<오라클 성능 고도화 원리와 해법2> Ch02-07 조인을 내포한 DML 튜닝
오라클 성능 고도화 원리와 해법2 - Ch02-07 조인을 내포한 DML 튜닝
(1) 수정 가능 조인 뷰 활용
전통적인 방식의 UPDATE
튜닝을 하다 보면 아래와 같이 작성된 update 문을 종종 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
update 고객 c
set
최종거래일시 = (select max(거래일시) from 거래
where 고객번호=c.고객번호
and 거래일시>=trunc(add_months(sysdate,-1))),
최근거래횟수 = (select count(*) from 거래
where 고객번호=c.고객번호
and 거래일시>=trunc(add_months(sysdate, -1))),
최근거래금액 = (select sum(거래금액) from 거래
where 고객번호=c.고객번호
and 거래일시>=trunc(add_months(sysdate, -1)))
where exists (select 'x' from 거래
where
고객번호 = c.고객번호
and
거래일시 >= trunc(add_months(sysdate, -1)))
만약 독자가 개발 중인 프로그램에 위와 같은 update 문이 있다면 아래와 같이 고치기 바란다.
1
2
3
4
5
6
7
8
9
10
11
12
update 고객 c
set
(최종거래일시, 최근거래횟수, 최근거래금액)
= (select max(거래일시), count(*), sum(거래금액)
from 거래
where
고객번호= c.고객번호
and 거래일시>=trunc(add_months(sysdate,-1)))
where exists(select 'x' from 거래
where 고객번호 = c.고객번호
and
거래일시 > trunc(add_months(sysdate, -1)))
위 방식에도 비효율이 없는 것은 아니다. 한 달 이내 거래가 있는 고객을 두 번 조회하기 때문인데, 총 고객수와 한 달 이내 거래가 발생한 고객수에 따라 성능이 좌우된다.
총 고객수가 아주 많다면 Exists 서브쿼리를 아래와 같이 해시 세미조인으로 유도하는 것을 고려할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
update 고객 c
set
(최종거래일시, 최근거래횟수, 최근거래금액)
= (select max(거래일시), count(*), sum(거래금액)
from 거래
where
고객번호= c.고객번호
and 거래일시>=trunc(add_months(sysdate, -1)))
where exists (select /*+ unnest hash sj */ 'x' from 거래
where
고객번호 = c.고객번호
and
거래일시 >= trunc(add_months(sysdate, -1)))
만약 한 달 이내 거래를 발생시킨 고객이 많아 update 발생량이 많다면 아래와 같이 변경하는 것을 고려할 수 있다. 하지만 모든 고객 레코드에 lock이 발생함은 물론, 이전과 같은 값으로 갱신되는 비중이 높을수록 Redo 로그 발생량이 증가해 오히려 비효율적일 수 있다.
1
2
3
4
5
6
7
8
9
update 고객 c
set (최종거래일시, 최근거래횟수, 최근거래금액)
= (select nvl(max(거래일시), c.최종거래일시)
, decode(count(*), 0, c.최근거래횟수, count(*))
, nvl(sum(거래금액), c.최근거래금액)
from 거래
where 고객번호= c.고객번호
and
거래일시>=trunc(add_months(sysdate, -1)))
이처럼 다른 테이블과 조인이 필요할 때 전통적인 방식의 update 문을 사용하면 비효율을 감수해야만 한다.
참고로, set 절에 사용된 서브쿼리에는 캐싱 메커니즘이 작용하므로 distinct value 개수가 적은 1쪽 집합을 읽어 M쪽 집합을 갱신할 때 효과적이다. 물론 exists 서브쿼리가 NL 세미조인이나 필터 방식으로 처리된다면 거기서도 캐싱 효과가 나타난다.
수정 가능 조인 뷰 활용
아래와 같이 수정 가능 조인 뷰를 활용하면 참조 테이블과 두 번 조인하는 비효율을 없앨 수 있다. (bypass_uivc 힌트에 대해서는 뒤에서 설명한다.)
