<오라클 성능 고도화 원리와 해법2> Ch02-08 고급 조인 테크닉
오라클 성능 고도화 원리와 해법2 - Ch02-08 고급 조인 테크닉
(1) 누적 매출 구하기
우선 아래와 같이 월별 지점 매출 테이블을 만들어보자(스크립트 ch2_11.txt 참조)
1
2
3
4
5
6
create table 월별지점매출 as
select deptno as "지점",
row_number() over (partition by deptno order by empno) as "판매월",
round(dbms_random.value(500, 1000)) as "매출"
from emp
order by deptno;
그림 2-23 좌측은 방금 만든 월별 지점 매출 테이블을 출력한 것이다.
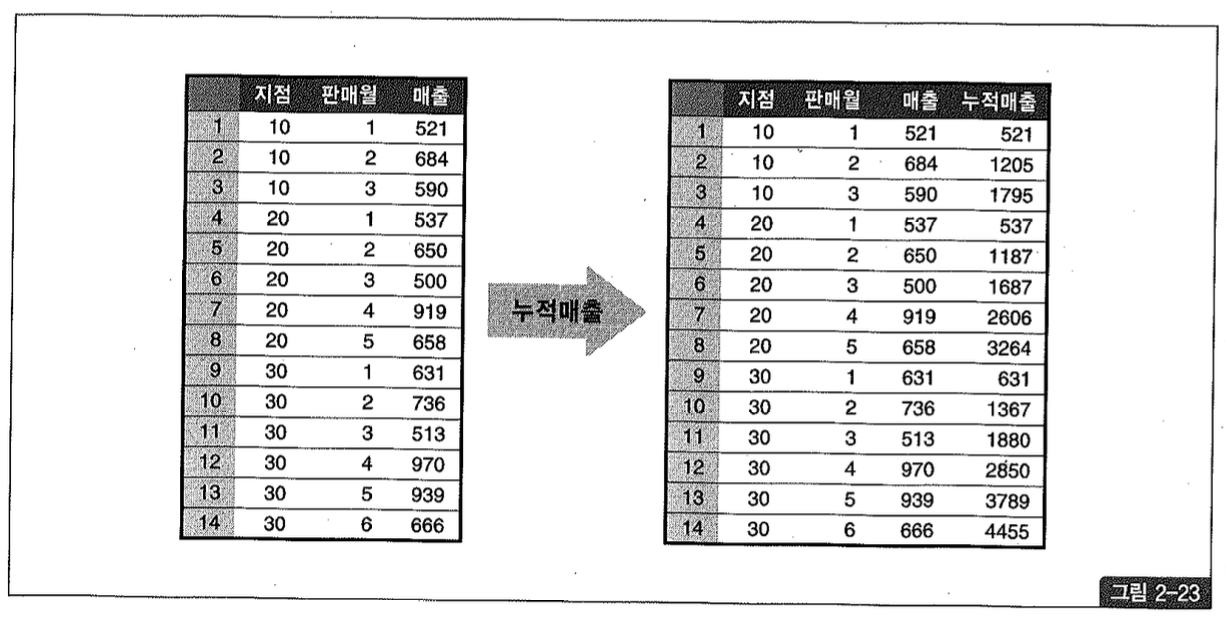
이제 월별 지점 매출을 이용해 그림 2-23 우측과 같은 형태의 누적 매출을 구하려고 한다. 각 지점 별로 판매 월과 함께 증가하는 누적 매출(running total)을 구하려는 것이다.
오라클 8i부터 제공되기 시작한 분석 함수(Analytic Function)를 이용하면 아래와 같이 간단하게 원하는 결과를 얻을 수 있다.
1
2
3
select 지점, 판매월, 매출,
Sum(매출) over (partition by 지점 order by 판매월 range between unbounded preceding and current row) as 누적매출
from 월별지점매출;
만약 분석 함수가 지원되지 않는 오라클 버전(또는 DBMS)을 사용하고 있다면 어떻게 해야 할까?
우리는 늘 ‘ = ‘ 연산자를 이용한 조인에만 익숙해져 있지만 업무에 따라서는 between, like, 부등호 같은 연산자로 조인해야 할 때도 있다. 아래는 부등호 조인을 통해 그림 2-23 우측과 같은 지점별 누적 매출을 구하는 방법을 예시하고 있다.
1
2
3
4
5
6
select t1.지점, t1.판매월, min(t1.매출) as 매출, Sum(t2.매출) as 누적매출
from 월별지점매출 t1, 월별지점매출 t2
where t2.지점 = t1.지점
and t2.판매월 <= t1.판매월
group by t1.지점, t1.판매월
order by t1.지점, t1.판매월;
(2) 선분 이력 끊기
선분 이력 레코드를 가공해야 할 때가 있는데, 월말 기준으로 선분을 끊는 경우를 살펴보자. 본론으로 들어가기에 앞서, 두 선분이 겹치는 구간에 대한 시작일자 및 종료일자 선택 규칙에 대해 살펴보자.
시간을 나타내는 두 개의 선분이 서로 겹치는 모습을 표현하면 그림 2-24의 (a), (b), (c), (d)처럼 네 가지 패턴이 있다. (e), (f)는 참고로 그린 것이며, 서로 겹치지 않은 모습이다.
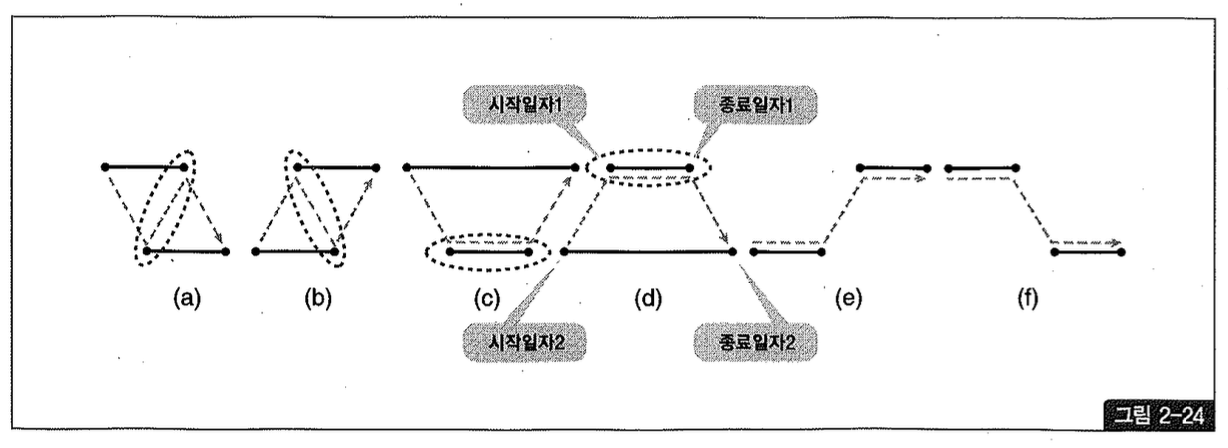
점선 타원 표시는 두 선분이 겹치는 구간의 시작 및 종료 일자를 나타낸 것이다. 그리고 점선 화살 표는 시간의 진행 순서를 표시한 것이다.
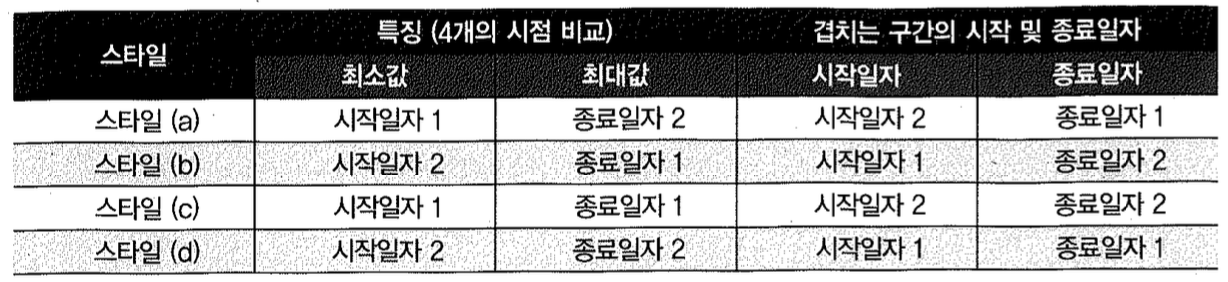
(a), (b), (c), (d) 네 스타일의 특징과 겹치는 구간의 시작 및 종료 일자 선택 규칙을 정리하면, 아래 표와 같다. 설명의 편의를 위해, 그림 2-24에서 상단에 있는 선분의 시작일자와 종료일자를 각각 ‘시작일자1’과 ‘종료일자1’이라고 명명하였고, 하단에 있는 선분의 시작일자와 종료일자를 각각 ‘시작일자2’와 ‘종료일자2’라고 명명하였다.
본론으로 들어가서, 그림 2-25처럼 월도와 선분이력 두 개의 테이블이 있을 때 선분 이력을 월도와 조인해서 맨 아래 쪽 변환된 선분 이력과 같은 형태로 만들려고 한다. 즉, 두 개 이상의 월도에 걸친 선분(5, 7)을 매 월말 기준으로 끊으려는 것이다.
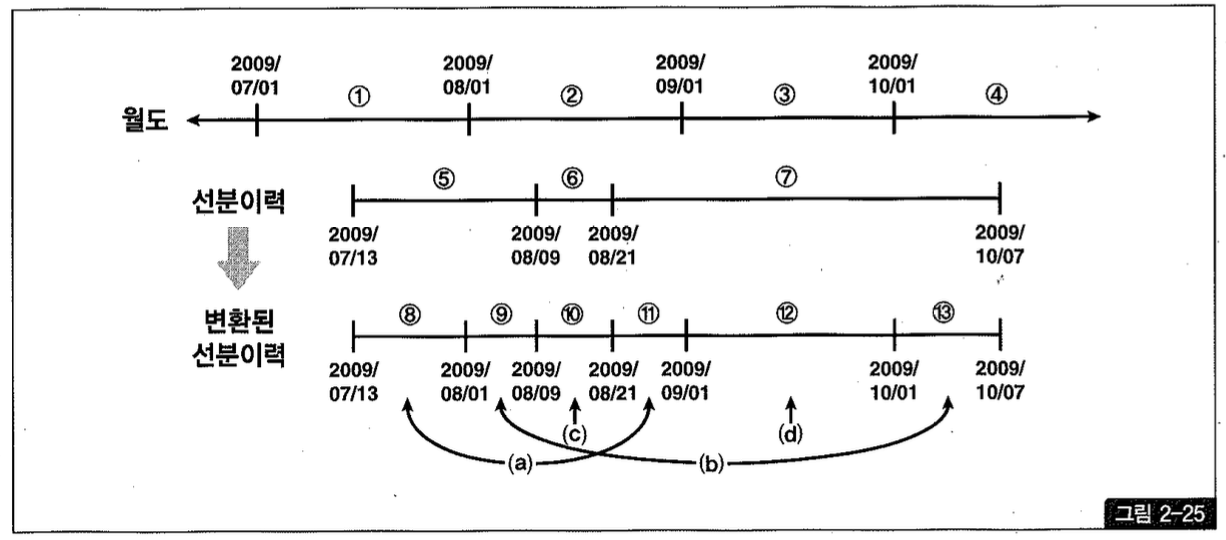
그리고 그림과 표를 자세히 분석하면 좀 더 간단한 규칙을 발견할 수 있는데, 겹치는 구간의 시작일자는 두 시작일자 중 큰 값을 취하면 되고 종료일자는 두 종료일자 중 작은 값을 취하면 된다. 따라서 최종적으로는 아래와 같이 쿼리하는 것이 가장 좋다.
1
2
3
4
5
6
7
select b.상품번호,
greatest(a.시작일자, b.시작일자) as 시작일자,
least(a.종료일자, b.종료일자) as 종료일자,
b.데이터
from 월도 a, 선분이력 b
where b.시작일자 = a.종료일자
and b.종료일자 >= a.시작일자;
(3) 데이터 복제를 통한 소계 구하기
쿼리를 작성하다보면 데이터 복제 기법을 활용해야 할 때가 많다. 방금 두 사례는 부등호 조인을 이용한 데이터 복제 방법이었는데, 일부러 카티션 곱(Cartesian Product)을 발생시켜 복제하기도 한다. 전통적으로 많이 쓰던 방식은 아래와 같은 복제용 테이블(copy)을 미리 만들어두고 이를 활용하는 것이다.
1
2
3
4
5
6
7
create table copy_t ( no number, no2 varchar2(2));
insert into copy_t
select rownum, lpad(rownum, 2, '0') from all_tables where rownum <= 31;
alter table copy_t add constraint copy_t_pk primary key (no);
create unique index copy_t_no_idx on copy_t (no2);
이제 아래 쿼리를 수행하면 emp 테이블에 있는 14개 레코드가 3개씩 총 42개로 복제된다.
1
2
select * from emp a, copy_t b
where b.no < 3;
오라클 9i부터는 dual 테이블을 사용하면 편하다. 아래와 같이 dual 테이블에 start with 절 없는 connect by 구문을 사용하면 두 개의 집합이 자동으로 만들어진다.
