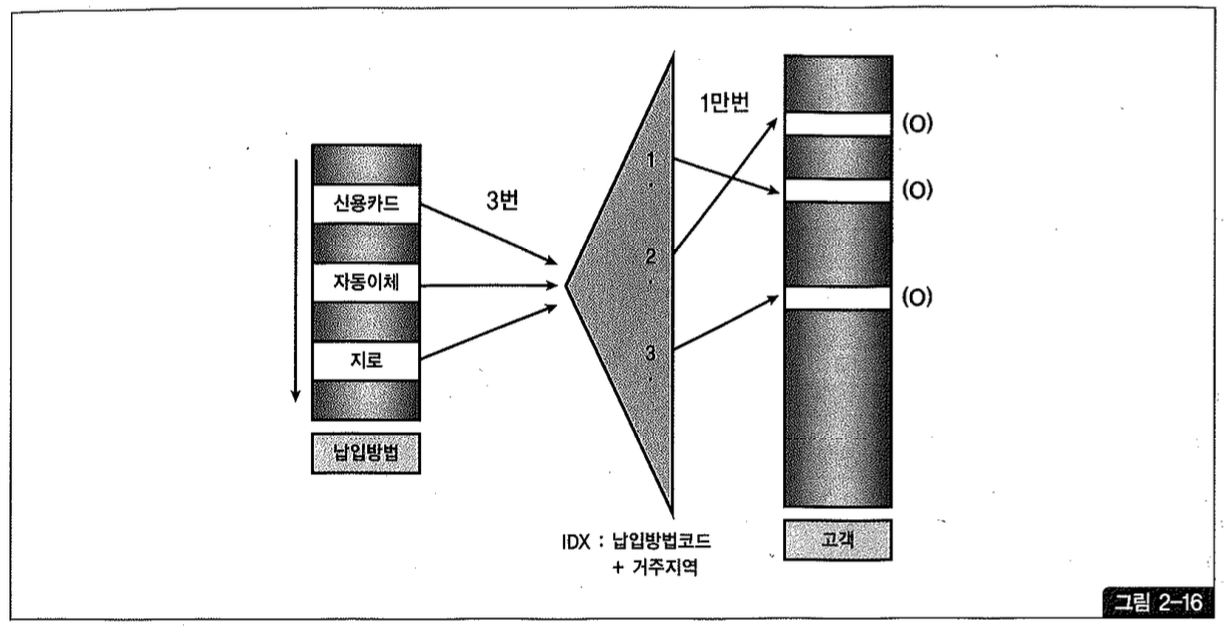
그림 2-16을 보면, Random 액세스가 10,003번으로 준 것을 볼 수 있다.
이처럼 조인 조건 외에 필터 조건이 있을 때는 인덱스 구성에 따라 유•불리가 결정되며, 비효율이 없게끔 인덱스를 잘 구성해주기만 한다면 역시 작은 쪽(=1쪽) 집합을 드라이빙하는 것이 유리하다.
NL조인에서는 Random 액세스 발생량 외에도 Inner 쪽 인덱스 구성 및 조건절 연산자 형태에 따라 성능이 크게 좌우되는데, 1장에서 설명한 인텍스 스캔 효율에 차이가 생기 때문이다.
소트머지조인과 해시조인의 경우
NL 조인뿐 아니라 소트머지조인과 해시조인에서도 순서가 중요하다.
소트머지조인은 PGA 상에 정렬된 집합을 통해 조인 액세스가 일어나기 때문에 Random 액세스 발생량보다는 소트부하에 의해 성능이 결정된다. 결론만 간단히 말하면, 디스크 소트(o-disk sort)가 발생할 정도의 큰 테이블을 포함할 때는 큰 테이블을 드라이빙하는 것이 더 빠르지만, 메모리 소트(n-memory sort) 방식으로 조인할 때는 작은 쪽 테이블을 드라이빙하는 것이 조금 더 빠르다.
해시조인은 Hash Area에 BuildInput을 모두 채울 수 있는가가 관건이므로 두말할 것도 없이 작은 쪽 테이블을 드라이빙하는 것이 유리하다.
| 세 개 이상 테이블에 대한 조인문 기술할 때 주의사항 |
|---|
| 조인 컬럼에 대한 상수나 변수 조건은 조인 문을 타고 다른 쪽 테이블 조건으로도 전이된다(4장 5절 조건 절 이행 참조). 하지만 조인 문 자체는 그런 작용이 일어나지 않으므로 세 개 이상 테이블에 대한 조인문을 기술할 때 세심한 주의가 필요하다. 예를 들어, A와 B 간의 조인 조건, B와 C 간의 조인 조건을 이용해 A와 C 간의 조인 조건이 내부적으로 생성된다면(물론 조인 컬럼이 서로 같을 때) 조인 순서가 어떻게 결정되더라도 효과적으로 수행될 수 있다. 하지만 조인 조건은 그런 식의 전이가 이루어 지 지 않 으 므 로 사 용 자 가 최 적 의 조 인 순 서 를 결 정 하 고 그 순서에 따라 조인문을 기술해주는 것이 매우 중요하다. 자세한 설명은 4장 5절 ‘조건 이행 중에서 튜닝 사례 2(p522)를 참조하기 마란다. |