1
2
3
4
5
6
7
8
9
10
11
12
update /*+ bypass ujve */
(select /*+ ordered use_hash(c) */)
c.최종거래일시, c.최근거래횟수, c.최근거래금액
, t.거래일시, t.거래횟수, t.거래금액
from
(select 고객, max(거래일시) 거래일시, count(*) 거래횟수, sum(거래금액) 거래금액 from 거래
where 거래일시 > trunc(add_months(sysdate, 1))
group by 고객) t
, 고객 c
where
c.고객번호= t.고객번호
set 최종거래일시 = 거래일시, 최근거래횟수 = 거래횟수, 최근거래금액 = 거래금액
‘조인 뷰’는 from 절에 두 개 이상 테이블을 가진 뷰를 가리키며, ‘수정 가능 조인 뷰 (updateable/modifiable join view)는 말 그대로 입력, 수정, 삭제가 허용되는 조인 뷰를 말한다. 단, 1쪽 집합과 조인되는 M쪽 집합에만 입력, 수정, 삭제가 허용된다.
아래와 같이 생성한 조인 뷰를 통해 job이 ‘CLERK’인 레코드의 loc을 모두 ‘SEOUL’로 변경하는 것을 허용하면 어떤 일이 발생할까? (스크립트 Ch2.10.0 참조)
1
2
3
4
5
6
7
SQL> create table emp as select * from scott.emp;
SQL> create table dept as select * from scott.dept;
SQL> create or replace view EMP_DEPT_VIEW as
select e.rowid emp_rid, e.*, d.rowid dept_rid, d.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno;
SQL> update EMP_DEPT_VIEW set loc = 'SEOUL' where job = 'CLERK';
아래 쿼리 결과를 보면 job이 ‘CLERK’인 사원이 10, 20, 30 부서에 모두 속해 있는데, 위와 같이 update를 수행하고 나면 세 부서의 소재지(loc)가 모두 ‘SEOUL’로 바뀔 것이다. 세 부서의 소재지가 같다고 이상할 것이 없지만 다른 job을 가진 사원의 부서 소재지까지 바뀌는 것은 원하던 결과가 아닐 수 있다.
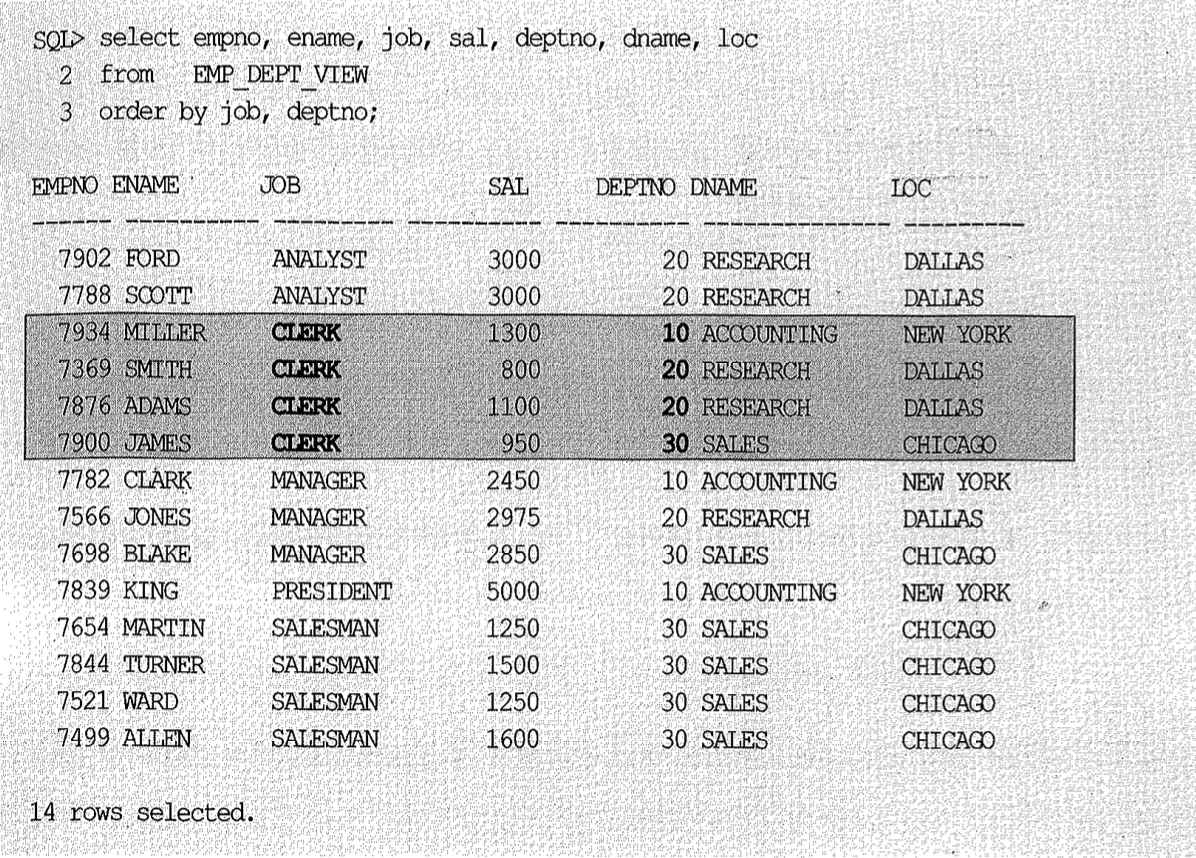
아래 update 문은 어떤가? 1쪽 집합(dept)과 조인되는 M쪽 집합(emp)의 컬럼을 수정하므로 문제가 없어 보인다.
1
SQL> update EMP_DEPT_VIEW set comm = nvl(comm, 0) + (sal * 0.1) where sal <= 1500;