1
2
3
4
5
6
select rownum no from dual connect by level <= 2;
NO
----------
1
2
이 방법을 사용해 emp 테이블을 복제하는 방법은 아래와 같다.
1
2
3
4
5
select * from emp a, (select rownum no from dual connect by level < 2) b;
......
28 개의 행이 선택되었습니다.
데이터 복제 기법을 활용하면 아래와 같이 단일 SQL로도 부서별 소계를 구할 수 있다.
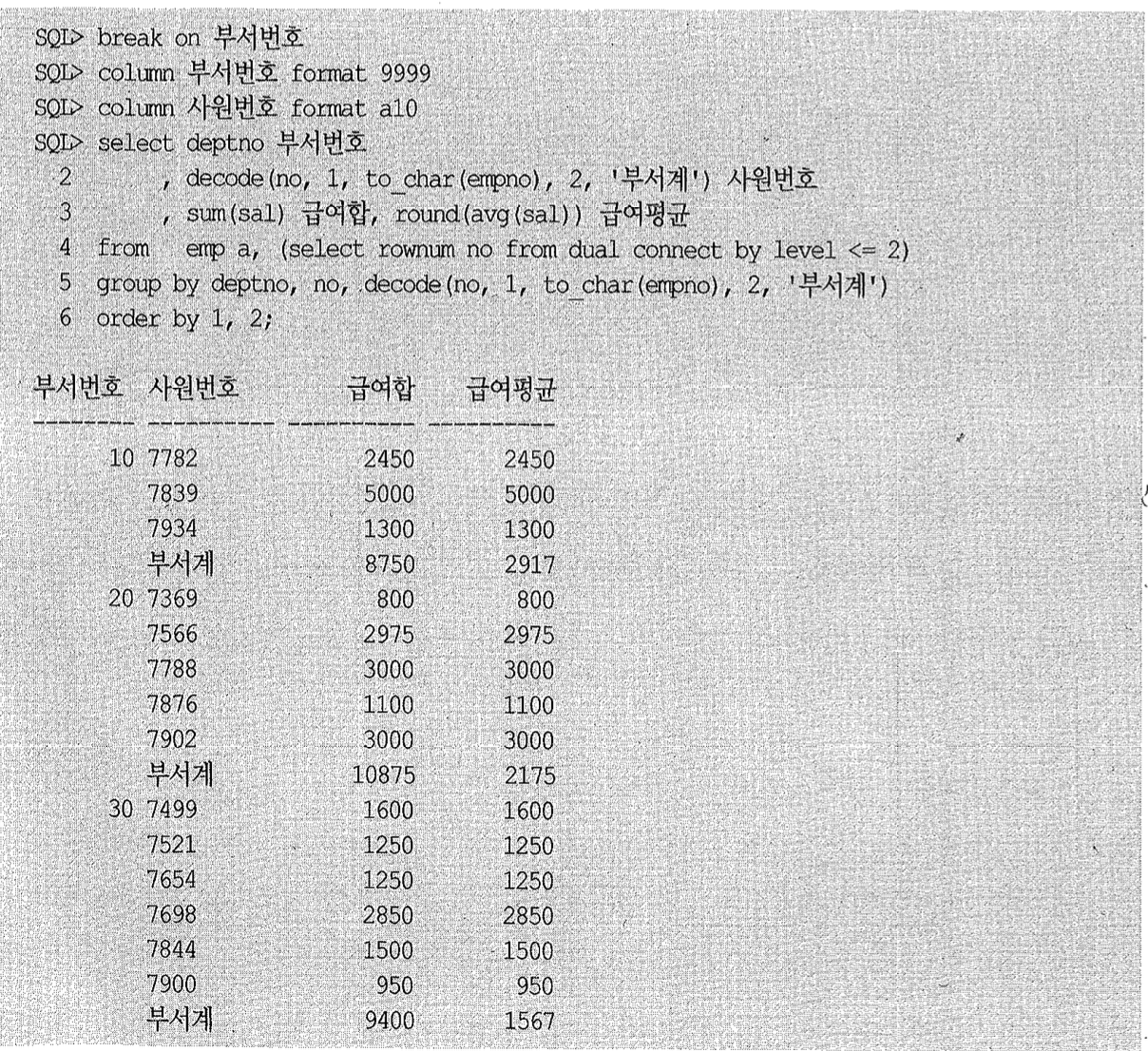
이처럼 group by를 잘 구사하면 우리가 원하는 데이터 집합을 자유자재로 가공해낼 수 있다. 아래는 세 개로 복제하고서 총계까지 구하는 사례다.
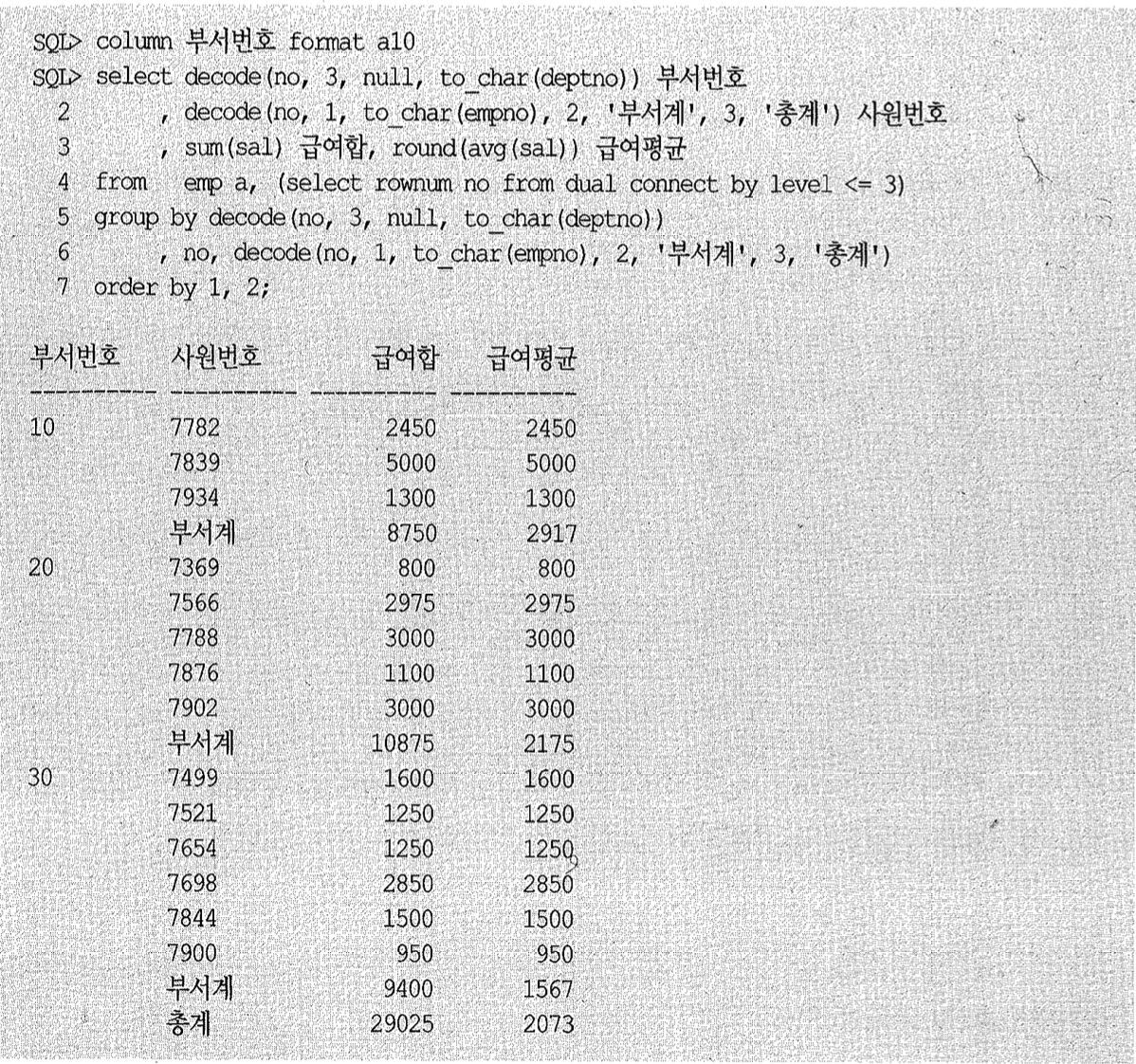
물론 표준 rollup 구문을 사용하면 데이터 복제 기법을 쓰지 않고도 아래와 같이 간편하게 소계 및 총계를 구할 수 있다.

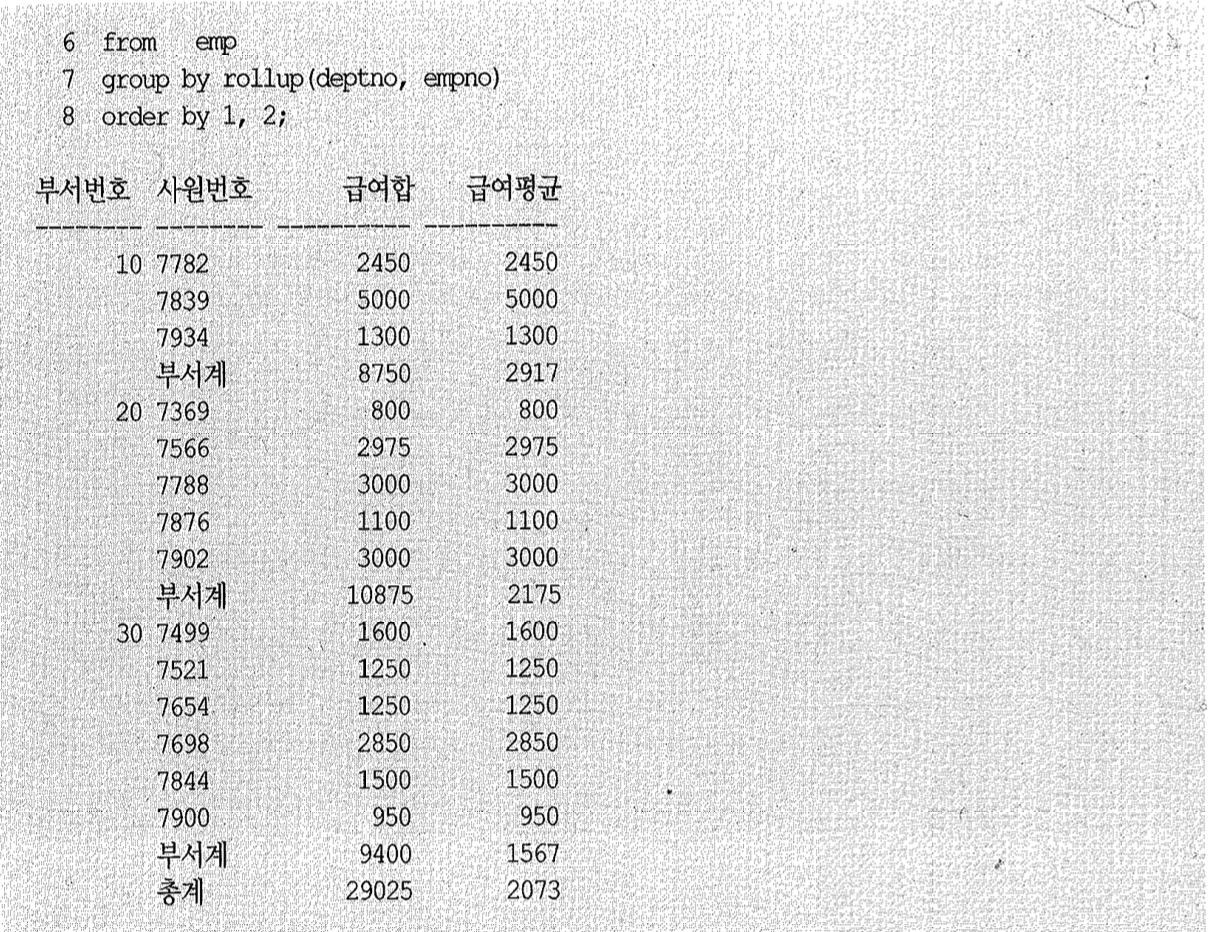
(4) 상호 배타적 관계의 조인
어떤 엔티티가 두 개 이상의 다른 엔티티의 집합과 관계(Relationship)를 갖는 것을 ‘상호 배타적(Exclusive OR) 관계’라고 한다. 그림2-26에서 상품권 결제 테이블과 온라인권 및 실권 테이블과의 관계가 여기에 해당하며, 관계선에 표시된 아크(arc)를 확인하기 바란다.
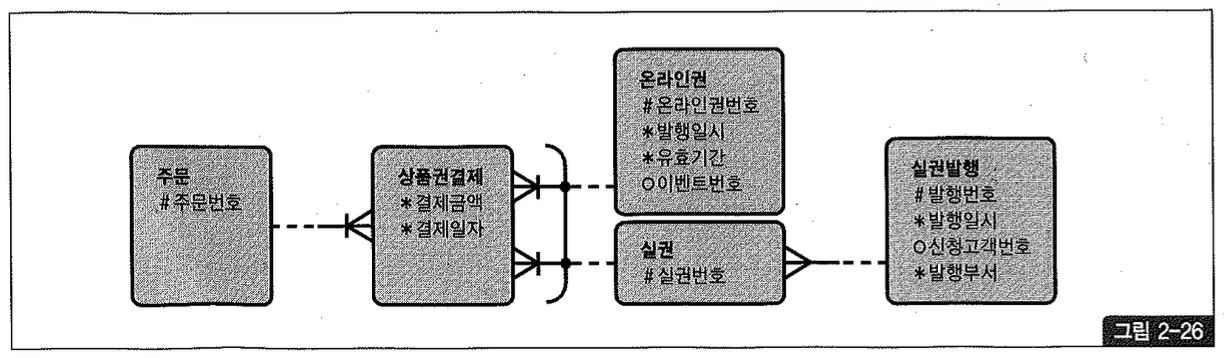
그림2-26과 같은 데이터 모델을 실제 데이터베이스로 구현할 때, 상품권 결제 테이블에는 아래 두 가지 방법 중 하나를 사용한다.
- 온라인권번호, 실권번호 두 컬럼을 따로 두고, 레코드별로 둘 중 하나의 컬럼에만 값 입력한다.
- 상품권구분과 상품권번호 컬럼을 두고, 상품권구분이 1일 때는 온라인권번호를 입력하고 2일 때는 실권번호를 입력한다.
1번처럼 설계할 때는 아래와 같이 Outer 조인으로 간단하게 쿼리를 작성할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
select /*+ ordered use n1 (b) use n1 (e) use 1n (d) */ a.주문번호, a.결제일자, a.결제금액
, nvl( b. 온라인권번호, c.실권번호) 상품권번호
, nvl(b.발행일시, d.발행일시) 발행일시
from
상품권결제a, 온라인권b, 실권c, 실권발행d
where
a.결제일자 between :dt1 and :dt2
and
b.온라인권번호(+) = a.온라인권번호
and
c.실권번호(+) = a.실권번호
and
d.발행번호(+) = c.발행번호;
2번처럼 설계했을 때는 약간의 고민이 필요한데, 가장 쉽게 생각할 수 있는 방법은 아래와 같이 union all을 이용하는 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
select x.주문번호, x.결제일자, x.결제금액, y.온라인권번호 상품권번호, y.발행일시 from
상품권결제x, 온라인권y
where x.상품권구분= '1'
and
x.결제일자 between :dt1 and :dt2
and
y.온라인권번호 = x.상품권번호
union all
select x.주문번호, x.결제일자, x.결제금액, y.실권번호 상품권번호, z.발행일시 from
상품권결제x, 실권y, 실권발행z
where x.상품권구분= '2'
and
x.결제일자 between :dt1 and :dt2
and
y.실권번호 = x.상품권번호
and
z.발행번호 = y.발행번호;
union all을 중심으로 쿼리를 위아래 두번 수행했지만 만약 [상품권구분+결제일자] 순으로 구성된 인덱스를 이용한다면 읽는 범위에 중복은 없다. 하지만 [결제일자+상품권구분] 순으로 구성된 인덱스를 이용할 때는 인덱스 스캔 범위에 중복이 생기고, [결제일자]만으로 구성된 인덱스를 이용한다면 상품권구분을 필터링하기 위한 테이블 Random 액세스까지 중복해서 발생할 것이다.
그럴 때는 아래와 같이 쿼리함으로써 중복 액세스에 의한 비효율을 해소할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
select /*+ ordered use n1 (b) use n1 (c) use n1 (d) */
a.주문번호, a.결제일자, a.결제금액
, nvl( b.온라인권번호, c.실권번호) 상품권번호
, nvl(b.발행일시, d.발행일시) 발행일시
from 상품권결제a, 온라인권b, 실권c, 실권발행d
where a.결제일자 between :dt1 and :dt2
and
b.온라인권번호(+) = decode(a.상품권구분, 1, a.상품권번호)
and
c.실권번호(+) = decode(a.상품권구분, 2, a.상품권번호)
and
d.발행번호(+) = c.발행번호;
(5) 최종 출력 건에 대해서만 조인하기
아래는 화면 페이지 처리 시 흔히 사용되는 방식이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT * FROM
(
SELECT A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명,
COUNT(*) OVER() TOTAL_COUNT
FROM 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE A.게시판유형 = :TYPE
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호
)
WHERE ROWNUM <= 31
AND NO BETWEEN 21 AND 30;
전체 게시판 데이터는 수백만 건이고, 특정 게시판 유형(게시판유형=:TYPE)에 속하는 데이터는 평균 10만 건에 이른다. 게다가 회원, 게시판 유형, 질문 유형 3개 테이블과의 조인까지 수행하므로 성능이 좋을 리 없다. 인덱스 구성은 아래와 같아서 소트 오퍼레이션이 불가피하다.
≫ 게시판X01: 게시판유형 + 등록일자DESC + 번호
아래 실행 계획을 보면, 10만 건을 읽어 나머지 세 테이블과의 조인을 모두 완료한 후에 소트 단계에서 stopkey가 작동(id=5)하고 있다.

튜닝을 위해 게시판XO1인덱스에 질문유형 컬럼을 추가하자. 인덱스 컬럼 순서를 바꾸는 결정을 하기는 쉽지 않지만 뒤쪽에 추가하는 것은 그다지 어렵지 않다.
≫ 게시판X01: 게시판유형 + 등록일자DESC + 번호 + 질문유형
위처럼 인덱스를 구성했다면 이제 게시판 테이블로부터 ‘게시판유형=:TYPE’ 조건에 해당하는 레코드를 찾는 작업은 인덱스 내에서 해결 가능하다. 아래처럼 인덱스만 읽도록 쿼리를 작성해 보자.
1
2
3
4
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호;
읽은 레코드를 정렬하는 작업은 피할 수 없지만, 인덱스 블록만 읽으면 되기 때문에 이전보다 훨씬 빠르게 수행될 것이다.
다른 세 개 테이블과의 조인 컬럼, 그리고 Select-list에서 참조되는 컬럼을 어떻게 읽어올 것인지가 문제인데, 이들 컬럼은 페이지 처리가 모두 완료돼 최종 결과 집합으로 확정된 10 건에 대해서만 액세스하면 된다. 그럴 목적으로 인덱스를 스캔할 때 rowid 값을 같이 읽어온 것이다. 최종적으로 완성된 쿼리는 아래와 같다.


게시판 테이블을 두 번 읽도록 쿼리를 작성했지만 인라인 뷰 내에서는 인덱스만 읽도록 했고, 두 번째 게시판 테이블(A)을 액세스할 때는 앞서 읽은 rowid 값으로 직접 액세스하기 때문에 인덱스를 경유해 한 번만 테이블을 액세스하는 것과 같은 일량이다. 실행 계획에 TABLE ACCESS BY INDEX ROWID가 아니라 TABLE ACCESS BY USER ROWID로 표시된 것에 주목하자.
회원, 게시판 유형, 질문 유형 테이블과의 조인 컬럼인 작성자번호, 게시판 유형, 질문 유형이 Null 허용 컬럼일 때는 결과가 달라지지 않느냐고 반문하는 독자가 있을 것이다. 예리한 질문이다.
우선, 실제 Null 값이 존재하는지 확인해봐야 한다. 업무적으로 Null 값이 허용되지 않는데도 컬럼에 Not null 제약을 설정하지 않는 경우가 매우 흔하기 때문이다.
두 번째는, 이들 컬럼이 Null 값이라고 해서 게시판 출력 리스트에서 제외되는 것이 업무적으로 맞는지 확인해볼 필요가 있다. 아마도 Outer 조인을 해야 옳은데, 개발자가 간과한 경우일 수 있다. 필자가 튜닝 결과서를 개발팀에 전달하면서 확인해보면 많은 경우가 그랬다. 그렇다면, 위 쿼리에 아래처럼 Outer 기호(+)만 붙여주면 된다.
1
2
3
4
WHERE X.NO BETWEEN 21 AND 30 AND A.ROWID = X.RID
AND B.회원번호(+) = A.작성자번호
AND C.게시판유형(+) = A.게시판유형
AND D.질문유형(+) = A.질문유형
만약 업무적으로 그런 레코드를 제외하길 원한다면, Null 값을 허용하는 조인 컬럼들에 대해 인라인 뷰 안에 아래처럼 is not null 조건을 추가해주어야 한다.
1
2
3
4
WHERE 게시판유형 = :TYPE
AND 작성자번호 IS NOT NULL
AND 게시판유형 IS NOT NULL
AND 질문유형 IS NOT NULL
조건절을 추가하는 것은 어렵지 않지만 이들 컬럼도 인덱스 구성에 포함해주어야 하므로 추가적인 고민이 필요하다.
인덱스만 읽고 페이지 처리되도록 유도할 수 있으면 좋지만 이렇게 컬럼이 많아져 인덱스 조정이 여의치 않을 때는, 아래처럼 차선책을 택하는 것을 고려해볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SELECT /*+ ORDERED USE NL (B) USE NL (C) USE NL (D) */
A.등록일자, B.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, A.CNT FROM
(SELECT A.*, ROWNUM NO, COUNT (*) OVER () CNT FROM
(SELECT 등록일자, 번호, 제목, 작성자번호, 게시판유형, 질문유형 FROM 게시판
WHERE 게시판유형 = :TYPE
AND
작성자번호 IS NOT NULL
AND
게시판유형 IS NOT NULL
AND
질문유형 IS NOT NULL
ORDER BY 등록일자 DESC, 질문유형, 번호
) A
WHERE ROWNUM <= 31
) A, 회원B, 게시판유형C, 질문유형D WHERE A.NO BETWEEN 21 AND 30
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
앞에서는 게시판 테이블을 처음 액세스할 때 인덱스 컬럼과 rowid만 읽었지만 여기서는 테이블까지 액세스하도록 했으므로 전체를 읽어 정렬하는 부하는 피할 수 없다. 하지만, 불필요한 조인 횟수를 줄이는 것만으로도 상당한 성능 개선 효과를 얻을 수 있다.
반정규화는 성능을 위한 최후의 수단
정규화된 모델로는 제대로 성능을 내기 어려울 때만 반정규화를 단행하는 게 관계형 데이터베이스를 구현하는 정석이야. 그럼에도 성능이 좋지 않을 것을 예단하고 논리 데이터 모델링 단계에서 미리 반정규화를 실시하는 설계자나 개발팀을 자주 봐. 더 큰 문제는, 같이 프로젝트를 한 후배 개발자들이 그것을 답습하고 으레 그렇게 설계하는 것이 정석이라고 여긴다는 사실이다.

예를 들어, 업무 연락 메시지 게시판을 구현하기 위한 데이터 모델을 열어보면 열 받을 발송 메시지 건수, 수신인 수 같은 추출(derive) 속성들이 설계돼 있다.
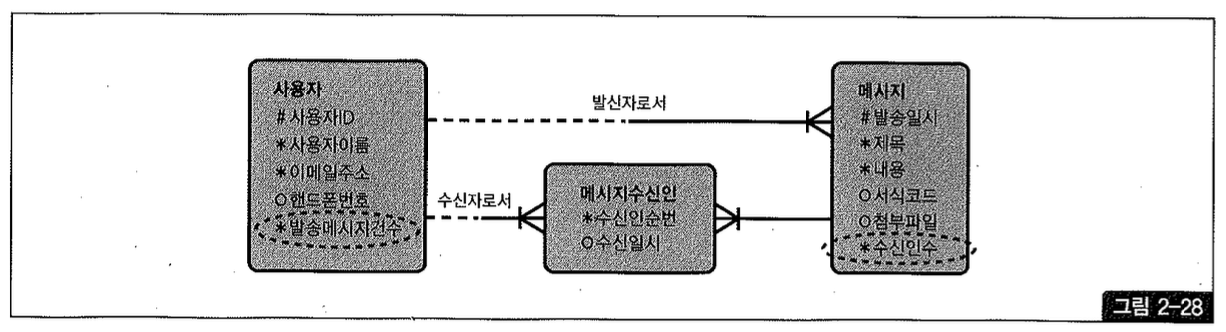
만약 그런 업무를 아래와 같은 SQL 패턴으로 개발했다면 수신 확인자 수와 수신 대상자 수를 세고 새글 여부를 확인하는 스칼라 서브쿼리 때문에 성능 문제를 겪었을 거야. 이를 해결하지 못 하 면 그림 2-28처럼 설계 하 게 마련이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
SELECT ...
FROM (
SELECT ...
FROM (
SELECT
a.발신자ID,
a.발송일시,
a.제목,
b.사용자이름 AS 보낸이,
(SELECT COUNT(수신일시) FROM 메시지수신인 ...) AS 수신확인자수,
(SELECT COUNT(*) FROM 메시지수신인 ...) AS 수신대상자수,
(CASE WHEN EXISTS (
SELECT "x" FROM 메시지수신인
WHERE 발신자ID = a.발신자ID
AND 발송일시 = a.발송일시
AND 수신자ID = :로그인사용자ID
AND 수신일시 IS NOT NULL
) THEN 'Y' END
) AS 새글여부
FROM 메시지 a, 사용자 b
WHERE b.사용자ID = a.발신자ID
ORDER BY a.발송일시 DESC
) a
WHERE ROWNUM <= 30
)
WHERE no BETWEEN 21 AND 30
위와 같은 추출 속성을 도입하면 메시지를 수신할 때마다 메시지 테이블의 수신인 수를 갱신해주는 DML, 프로그램도 같이 작성해야 해. 메시지 수신은 늘 일어나는 업무이기 때문에 빠뜨리 지 않고 구현하겠지만, 문제는 일상적이지 않은 업무 때문에 데이터 정합성이 훼손될 수 있다는 데에 있다. 예를 들어 사용자가 탈퇴하면 메시지 수신인 수도 일괄적으로 갱신해주어야 하는데, 그런 처리를 실수로 빠뜨리기 쉽다.