하지만 실제 수행해보면 아래와 같은 에러가 발생한다. (앞선 update 문에서도 똑같은 에러가 발생한다.)
1
ORA-01779: cannot modify a column which maps to a non key-preserved table
아직 dept 테이블에 unique 인덱스를 생성하지 않았기 때문에 생긴 에러다. 옵티마이저 입장에서는 어느 쪽이 1집합인지 알 수 없었던 것이고, 지금 상태에서는 아래와 같은 delete 문장도 허용되지 않는다. insert 문도 마찬가지다.
1
2
3
SQL> delete from EMP_DEPT_VIEW where job = 'CLERK';
행 에 오류:
ORA-01752: cannot delete from view without exactly one key-preserved table
아래와 같이 1쪽 집합에 PK 제약을 설정하거나 unique 인덱스를 생성해야 수정 가능 조인 뷰를 통한 입력/수정/삭제가 가능해진다.
1
2
3
SQL> alter table dept add constraint dept_pk primary key (deptno);
SQL> update EMP_DEPT_VIEW set comm = nvl(comm, 0) + (sal * 0.1) where sal <= 1500;
4 rows updated.
위와 같이 PK 제약을 설정하면 emp 테이블은 ‘키-보존테이블(Key-Preserved Table)’이 되고, dept 테이블은 ‘비키-보존테이블(Non-Key Preserved Table)’로 남는다.
키 보존 테이블이란?
키 보존 테이블이란, 조인된 결과 집합을 통해서도 중복 값 없이 Unique하게 식별이 가능한 테이블을 말한다. Unique한 1쪽 집합과 조인되는 테이블이어야 조인된 결과 집합을 통한 식별이 가능하다.
간단히 말해 ‘키 보존 테이블’이란, 뷰에 rowid를 제공하는 테이블을 말한다.
*_UPDATABLE_COLUMNS 뷰 참조
dept_rid, dname, loc 컬럼에는 insert, update, delete가 허용되지 않는다고 표시돼있는데, 모두 ‘비 키 - 보 존 테 이 블 (Non Key - Preserved Table)’로부터 온 컬럼이다. loc 컬럼을 빼고 다시 insert 해보면 아래와 같이 정상적으로 처리된다.
수정 가능 조인 뷰 제약 회피
아래와 같이 부서별 평균 급여를 저장할 컬럼을 dept 테이블에 추가하고, emp 테이블에서 집계한 값을 반영하려고 하자 에러가 발생하였다. deptno로 group by한 결과는 unique하기 때문에 이 집합과 조인되는 dept 테이블은 키가 보존됨에도 옵티마이저가 불필요한 제약을 가한 것이다.