반정규화를 실시했으면 업무 규칙 누락이 생기지 않도록 꼼꼼히 점검해야 한다. 그보다는 반정규화 없이 성능 문제를 해결할 수 있다면 가장 좋다.
앞에서 설명했던 원리를 적용해 쿼리를 아래와 같이 바꾼다면 최종 출력되는 10 건에 대해서만 수신 정보와 새글 여부를 확인하기 때문에 굳이 추출 속성을 두지 않고도 성능 문제를 해결할 수 있다. 데이터베이스 설계자에게 DB 성능 원리에 대한 깊이 있는 연구가 필요한 이유가 여기에 있다.
1
2
3
4
5
6
7
8
9
10
11
12
SELECT a.발신자ID, a.발송일시, a.제목, b.사용자이름 AS 보낸이,
(SELECT COUNT(수신일시) / COUNT(*) FROM 메시지수신인) AS 수신확인,
(CASE WHEN EXISTS() THEN 'Y' END) AS 새글여부
FROM (
SELECT ROWNUM no,
FROM (
SELECT 발신자ID, 발송일시, 제목 FROM 메시지
ORDER BY 발송일시 DESC
) WHERE ROWNUM <= 30
) a, 사용자 b
WHERE a.no BETWEEN 21 AND 30
AND b.사용자ID = a.발신자ID
(6) 징검다리테이블조인을이용한튜닝
앞서 조인으로 인한 성능 저하를 우려해 논리 데이터 모델링 단계에서 자주 반정규화를 하는 경우를 보았는데, 오히려 FROM 절에서 조인되는 테이블 개수를 늘려 성능을 향상시키는 사례를 보이고자 한다.
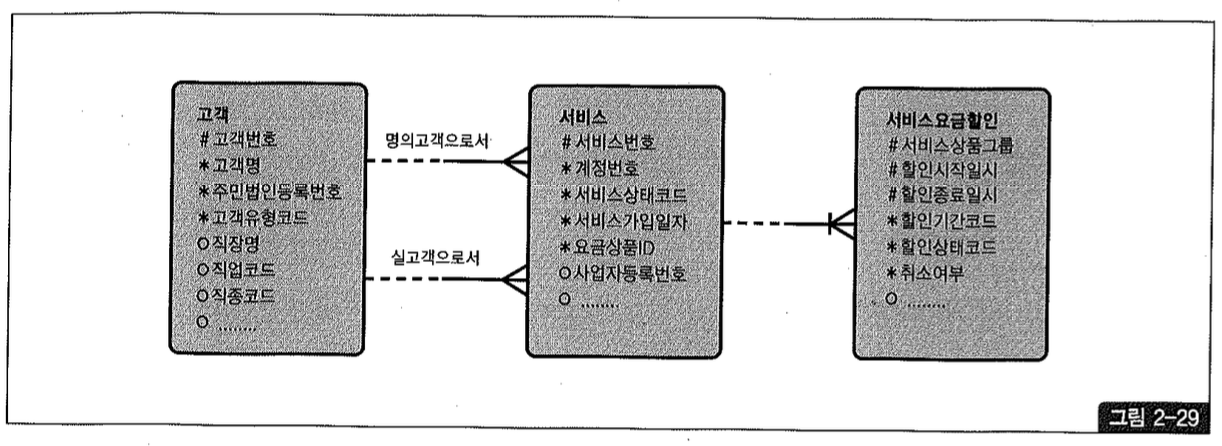
아래는 그림 2-29와 같은 데이터 모델에서 고객의 할인 혜택을 조회하는 쿼리다.
1
2
3
4
5
6
7
8
SETECT /*+ordereduse_nl(s z) */ c.고객번호, s.서비스번호, s.서비스구분코드, s.서비스상태코드, s.서비스상태변경코드, r.할인시작일자, r,할인종료일자
from 고객 c, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctzbiz_num
and s.명의고객번호 = c.고객번호
and r.서비스번호 = s.서비스번호
and r.서비스상품그룹 = '3001'
and r.할인기간코드 = '15'
order by r.할인종료일자 desc, s.서비스번호
인덱스 구성은 다음과 같다.
1
2
3
4
고객_NI : 주민법인등록번호
서비스_N2 : 명의고객번호 + 서비스번호
서비스요금할인_PK : 서비스번호+ 서비스상품그룹
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드
위 쿼리를 수행했더니 아래와 같이 서버 구간에서만 28초가 걸렸고, 블록 I/O는 226,673번이 발생하였다.
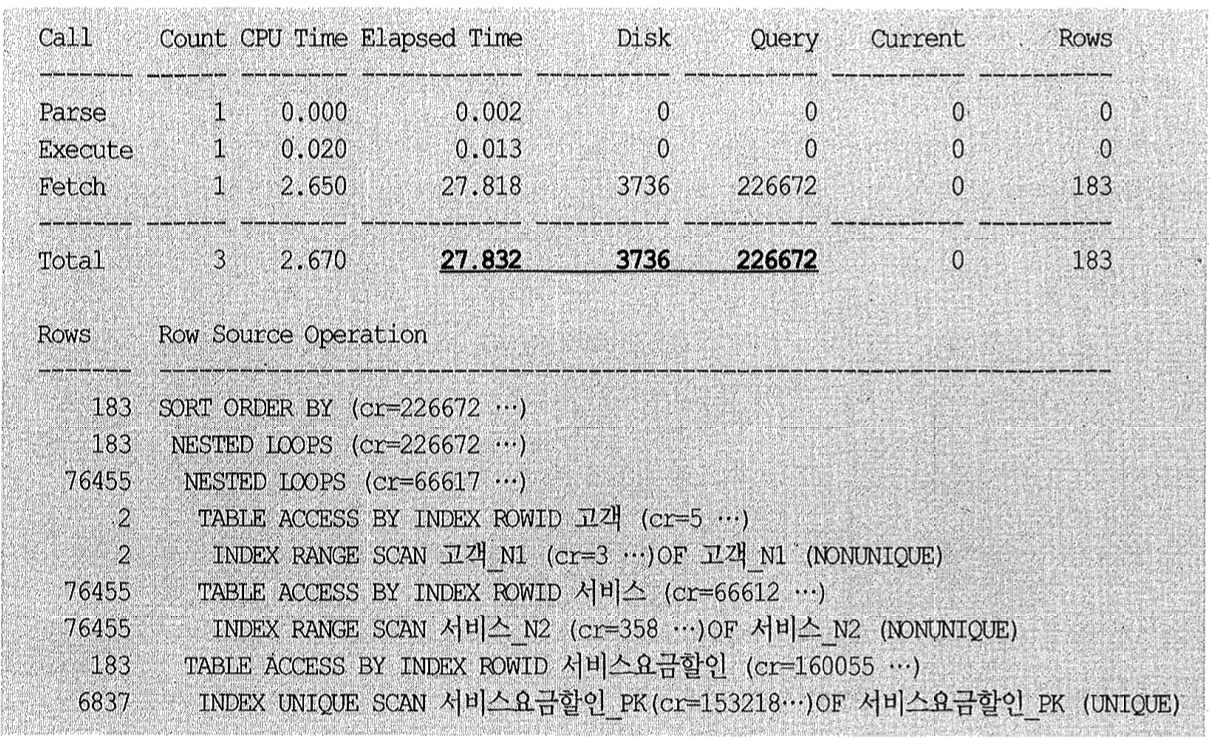
그림 2-30은 위 Row Source Operation의 처리과정을 표현한 것이고, 각 오퍼레이션 단계에서의 출력건수와 블록 I/O 발생량을 함께 표시하였다.
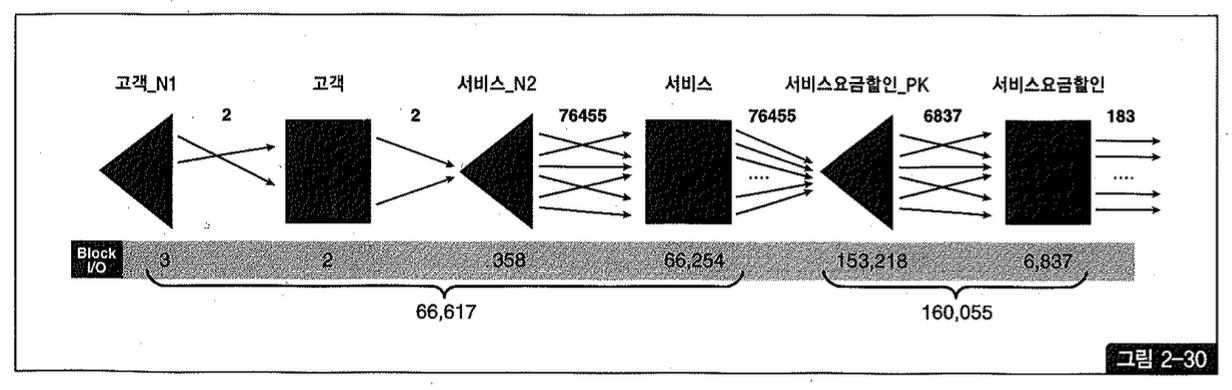
최종 건수는 183건에 불과하지만, 고객 테이블을 먼저 드라이빙해서 서비스 테이블과 NL 조인하는 과정에서 이미 66,617개의 블록 I/O가 발생했고, 이어서 서비스 요금 할인 테이블과 NTIL 조인하는 과정에서 160,055개의 블록 I/O가 추가로 발생했다. 총 블록 I/O 개수는 226,672이다.
조인 순서를 바꿔 서비스 요금 할인 테이블이 먼저 드라이빙되도록 하면 어떨까?
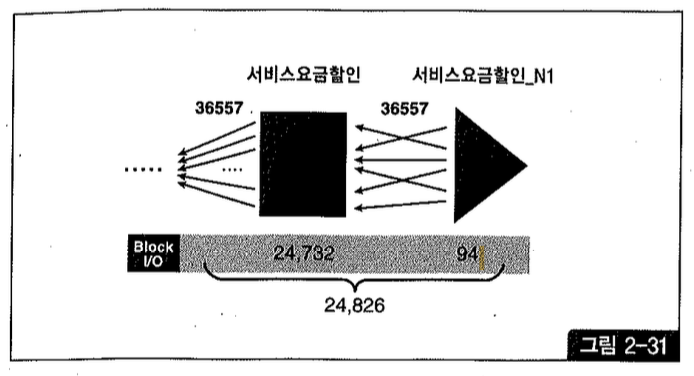
그림 2-31에서 보듯 “할인기간코드=15 and 서비스상품그룹=3001” 조건에 부합하는 레코드가 36,57건이고, 이 테이블을 액세스하는 단계에서 이미 24,826개의 블록 I/O가 발생한다. 따라서 조인 순서를 바꾸더라도 조인 액세스량을 줄이기는 어려운 상황이다.
해시 조인으로 유도하더라도 (91,443-66,617+24,826)개의 블록 I/O가 발생할 것임을 짐작할 수 있다. 그렇게라도 하면 I/O가 절반이상 줄기 때문에 조금은 빨라지겠지만 그다지 만족스러운 속도는 아닐 것이다.
이처럼 최종 결과 건수는 얼마 되지 않으면서, 필터 조건만으로 각 부분을 따로 읽으면 결과 건수가 아주 많을 때 튜닝하기가 가장 어렵다. NL 조인 과정에서 Random I/O 부하가 심하게 발생하기 때문이며, 어느 쪽으로 드라이빙하더라도 결과는 마찬가지다.
튜닝을 위해서 서비스 요금 할인 NI 인덱스에 아래와 같이 서비스번호 컬럼을 추가해보자.
1
서비스요금할인NI: 서비스상품그룹+할인기간코드+서비스번호
그리고 서비스와 서비스요금할인을 한 번씩 더 조인하도록 쿼리를 아래처럼 변경했다.

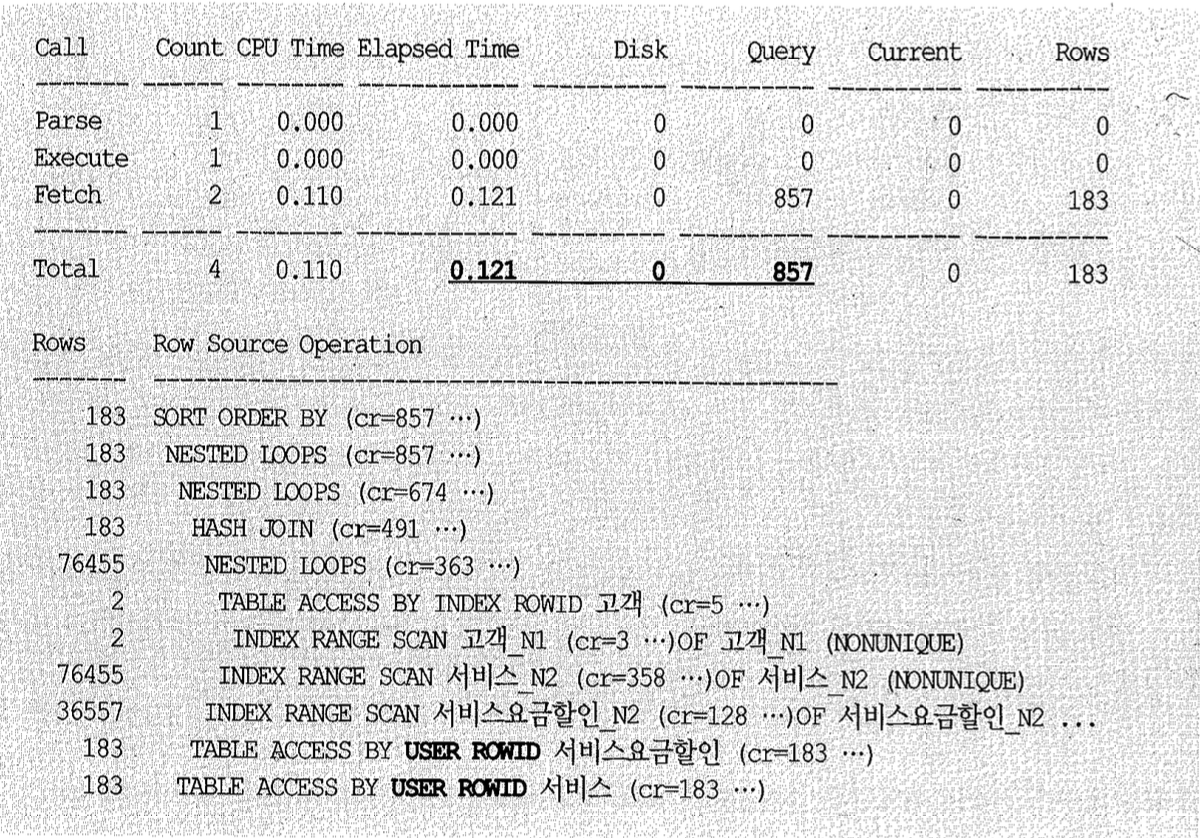
튜닝 전에 26,672개 블록을 읽으면서 27.8초 걸리던 쿼리가 857개 블록을 읽으면서 0.12초 만에 수행을 완료했다.
튜닝 전 쿼리 성능이 느린 이유가 조인 부하 때문이었는데, ‘서비스’와 ‘서비스요금할인’ 테이블을 한 번씩 더 조인(From 절 2번)함으로써 I/O가 줄면서 성공적으로 튜닝이 되었다. 어떻게 된 것일까?
양쪽 테이블에서 인덱스만 읽은 결과끼리 먼저 조인하고서 최종 결과 집합 183건에 대해서만 테이블을 액세스하도록 한 것이 핵심 아이디어다. 그렇게 하려고 앞서 서비스 요금 할인 NI 인덱스에 조인 컬럼 ‘서비스번호’를 추가했던 것이다.
참고로 테이블 별칭(alias)으로 각각 brdg 접미사를 사용했는데, 테이블 액세스량을 줄이기 위한 징검다리 조인을 추가했다는 의미에서 ‘bridge’의 약어를 사용한 것이다.
인조식별자 사용에 의한 조인 성능 이슈
액세스 경로에 대한 고려 없이 인조식별자를 설계하면, 위와 같은 조인 성능 이슈가 자주 발생한다.
그림 2-3을 보면, ‘주문’ 테이블 식별자인 ‘주문일자’와 ‘주문순번’ 컬럼을 자식 테이블 ‘주문상세’의 식별자로 상속시켰다. UID Bar(관계선 오른쪽 수직선)가 그것을 의미한다. 주문번호는 주문 일자와 주문순번을 조합하는 규칙에 따라 출력 시점에 생성해낸다. (인조식별자가 조인 성능에 미치는 영향을 쉽게 설명하기 위한 예시일뿐이며, 이렇게 구현해야 좋다는 의미가 아님을 미리 밝힌다.)
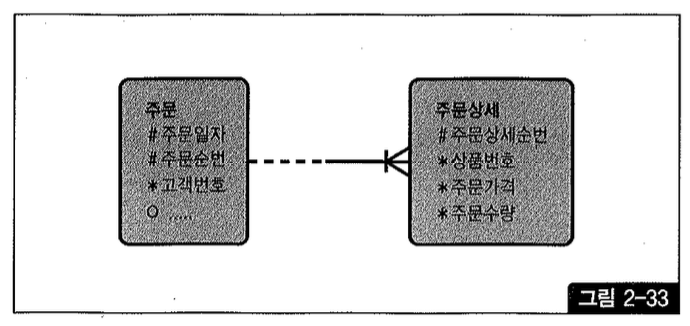
데이터가 상당히 많지만 그림 2-33과 같은 모델이라면 특정 주문일자에 발생한 특정 상품의 주문금액을 집계하는 아래 쿼리에 효과적으로 대응할 수 있다.
1
2
3
4
5
6
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문, 주문상세
where 주문.주문일자 = 주문상세.주문일자
and 주문.주문순번 = 주문상세.주문순번
and 주문.주문일자 = '20090315'
and 주문상세.상품번호 = 'AC001'
주문상세쪽 인덱스를 [상품번호+주문일자] 또는 [주문일자+상품번호] 순으로 구성해주기만 하면 된다. (위 쿼리에서 주문일자 조건을 주문상세쪽에 따로 기술하지 않았지만 조인문을 타고 전달된다. 옵티마이저가 내부적으로 쿼리를 변환한 것이며, 자세한 설명은 4장 5절 ‘조건 이행 예’를 참조하기 바란다.)
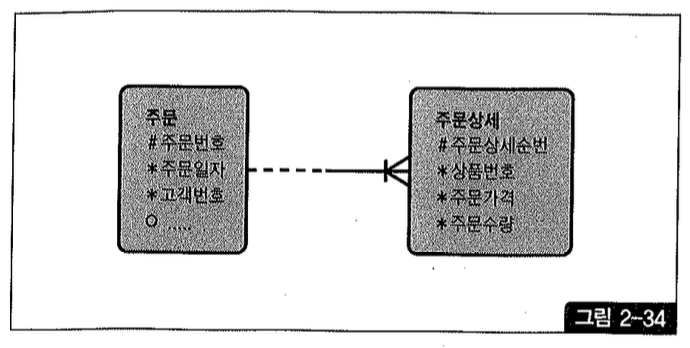
반면, 그림 2-34처럼 ‘주문번호’라는 인조식별자 컬럼을 따로 둔다면 주문상세 테이블에 ‘주문일자’ 속성이 상속되지 않음으로 말미암아 조인 과정에 큰 비효율을 일으킨다.
1
2
3
4
5
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문, 주문상세
where 주문.주문번호 = 주문상세.주문번호
and 주문.주문일자 = '20090315'
and 주문상세.상품번호 = 'AC001'
인덱스 구성은 다음과 같다.
1
2
3
4
주문_PK : 주문번호
주문_X01 : 주문일자
주문상세PK : 주문번호+주문상세순번
주문상세X01 : 상품번호
주문 테이블에서 읽은 100,000건에 대해 주문상세쪽으로 100,000번의 조인 액세스가 일어날 텐데, 주문상세PK 인덱스를 거쳐 주문상세 테이블을 100,000번 액세스하고서 상품번호=’ACO01’ 조건을 필터링하고 나면 최종적으로 600건 정도만 남고 모두 버려진다. 주문상세_X01 인덱스에 주문번호를 추가하고 이 인덱스를 이용하면 테이블 Random 액세스는 줄일 수 있지만 조인 시도 횟수는 줄지 않는다.
주문상세 테이블을 먼저 읽으면 상황은 더 나빠진다. 두 테이블의 보관 주기가 1년이라면 상품번호 당 평균 카디널리티가 219,000건(=100,000 x 6100 x 365)이므로 주문 테이블 쪽으로 그만큼의 조인 액세스가 발생할 것이고, PK 인덱스를 거쳐 주문 테이블을 219,000번 액세스하고서 “주문일자=’20090315’” 조건을 필터링하고 나면 600건 정도만 남기고 모두 버려지므로 이만저만한 비 효율이 아니다.
주문_X01 인덱스에 주문번호를 추가하고 이 인덱스를 이용하면 테이블 Random 액세스는 줄일 수 있지만 조인 시도 횟수는 줄지 않는다.
해시 조인으로 유도하더라도 인덱스를 거쳐 각각 100,000건과 219,000건의 데이터를 읽는 과정에서 이미 상당량의 테이블 Random 액세스가 발생할 것이고, 조인해야 할 일량이 많아서 시스템 리소스(CPU, 메모리)를 많이 사용하게 된다.
앞서 소개한 튜닝 기법을 사용하면 Random 액세스를 최소화함으로써 속도를 개선할 수는 있지만 근본적인 처방이라고 할 수 없다.
지금까지 설명한 내용은 인조식별자를 두는 것이 조인 성능에 미치는 영향을 예시하기 위한 것일뿐 주문번호를 식별자로 두는 것이 나쁜 모델임을 강조하려는 것은 아니다. 주문 테이블이 많은 자식 엔티티와 관계를 가지거나 ‘주문번호’라는 용어가 업무적으로 이미 통용되는 경우(예를 들어, 회원번호, 지점번호, 상품번호, 전표번호처럼)라면 그림 2-34처럼 설계하는 것이 자연스럽다. 그럴 때는 ‘주문일자’ 컬럼을 주문상세 테이블로 반정규화하는 것이 가장 효과적인 해법일 것이다.
인조식별자를 둘 때 주의사항
인조식별자를 두면 PK, FK가 단일 컬럼으로 구성되므로 테이블간 연결 구조가 단순해지고, 이들 제약조건을 위해 사용되는 인덱스 저장공간이 최소화되는 장점이 있다. 그리고 다중 컬럼으로 조인할 때보다 아무래도 조인 연산을 위한 CPU 사용량이 조금 줄 수 있다.
하지만 조인 연산할 때의 CPU 사용량 감소는 아주 미한 수준이고, 오히려 앞서 설명한 사례처럼 조인 연산 횟수와 블록 I/O 증가로 더 많은 시스템 리소스를 낭비하기 쉽다.
액세스 범위를 줄이지 못하면서 단지 조인을 위해서만 사용되는 PK 인덱스가 많이 양산될 수 있고, 데이터 모델이 이해하기 어려워진다(실질 식별자를 찾기 어려워 엔티의 가독성이 떨어짐)는 측면도 무시할 수 없다. 그 때문에 프로그램을 잘못 개발하는 경우도 종종 있다.
업무적으로 이미 통용되는 식별자이거나 유연성/확장성을 고려(데이터 타입이나 값이 변경될 가능성에 대비)해 인조식별자를 설계하는 경우를 제외하면 논리적인 데이터 모델링 단계에서는 가급적 인조식별자를 두지 않는 것이 좋다. 의미상 주어에 해당하는 속성들(Natural Keys)을 그대로 식별자로 사용했다가 나중에 물리 설계 단계에서 저장 효율과 액세스 효율 등을 고려해 결정하는 것이 바람직하다.
(7) 점이력 조회
그림 2-35처럼 데이터 변경이 발생할 때마다 변경일자와 함께 새로운 이력 레코드를 쌓는 방식을 ‘점이력’이라고 흔히 말하는데, 이와 같은 모델에서 이력 레코드를 빠르게 조회하는 방법에 대해 알아보자.
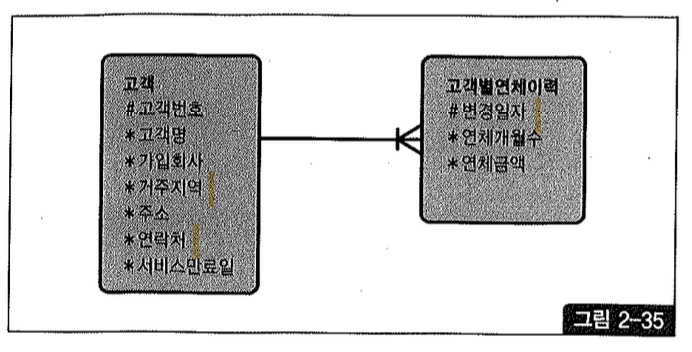
점이력 모델에서 이력을 조회할 때 흔히 아래와 같이 서브쿼리를 이용한다(스크립트 Ch2.14.kt 참조). 즉, 찾고자 하는 시점(서비스 만료일)보다 앞선 변경일자 중 가장 마지막 레코드를 찾는 것이다.

실행 계획을 보면 다행스럽게도, 서브쿼리 내에서 서비스 만료일보다 작은 레코드를 모두 스캔하지 않고 오라클이 인덱스를 거꾸로 스캔하면서 가장 큰 값을 찾는 방식(7번째 라인 first ON, 8번째 라인 min/max, 오라클 8버전에서 구현된 기능)을 사용했다.