1
2
3
4
5
6
7
8
SQL> alter table dept add avgsal number(7,2);
SQL> update
2 (select d.deptno, d.avg_sal d_avg_sal, e.avgsal e_avg_sal
3 from (select deptno, round(avg(sal), 2) avgsal from emp group by deptno) e
4 , dept d
5 where d.deptno = e.deptno)
6 set d.avgsal = e_avg_sal;
ORA-01779: cannot modify a column which maps to a non key-preserved table
다행히 키 보존 테이블이 없더라도 update 수행이 가능하게 하는 힌트가 있다. bypass_ujvc 그것이고, Updatable Join View Check를 생략하라고 옵티마이저에게 지시하는 힌트다.
update를 위해 참조하는 집합에 중복 레코드가 없을 때만 이 힌트를 사용해야 한다. 10g부터는 Merge Into 구문도 활용 가능한데, 이에 대해서는 곧이어 살펴볼 것이다. ※19부터 bypass_ujvc 힌트를 사용할 수 없게 되었다. 하지만, 참조 테이블에 unique 인덱스가 있다면, 수정 가능 조인 뷰를 이용한 update 기능은 여전히 사용할 수 있다.
(2) Merge문 활용
DW(데이터 웨어하우스)에서 가장 흔히 발생하는 오퍼레이션은, 기간계 시스템에서 가져온 신규 트랜잭션 데이터를 반영함으로써 두 시스템 간 데이터를 동기화시키는 작업이다.
예를 들어, 고객(customer) 테이블에 발생한 변경분 데이터를 데이터 웨어하우스에 반영하는 프로세스는 다음과 같다. 이 중에서 3번 데이터 적재 작업을 효과적으로 지원하기 위해 오라클 9.1부터 merge into 문을 지원하기 시작했다.
- 전일 발생한 변경 데이터를 기간계 시스템으로부터 추출(Extraction)
1
2
3
create table customer_delta as
select * from customer
where mod_dt between trunc(sysdate)-1 and trunc(sysdate)-1/86400;
- customer_delta 테이블을 DW 시스템으로 전송(Transportation)
- DW 시스템으로 적재(Loading)
1
2
3
4
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then update set t.cust_id = s.cust_id, t.cust_nm = s.cust_nm, t.email = s.email
when not matched then insert (cust_id, cust_nm, email, tel_no, region, addr, reg_dt)
values (s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt);
Optional Clauses
10g 부터는 아래와 같이 update 와 insert 를 선택적으로 처리할 수 있다.
1
2
3
4
5
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then update set t.cust_id = s.cust_id, t.cust_nm = s.cust_nm, t.email = s.email
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when not matched then insert (cust_id, cust_nm, email, tel_no, region, addr, reg_dt)
values (s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt);
이 확장 기능을 통해 Updatable Join View 기능을 대체할 수 있게 되었다. 즉, bypass_ujvc 힌트가 필요할 때 아래와 같이 merge 문으로 처리를 할 수도 있다.
1
2
3
merge into dept d using (select deptno, round(avg(sal), 2) avg_sal from emp group by deptno) e
on (d.deptno = e.deptno)
when matched then update set d.avg_sal = e.avg_sal;
Conditional Operations
10g에서는 on 절에 기술한 조인문 외에 아래와 같이 추가로 조건을 기술할 수도 있다.
1
2
3
4
5
6
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then update set t.cust_id = s.cust_id, t.cust_nm = s.cust_nm, t.email = s.email
where reg_dt > to_date('20000101', 'yyyymmdd')
when not matched then insert (cust_id, cust_nm, email, tel_no, region, addr, reg_dt)
values (s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt)
where reg_dt < trunc(sysdate);
DELETE Clause
10g에서 제공되기 시작한 또한 가지 확장 기능은, 이미 저장된 데이터를 조건에 따라 지우는 것이다.