서브쿼리를 아래와 같이 바꿀 수 있지만 실제 수행해보면 서브쿼리 내에서 액세스되는 인덱스 블록에 대한 버퍼 Pinning 효과가 사라져 블록 I/O가 더 많이 발생한다.
| index_desc 힌트와 rownum <= 1 조건 사용 시, 주의사항 |
|---|
| 이후에도 index_desc(또는 index) 힌트와 함께 rownum <= 1 조건을 사용하는 튜닝 기법을 자주 소개하므로 독자에게 미리 한 가지 주의사항을 일러두고자 한다. 이 기법을 사용했는데 나중에 인덱스 구성이 변경되면 쿼리 결과가 틀리게 될 수 있음을 반드시 기억하기 바란다. 따라서 First row(min/max) 알고리즘이 작동할 때는 반드시 min/max 함수를 사용하는 것이 올바른 선택이다. 하지만 낮은 성능 때문에 어쩔 수 없이 index(또는 Index_desc) + rownum 조건을 써야만 하는 경우가 생길 수 있고, 그 때는 이들 프로그램 목록을 관리했다가 인덱스 구성 변경시 확인하는 프로세스를 반드시 거쳐야 한다. 참고로, 아래처럼 min 또는 max 함수 내에서 컬럼을 가공하면 First row 알고리즘이 작동하지 않는다.  아래는 first_row 알고리즘이 작동할 때의 실행 계획이다.  바로 이어서 설명할 스칼라 서브쿼리도 아래와 같이 max 함수를 사용하고 싶지만 first row 알고리즘이 작동하지 않아 부득이하게 Index_desc와 rownum 조건을 사용한 경우다.  sql<br>select ...<br> ,(select substr(max(변경일자 \|\| 연체금액), 9) from ... )<br>from 고객 a where ......<br> |
다행히 위에서는 고객별 연체 이력 테이블로부터 연체금액 하나만 읽기 때문에 스칼라 서브쿼리로 변경하기가 수월했다. 만약 두 개 이상 컬럼을 읽어야 한다면 아래와 같이 스칼라 서브쿼리 내에서 필요한 컬럼 문자열을 연결하고, 메인 쿼리에서 Substr 함수로 잘라쓰는 방법을 사용해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
select 고객명, 거주지역, 주소, 연락처,
to_number(substr(연체, 3)) as 연체금액,
to_number(substr(연체, 2, 2)) as 연체개월수
from
(select a.고객명, a.거주지역, a.주소, a.연락처,
(select /*+index_desc(b고객별연체이력_idx01) */ 1pad(연체개월수, 2) | 연체금액
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일
and rownum <= 1) as 연체
from 고객a
where 가입회사 = 'C70');
이력 테이블에서 읽어야 할 컬럼 개수가 많다면 일일이 문자열로 연결하는 작업은 여간 번거롭지 않다. 그때는 아래와 같이 스칼라 서브쿼리에서 rowid 값을만족하고 고객별 연체 이력을 한번 더 조인하는 방법을 생각해볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
select /*+orderedusenl(6)_rowid(b)*/ a.*, b.연체금액, b.연체개월수
from
(
select a.고객명, a.거주지역, a.주소, a.연락처,
(
select /*+Indexdesc(b 고객별연체이력_1dx01) */ rowid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum<= 1
) rid
from 고객 a
where 가입회사= 'C701'
) a, 고객별연체이력 b
where b.rowid = a.rid
스칼라 서브쿼리를 이용하지 않고 아래와 같이 SQL을 구사해도 같은 방식으로 처리된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
select /*+orderedusenl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from
고객 a, 고객별연체이력 b
where
a.가입회사 = 'C70'
and
b.rowid = (
select /*+index(b 고객별연체이력_1dx01) */ rowid
from 고객별연체이력 c
where c.고객번호= a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum<= 1
)
정해진 시점을 기준으로 조회
앞서는 가입 회사가 ‘C70’에 속하는 고객 수가 10명뿐이었다. 그러나 가입 회사 별 고객 수가 많아지면서 서브쿼리 수행 횟수가 늘어나고 Random I/O 부하도 심해질 것이다. 심지어 가입 회사 조건절 없이 모든 고객을 대상으로 이력을 조회한다면?
하지만 앞서 본 쿼리들은 고객 테이블로부터 읽히는 미지의 시점(서비스 만료일)을 기준으로 이력을 조회하는 경우이기 때문에 위와 같이 Random 액세스 위주의 서브쿼리를 쓸 수밖에 없다. 4장에서 설명하는 서브쿼리 Unnesting으로 유도하더라도 그다지 효과적인 실행 계획이 만들어지지 않는다.
하지만 정해진 시점을 기준으로 조회하는 경우라면 서브쿼리를 쓰지 않음으로써 Random 액세스 부하를 줄일 방법들이 몇 가지 생기는데, 간단하게 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
select /*+ full (a) full (b) full (c) use hash (a b c) no merge (b) */
a.고객명, a.거주지역, a.주소, a.연락처, c.연체금액, c.연체개월수
from
고객a,
(
select 고객번호, max(변경일자) 변경일자
from 고객별연체이력
where 변경일자 <= to_char(sysdate,'yyyy-mm-dd')
group by 고객번호
) b, 고객별연체이력 c
where b.고객번호 = a.고객번호
and c.고객번호 = b.고객번호
and c.변경일자 = b.변경일자
가장 단순하게 작성된 위 쿼리는 고객별 연체 이력 테이블을 두 번 Full Scan하는 비효율이 있으므로 아래와 같이 바꿀 수 있다.
1
2
3
4
5
6
7
8
9
select a.고객명, a.거주지역, a.주소, a.연락처,
to_number(Substr(연체, 11)) 연체금액,
to_number(substr(연체,9,2)) 연체개월수
from 고객a,
(select 고객번호, max(변경일자)||lpad(연체개월수,2)||'|'||연체금액 연체
from 고객별연체이력
where 변경일자 <= to_char(sysdate,'yyyymmdd')
group by 고객번호) b
where b.고객번호 = a.고객번호
이력 테이블에서 읽어야 할 컬럼 개수가 많다면 위와 같이 일일이 문자열로 연결하는 작업은 여간 번거롭지 않다. 그 때는 아래와 같이 분석 함수를 이용하는 것이 편하고, 수행 속도 면에서도 전혀 불리하지 않다(5장 6절 3항에서 설명할 pushed rank 메커니즘이 작동하기 때문).
1
2
3
4
5
6
7
8
9
10
11
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from
고객a
,(select 고객번호, 연체금액, 연체개월수, 변경일자,
row_number() over (partition by 고객번호 order by 변경일자 desc) rn
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyy-mm-dd')) b
where
b.고객번호 = a.고객번호
and
b.rn = 1
참고로, 아래와 같이 max 함수를 이용할 수도 있지만 방금 처럼 row_number를 이용하는 것이 더 효과적인데, 자세한 원리는 5장 6절에서 설명한다.
1
2
3
4
5
6
7
8
9
10
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from
고객a
, (select 고객번호, 연체금액, 연체개월수, 변경일자,
max(변경일자) over (partition by 고객번호) max_dt
from
고객별연체이력
where 변경일자 < to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.변경일자 = b.max_dt
(8) 선분 이력 조인
선분 이력을 조회하는 기본 패턴과 인덱스 스캔 효율을 높이는 방안에 대해서는 1장에서 자세히 설명하였다. 여기서는 조인을 통해 선분 이력을 조회하는 방법을 정리하고, 계속해서 선분 이력 조인 튜닝 방안을 다음 항에서 설명한다.
1장에서 설명한 선분 이력 조회를 상기해보면 그다지 어렵지 않다고 느낄 것이다. 그럼에도 개발 현장에 가보면 선분 이력에 대한 어려움을 호소하는 개발자들을 자주 만난다. 쿼리가 복잡하다고 말하는데, 처음 접할 때 이해하기가 다소 어려울 뿐 쿼리 자체는 오히려 간단하다. (데이터 가공은 자못 어렵다.)
과거/현재/미래의 임의 시점 조회
개발 팀에서 쿼리를 복잡하게 생각하는 경우는, 아마 2개 이상의 선분 이력을 함께 조인할 때인 것 같다.
그림 2-36과 같이 고객 등급과 전화번호 변경 이력을 관리하는 두 선분 이력 테이블이 있다고 하자.
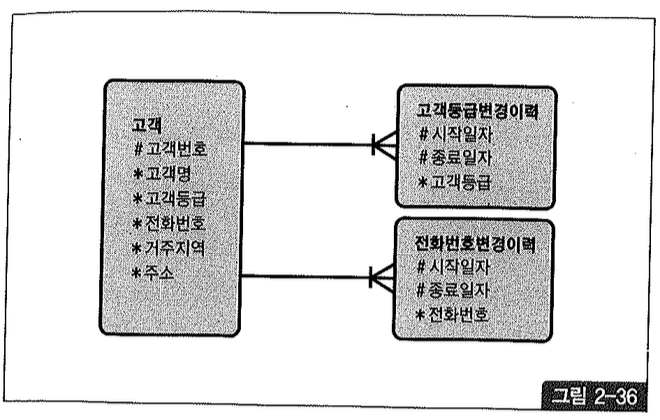
123번 고객의 등급과 전화번호 변경 이력 레코드를 수평선상에 펼쳐 시계열적으로 표현했을 때 그림 2-37과 같다면, 위 쿼리 결과로서 고객 등급은 B, 고객 전화번호는 987-6543으로 조회될 것이다.
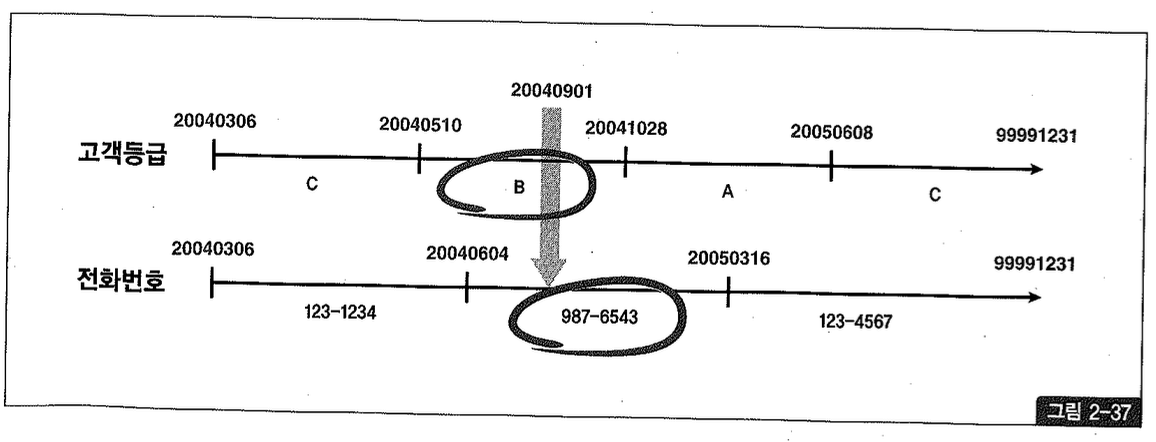
현재 시점 조회
위 쿼리를 이용해 과거, 현재, 미래 어느 시점이든 조회할 수 있지만, 만약 미래 시점 데이터를 미리 입력하는 예약 기능(1장에서 설명하였으므로 참조하기 바람)이 없다면 “현재 시점(즉, 현재 유효한 시점)” 조회는 아래와 같이 단순한 조건으로만 들어주는 것이 효과적이다. 범위 검색 조건이 비효율을 일으키는 원인은 1장에서 자세히 설명하였다.
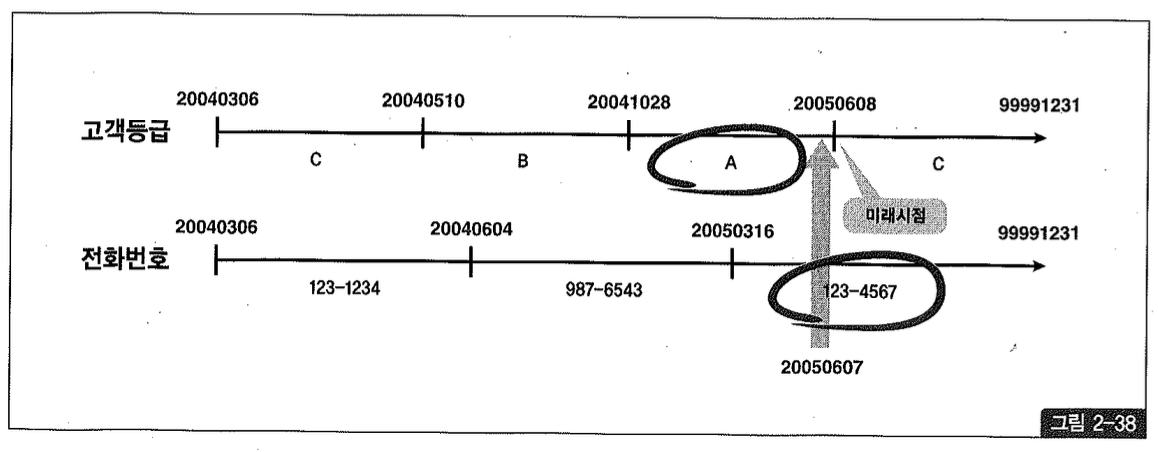
현재가 2005년 6월 7일인데 그림 2-38처럼 미래 시점인 6월 8일 데이터를 미리 입력해두는 기능이 있다면, 현재 시점을 조회할 때 아래와 같이 sysdate와 between을 사용해야만 한다.
Between 조인
지금까지는 선분 이력 조건이 상수였다. 즉, 조회 시점이 정해져 있었다. 그림 2-39에서만약 우선(일별 종목 거래 및 시세)과 같은 일별 거래 테이블로부터 읽히는 미지의 거래 일자 시점으로 선분 이력(종목 이력)을 조회할 때는 어떻게 해야할까? 이때는 between 조인을 이용하면 된다.
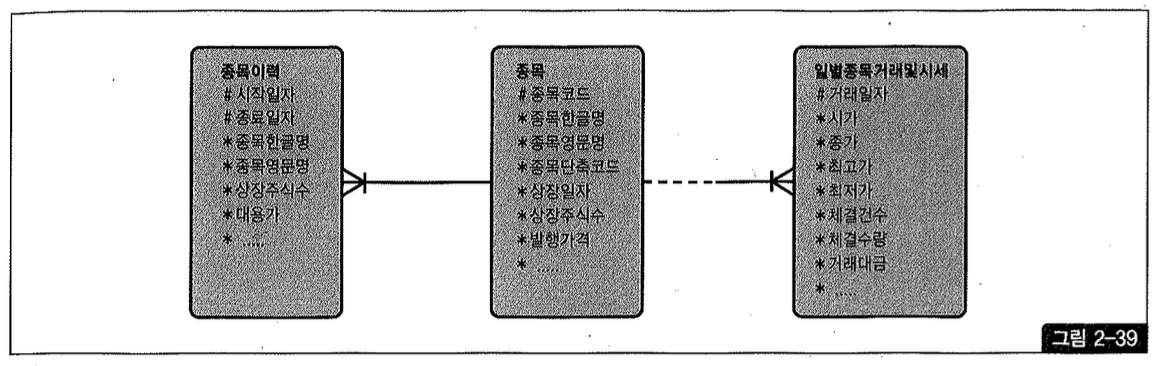
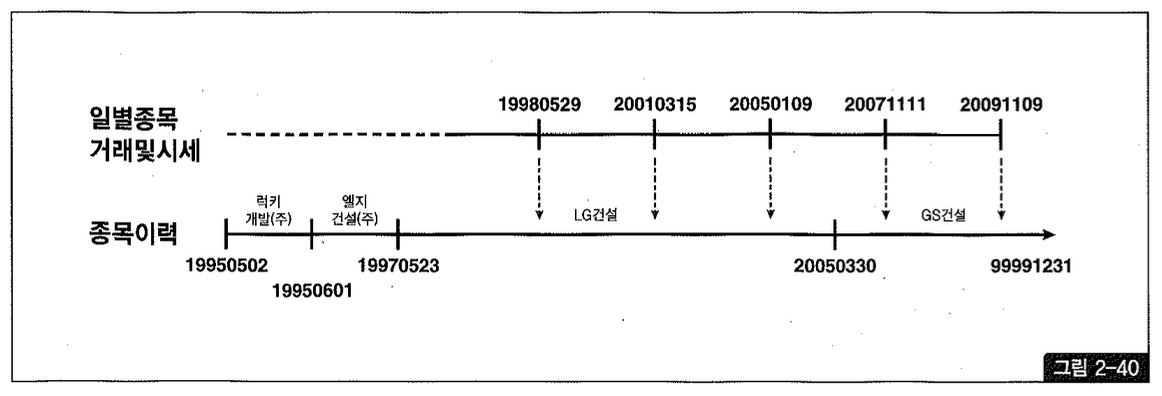
이런 식으로 조회하면 현재(=최종) 시점의 종목명을 가져오는 것이 아니라 그림 2-40에서 보는 것처럼 거래가 일어난 바로 시점의 종목명을 읽게 된다.
거래 시점이 아니라 현재(=최종) 시점의 종목명과 상장 주식 수를 출력하려면 between 조인 대신 아래와 같이 상수 조건으로 입력해야 한다 (그림 2-41 참조).
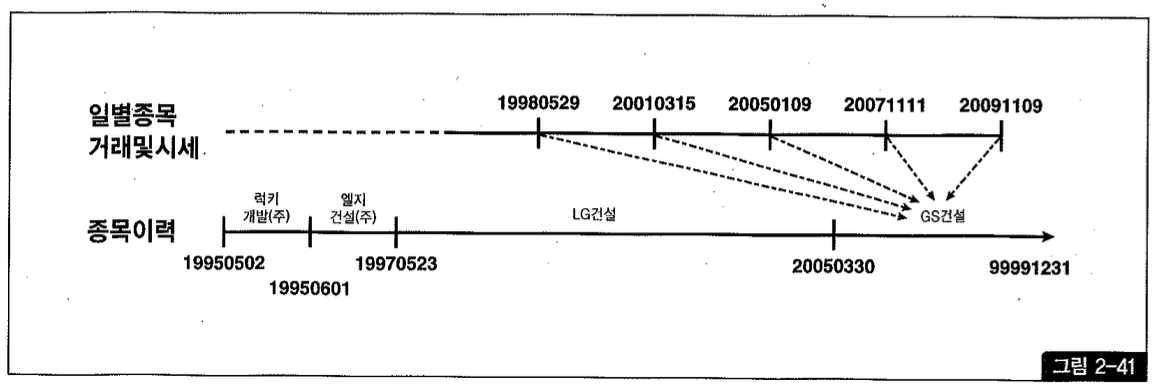
물론 방금 쿼리는 종목 테이블을 종목 이력과 통합해 하나로 설계했을 때 사용하는 방식이다. 그림 2-39처럼 종목과 종목 이력을 따로 설계했을 때는 최종 시점을 위해 종목 테이블과 조인하면 된다.
(9) 선분 이력 조인 튜닝
선분 이력 테이블과 조인하는 방법에 대해 살펴보았다. 지금부터는 선분 이력과 조인할 때 발생하는 성능 이슈, 그리고 이를 해결할 튜닝 방안에 대해 살펴보고자 한다. 단일 선분 이력 테이블 조회 및 튜닝 방안에 대해서는 1장에서 다루었는데, 이를 건너뛰고 2장부터 읽기 시작한 독자라면 해당 부분을 먼저 학습하기 바란다.
정해진 시점을 기준으로 선분 이력과 단순 조인할 때
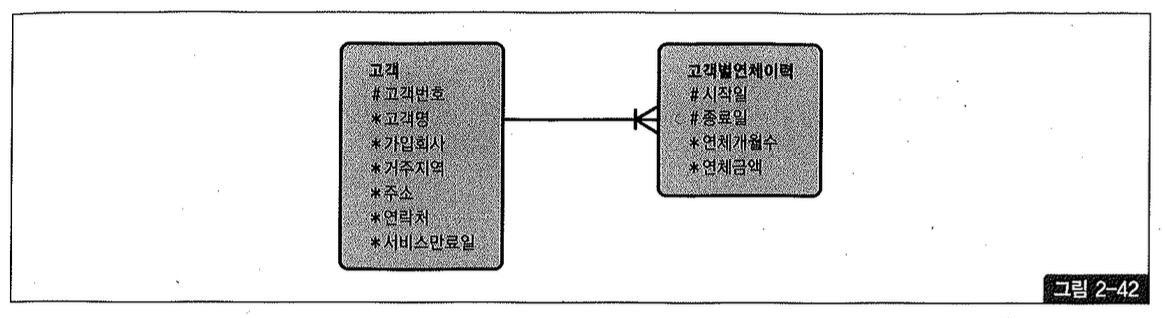
그림 2-42와 같은 모델 하에서 아래처럼 특정 회사(예, 가입회사 = ‘C70’)를 통해 가입한 모든 고객의 연체금액을 조회하는 경우를 생각해보자.
특정 고객 이력만 조회한다면 1장에서 본 것처럼 rownum <= 1 조건을 적용해 인덱스를 한 건만 스캔하고 멈추도록 할 수 있지만 위와 같이 다수의 고객을 조회할 때는 그럴 수가 없다. 따라서 위 쿼리를 수행해 보면, ‘C70 회사를 통해 가입한 모든 고객에 대해 시작일이 2005년 1월 31일보다 작거나 같은 이력을 모두 스캔하거나(인덱스 구성상 시작일이 종료일보다 선행 컬럼일 때), 종료일이 2005년 1월 31일보다 크거나 같은 이력을 모두 스캔(종료일이 시작일보다 선행 컬럼일 때)하게 된다.
먼저 인덱스를 [고객번호 + 종료일 + 시작일] 순으로 구성해 보자.
1
create index 고객별연체이력_idx01 on 고객별연체이력(고객번호, 종료일, 시작일);
고객 테이블에 입력되어 있는 단 10명의 연체 이력을 조회하는데, 고객별연체이력_idx01 인덱스 스캔 단계(맨 하단)에서만 4,630개의 블록 I/O가 발생하였다. 고객마다 종료일이 2005년 1월 31일보다 크거나 같은 이력을 모두 스캔한 것이다.
인덱스를 아래와 같이 바꿔주면 시작일이 2005년 1월 31일보다 작거나 같은 이력을 찾을 것이고, 여기에 해당하는 데이터가 매우 소량이므로 인덱스 스캔량이 획기적으로 줄 것이다.
1
create index 고객별연체이력_IDX01 on 고객별연체이력(고객번호, 시작일, 종료일);
예상했던 대로 고객별연체이력_idx01 인덱스를 스캔하는 단계에서 블록 I/O가 24개만 발생하였다.
C70 회사를 통해 가입한 고객만 조회하는 것이 아니라 만약 아래와 같이 전체 고객을 대상으로 조회할 때는 Random 액세스 위주의 NL 조인보다 해시 조인을 이용하는 것이 유리하다. (예제 데이터에는 모든 고객의 가입회사가 ‘C70’이므로 성능 차이가 없겠지만.)
해시 조인을 이용하면 전체 이력 레코드를 Full Scan하는 비용은 있을지언정 해시 조인과 정에서의 비효율은 없다. 고객별연체이력을 해시 테이블로 빌드(build)하더라도 각 고객별로 한 건의 이력 레코드만 해시 테이블에 담기 때문이며, 뒤에서 보겠지만 between 조인일 때는 전구간 이력 레코드를 해시 테이블로 빌드함으로 인해 엄청난 비효율을 수반하기도 한다.
Between 조인 튜닝 - 조회 대상이 많지 않을 때
앞에서는 정해진 시점을 기준으로 선분 이력과 단순 조인할 때의 튜닝 방안을 살펴보았다. 문제는, 아래와 같이 미지의 값(고객 테이블에서 실시간으로 읽히는 값)으로 between 조인하는 경우다.
이런 상태에서 조금 전 보았던 between 조인을 수행한다면, 고객에서 읽힌 값이 25520801일 때는 거의 처음부터 끝까지 스캔하고서야 조건을 만족하는 이력 데이터를 찾을 수 있다. 현재의 인덱스 구성상 시작일자가 종료일자보다 선행 컬럼이기 때문이다. 반대로, 20591005일 때는 스캔량이 그리 많지 않을 것이다.
10명의 연체 이력을 조회하는데 고객별연체이력_idx01 인덱스 스캔 단계에서만 2,557개의 블록 I/O가 발생하였다. 인덱스를 [종료일+시작일] 순으로 바꾸더라도 나아질 것이 없다.
rownum과 index(또는 index_desc) 힌트를 적절히 사용할 수 있다면 인덱스 구성이 어떻든지 간에 항상 필요한 한건만 스캔하도록 할 수 있는데, 위 형태의 일반 조인문으로는 그럴 수 없다는 것이 문제다.
이럴 때는 조인문을 스칼라 서브쿼리나 중첩된 서브쿼리(nested subquery) 형태로 바꾼다면 각 고객별로 단 하나의 이력만 읽도록 rownum < = 1 조건을 추가해줄 수 있다. 다행히 위에서는 고객별연체이력 테이블로부터 연체금액 하나만 읽기 때문에 아래와 같이 스칼라 서브쿼리로 간단히 변경할 수 있다.
위 Row Source Operation에서 보듯, 쿼리를 바꾸고 rownum <= 1 조건을 사용했더니 고객별연체이력_idx01 인덱스 스캔 단계에서 블록 I/O가 30 개만 발생하였다.
만약 연체금액과 연체개월수, 두 컬럼을 읽고자 한다면 어떻게 해야 할까? 점 이력 조회에서 이미 설명한 것처럼 컬럼들을 문자열로 연결하고서 바깥쪽 액세스 쿼리에서 substr 함수로 잘라쓰거나, 아래와 같이 스칼라 서브쿼리에서 rowid값만 취하고 고객별연체이력을 한 번 더 조인하는 방법을 쓸 수 있다.
이들 방법에 대한 수행 원리는 점 이력 조회에서 이미 설명했으므로 부연하지 않겠다. 여기서도 스칼라 서브쿼리 대신 아래와 같이 일반 서브쿼리로부터 읽은 rowid로 테이블을 직접 액세스하는 방법을 쓸 수 있다.