1
2
3
4
5
6
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then update set t.cust_id = s.cust_id, t.cust_nm = s.cust_nm, t.email = s.email,
delete where t.withdraw_dt is not null
-- 탈퇴일시가 null 이 아닌 레코드 삭제
when not matched then insert (cust_id, cust_nm, email, tel_no, region, addr, reg_dt)
values (s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt);
기억할 점은, 예시한 merge 문에서 update 가 이루어진 결과로서 탈퇴일시(withdrawa)가 null 이 아닌 레코드만 삭제된다는 사실이다. 즉, 탈퇴일시가 null 이 아니었어도 merge 문을 수행한 결과가 null 이면 삭제되지 않는다.
MergeInto 활용 - 1
레코드를 저장하려는 데 기존에 이미 존재하는 경우에는 업데이트를 수행하고, 그렇지 않으면 삽입하려고 한다. 먼저, 아래와 같이 하면 SQL이 “항상 두 번씩” (Select 한 번, insert 또는 update 한 번) 수행된다.
1
2
3
4
5
6
select count (*) into :cnt from dept where deptno = val1;
if cnt = 0 then
insert into dept (deptno, dname, loc) values (val1, val2, val3);
else
update dept set dname = val2, loc = val3 where deptno = val1;
end if;
아래와 같이 하면 SQL이 “최대 두 번” 수행된다.
1
2
3
4
update dept set aname = val2, loc = val3 where deptno = val1;
if sql%rowcount = 0 then
insert into dept (deptno, dname, loc) values (val1, val2, val3);
end if;
아래와 같이 merge 문을 활용하면 SQL이 “한 번만” 수행된다.
1
2
3
4
5
6
merge into dept a
using (select val1 deptno, val2 dname, val3 loc from dual) b on (b.deptno = a.deptno)
when matched then
update set dname = b.dname, loc = b.loc
when not matched then
insert (deptno, dname, loc) values (b.deptno, b.dname, b.loc);
Merge Into 활용 - 2
merge 문을 이용해 아래와 같이 바꾸고나니 1.16초만에 수행을 마쳤다.
(3) 다중 테이블 Insert 활용
오라클 91부터는 조건에 따라 여러 테이블에 insert하는 다중 테이블 insert 도 제공된다. 기본 사용법은 오라클 매뉴얼을 참고하고, 여기서는 간단한 튜닝 사례를 살펴보기로 하자.
아래는 야간 배치 프로그램 중 일부를 발췌한 것이다.
1
2
3
4
5
6
7
8
9
insert into 청구보험당사자 (당사자id, 접수일자, 접수순번, 담보구분, 청구순번)
select a.당사자id, a.접수일자, a.접수순번, a.담보구분, a.청구순번
from 청구보험당사자_임시 a, 거래당사자 b
where a.당사자id = b.당사자id;
insert into 자동차사고접수당사자 (당사자id, 접수일자, 접수순번, 담보구분, 청구순번)
select a.당사자id, a.접수일자, a.접수순번, a.담보구분, a.청구순번
from 가사고접수당사자_임시 a, 거래당사자 b
where b.당사자구분 not in ('4','5','6') and a.당사자id = b.당사자id;
‘청구 보험 당사자 임시’와 ‘가사고 접수 당사자 임시’는 10만 건 미만이지만 ‘거래 당사자’는 수천만 건에 이르는 대용량 테이블이라고 하자. 그럴 때 아래와 같이 다중 테이블 insert 문을 활용하면 대용량 거래 당사자 테이블을 한 번만 읽고 처리할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
insert first
when 구분 = 'A' then
into 청구보험당사자 (당사자id, 접수일자, 접수순번, 담보구분, 청구순번)
values (당사자id, 접수일자, 접수순번, 담보구분, 청구순번)
when 구분 = 'B' then
into 자동차사고접수당사자 (당사자1d, 접수일자, 접수순번, 담보구분, 청구순번)
values (당사자id, 접수일자, 접수순번, 담보구분, 청구순번)
select a.구분, a.당사자id, a.접수일자, a.접수순번, a.담보구분, a.청구순번
from (
select 'A' 구분, from 청구보험당사자_임시
union all
select 'B' 구분, from 가사고접수당사자_임시 where 당사자구분 not in ('4','5','6')
) a, 거래당사자 b
where a.당사자id = b.당사자id;