Between 조인 튜닝 - 조회 대상이 많지만 대상별 이력 레코드가 많지 않을 때
조금 전 사례는 CTO 회사를 통해 가입한 고객만 조회하는 경우였다. 즉, 조회 대상이 많지 않은 between 조인이었다. 만약 전체 고객을 대상으로 한다면 Random 액세스 위주의 NL 조인보다 아래처럼 해시 조인을 이용하는 것이 효과적이다.
1
2
3
4
5
6
select /*+ ordered use hash (b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수 from
고객 a, 고객별연체이력 b
where b.고객번호= a.고객번호
and
a.서비스만료일 between b.시작일 and b.종료일
경우에 따라서는 선분 이력을 해시 테이블로 빌드(Build)해서 조인해야할 때가 있다. 그럴 때만약 조인 대상별 이력 레코드가 꽤 많다면 해시 탐색 부하 때문에 성능이 크게 저하되는데, 이에 대한 튜닝해법은 무엇인지 고민해보자.
Between 조인 튜닝 - 대상별 이력 레코드가 많을 때
우선, 지금까지 설명한 선분 이력 조인 튜닝 방안을 요약해보면 다음과 같다.
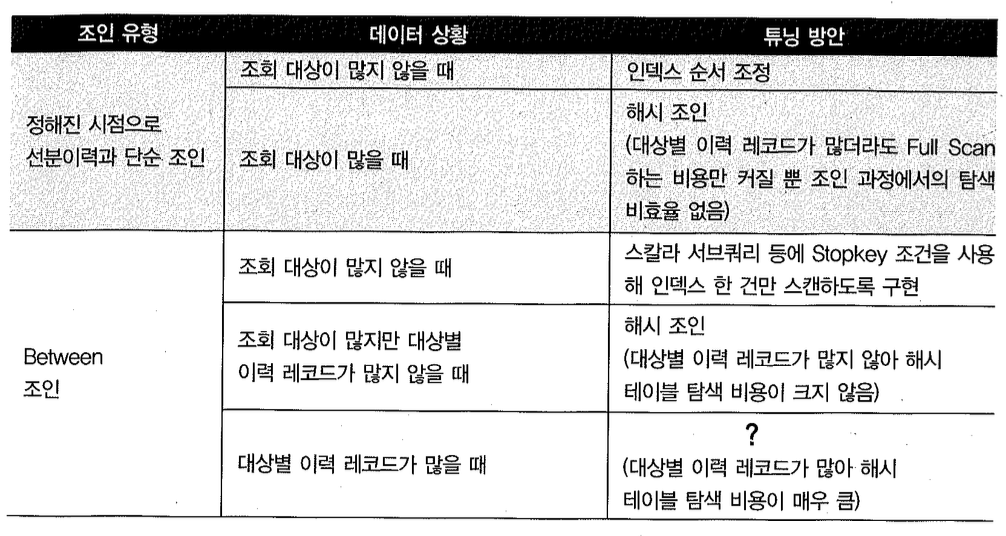
표에서 맨 아래쪽에 있는 대상별 이력 레코드가 많을 때의 between 조인이 가장 튜닝하기가 어렵다. 이럴 때 해시 테이블 탐색 비용이 큰 이유에 대해서는 3절 해시조인 중 ‘(5) BuildTnput 해시키값에 중복이 많을 때 발생하는 비효율’에서 설명하였다. 거기서 다룬 내용을 선분 이력에 대입해 요약해보면, 대량의 선분 이력을 해시조인하는데 각 해시 버킷에 많은 이력 레코드가 달리는 구조라면 매번 그것들을 스캔하면서 이력을 탐색하기 때문에 비효율이 생긴다는 것이다.
이럴 때 필자가 제안하는 첫 번째 방안은, 두 개 이상 월에 걸치는 이력이 생기지 않도록 매월 말일 시점에 강제로 이력을 끊어주는 것이다. 그러면 between 조인에 의한 스캔 범위가 한 달을 넘지 않도록 새로운 조인 조건을 추가해 줄 수 있 다. 해시 체인을 스 캔 하 는 비 효 율 을 완 전 히 없 앨 수는 없지만 최대 31개가 넘지 않도록 제한하려는 것이다.
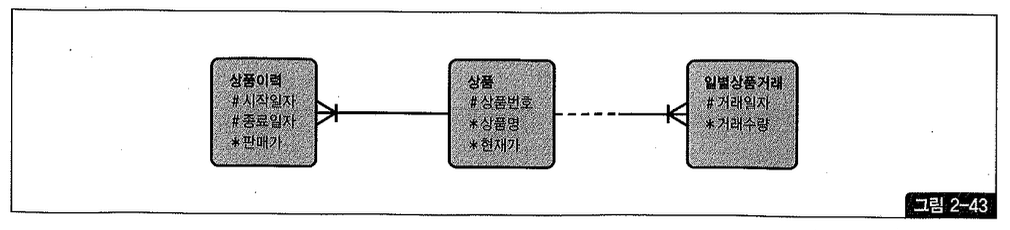
성능 비교를 위해 그림 2-43과 같은 형태로 테이블을 만들어 보자.
아래는 NL 조인 방식으로 between 조인을 수행한 결과다.
190만개 블록을 읽으면서 33초가량 소요되었다. 참고로, 디스크 I/O가 포함되면 속도가 들쭉날쭉하기 때문에 디스크 I/O가 발생하지 않도록 몇 번 반복 수행한 상태에서 위 트레이스를 수집 하였다. 따라서 실제 상황이라면 디스크 I/O 때문에 이보다 더 많은 시간이 소요될 것이다.
이번에는 stopkey 조건을 적용한 서브쿼리로부터 rowid를 읽어 직접 이력 테이블을 액세스하는 방식으로 수행해보자.
146만개 블록을 읽으면서 20초가량 소요되었다. 하지만 이것은 SQL 트레이스 때문에 그런 것이고, SQL 트레이스를 걸지 않고 그냥 수행해보면 불과 2.5초만에 결과가 나온다. 아래는 Autotrace만 걸고 수행해본 것인데, TO 횟수까지 똑같은데 수행 속도는 천양지차(20초 -> 2.5초)다.
SQL 트레이스를 걸면 쿼리가 비정상적으로 오래 걸릴 때가 때때로 있다고 한다. 대개는 버그에 의한 것 이다. SQL 트레이스를 걸지 않은 정상적인 상태가 기준이어야 하므로 33초에서 2.5초로 수행 속도가 감소했다고 평가할 수 있다. (앞에서 between 조인문으로 쿼리한 경우는 SQL 트레이스를 걸지 않더라도 거의 같은 속도를 보였다.)
조금 전 쿼리가 2.5초만에 수행될 수 있었던 것은 디스크 I/O가 전혀 발생하지 않도록 한 상태에서 측정했기 때문이다. 실제 운영 환경에서 디스크 I/O가 수반한 Random 액세스 방식으로 146만개 블록을 읽는다면 수십 초에서 수분이 걸릴 수 있다.
이처럼 대량 데이터를 조인할 때 NL 조인은 비효율적이므로 이번에는 해시조인으로 바꿔서 수행해보자.
해시조인을 이용했더니 52초나 걸렸다. 인덱스 기반의 between 조인할 때(3초)보다 더 오래 걸린 것이다. 이유는, 각 상품별 이력이 평균 913건이나 되기 때문이다. 즉, 해시테이블 탐색 비용이 매우 높은 것이 원인이다.
앞서 제시한 방안에 따라 두 개 이상 월에 걸치는 이력 레코드가 없도록 ‘상품이력?’ 테이블을 만들어 보자.
선분 형태의 이력이지만 한 달 범위를 넘지 않도록 했기 때문에 아래와 같이 조인문을 하나 더 추가해 줄 수 있다. 상품번호 외에 월 조건까지 해시 키(ey) 값으로 사용하게 되었으므로 해시 버킷에서 스캔해야 할 양은 최대 31개를 넘지 않는다.
상품 이력 2 테이블에서 출력된 건 수는 앞에서 보다 9,000 - 100,325 - 91,325) 건 더 많아 졌지만 성능은 비교할 수 없이 빨라졌다(1.34 초).
두 번째 방안은, 두 개 이상 월에 걸치는 이력이 없도록 쿼리 시점에 선분 이력을 변환해주는 것이다. 그런 다음 조인하는 방법은 앞에서와 같고, 마찬가지로 해시 체인을 스캔하는 양은 최대 31 개로 제한될 것이다.
미리 만들어 둔 ‘상품 이력 2 테이블을 이용할 때 보다는 느리지만 그냥 해시조인 할 때 의 52초 보다는 훨씬 빨라졌다.
이 방식을 사용하면 ‘일별상품거래’ 와 조인할 때는 빠르지만, ‘월도’ 테이블과 조인하는 과정에서 오히려 병목이 생길 수 있다.
Between 조인 튜닝 요약
지금까지 본 테스트 결과를 통해, 대상별 이력 레코드가 많을 때의 between 조인은 좋은 성능을 내기가 쉽지 않음을 알 수 있다. 많은 이력을 가진 마스터 데이터와 넓은 검색 구간의 거래 데이터를 조회하는 경우가 여기에 해당하며, 이것은 정보 계 시스템에서 자주 사용되는 쿼리 패턴이기도 하다.
위 경우에 해당하는 마스터 테이블 이력이라면 월 말 시점마다 선분을 끊어주는 것을 고려하기 바란다. 쿼리 수행 시점에 실시간으로 선분을 끊는 방법도 있지만 복제되는 양에 따라 만족할 만한 성능이 나오지 않을 수 있고, 무엇보다 쿼리가 복잡해진다는 게 단점이다.
마스터 데이터 건수가 적으면서 변경이 잦은 경우라면 매일 전체 대상 집합을 새로 저장하는 이력 관리 방식(스냅샷 형태)도 고려해볼 수 있다. 변경이 발생하지 않은 대상 집합도 매일 새로 저장하기 때문에 데이터량은 더 많아지겠지만 대용량 조회 시 검색 효율은 오히려 좋아진다. 물론 마스터 데이터 건수가 아주 많을 때는(수백만 개의 상품, 수천만 명의 고객 등) 고려의 대상이 못된다.
위와 같은 성능 이슈가 예상되면 차라리 점 이력으로 설계하는 것이 낫지 않느냐고 반문할지 모르지만, 조회 성능 측면에선 선분 이력보다 나을 게 없다. 변경 일자만 관리하는 점 이력에 종료 일자를 하나 더 갖도록 한 것이 선분 이력이라고 이해한다면 그 이유를 쉽게 설명할 수 있다.
(10) 조인에 실패한 레코드 읽기
조인에 실패했을 때, 정해진 특정 레코드에서 가져온 값으로 보여주고 싶을 때는 어떻게 쿼리해야 할까?
cdr을 기준으로 Outer 조인하면 통화 내역은 모두 출력되겠지만 기타 지역 통화 내역에 대한 요금 정보가 Null로 출력 된 다.
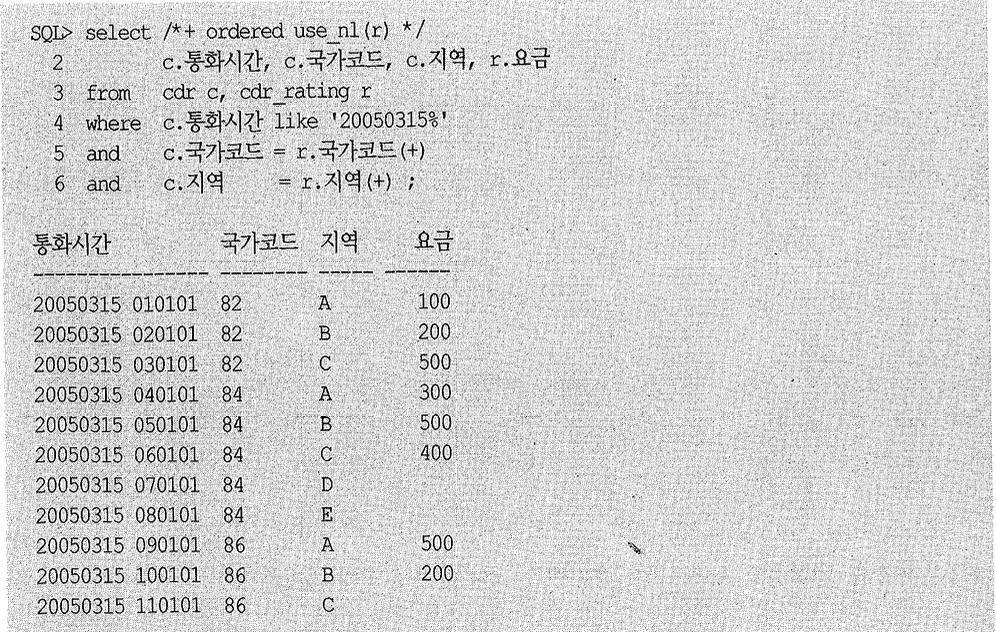

어떻게 쿼리해야 조인에 실패했을 때 지역이 공백(‘ ‘)인 요금 정보를 가져올 수 있을까? 아래와 같이 쿼리하면 된다.
![]()