<오라클 성능 고도화 원리와 해법2> Ch03-01 옵티마이저
오라클 성능 고도화 원리와 해법2 - Ch03 옵티마이저 원리
오라클 성능 고도화 원리와 해법2 - Ch03-01 옵티마이저
옵티마이저에 대한 기본 개념은 이미 1권 4장에서 설명했다. 1권에서는 주로 라이브러리 캐시 최적화 관점에서 옵티마이저를 다뤘지만, 이번 장에서는 옵티마이저를 중심 주제로 다루고 있다.
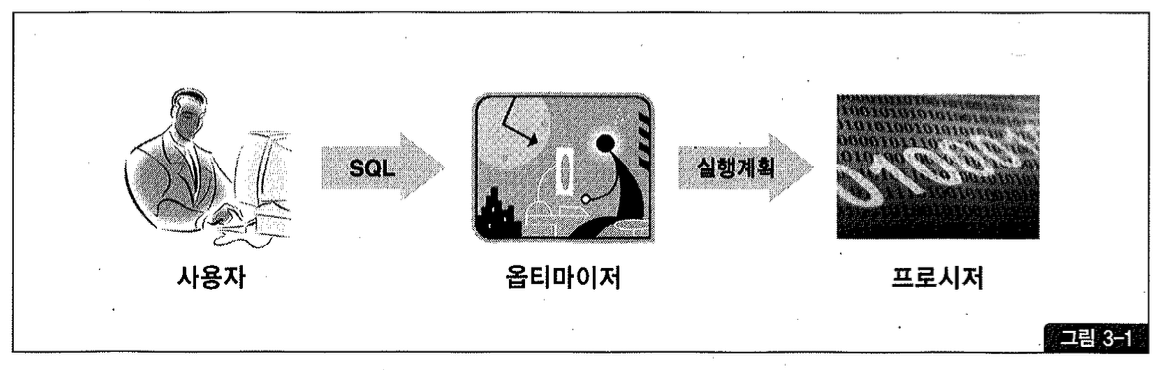
1권에서 설명한 내용을 상기해보면, 옵티마이저는 사용자가 요청한 SQL을 가장 효율적이고 빠르게 수행할 수 있는 최적(최저 비용)의 처리 경로를 선택해주는 DBMS의 핵심 엔진이다. 구조화된 질의 언어(SQL)로 사용자가 원하는 결과 집합을 정의하면 이를 얻기 위한 처리 절차(프로시저는 DBMS에 내장된 옵티마이저가 자동으로 생성해준다.
옵티마이저에는 크게 두 가지가 있다.
• 규칙 기반 옵티마이저(Rule-Based Optimizer, 이하 RBO) • 비용 기반 옵티마이저(Cost-Based Optimizer, 이하 CBO)
역사가 오래된 오라클은 RBO에서 출발했지만 다른 상용 RDBMS는 탄생 초기부터 CBO를 채택했다. 그리고 오라클도 10g부터 RBO에 대한 지원을 중단한다고 1) 공식적으로 선언했으므로 더는 둘 간의 비교 논쟁이 불필요하다. 하지만 흘러온 역사를 이해하는 것은 현재에 대한 이해를 높이는 데 도움이 되므로 RBO에 대한 개념부터 간단히 살펴보자.
- 지원을 중단한다는 의미는 더 이상 기능 개선이 없고 문제가 생겨도 기술 지원을 하지 않겠다는 뜻이다. 10g에서도 여전히 rule 힌트를 사용하면 RBO 모드 실행 계획을 확인할 수 있다.
(2) 규칙 기반 옵티마이저
규칙 기반 옵티마이저(Rule-Based Optimizer)는 다른 말로 ‘휴리스틱(Heuristic) 옵티마이저’라고도 불린다. 미리 정해 놓은 우선 순위에 따라 액세스 경로(Access Path)를 평가하고 실행 계획을 선택한다. 아래표는 RBO가 사용하는 규칙(액세스 경로 별 우선 순위)인데, 인덱스 구조, 연산자, 조건 형태가 순위를 결정짓는 주요 인자임을 알 수 있다.
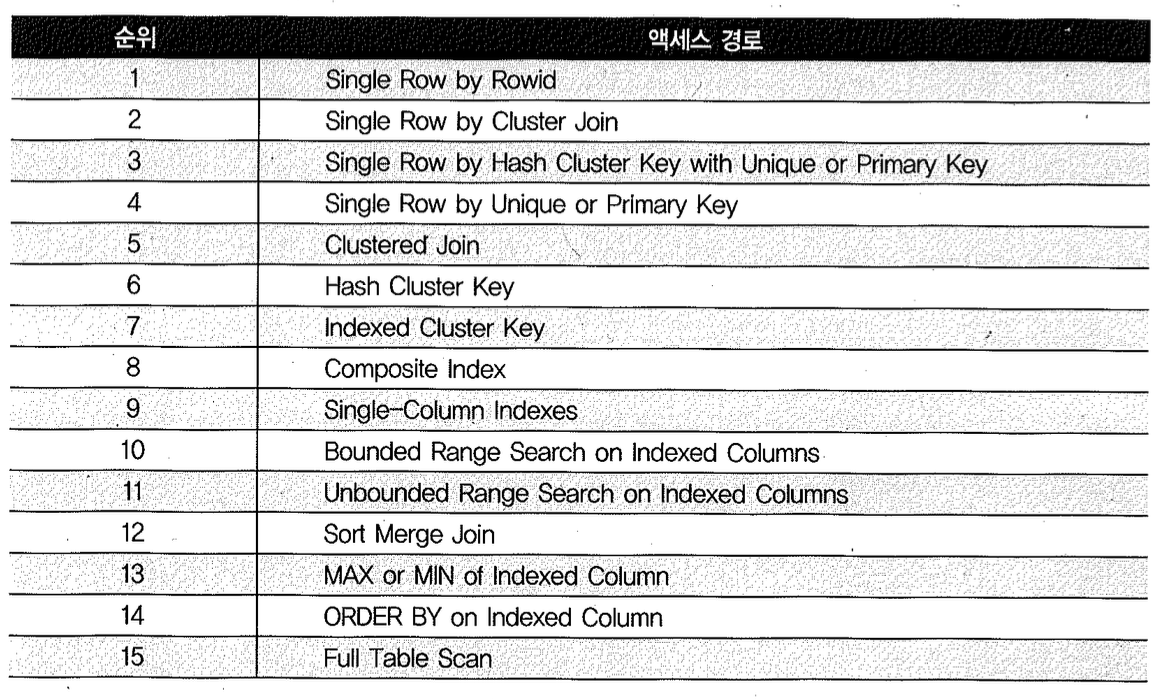
중소형 데이터베이스 시스템이라면 RBO 규칙이 어느 정도 보편 타당성을 갖는다. 하지만 데이터량, 값의 수(number of distinct values), 컬럼 값 분포, 인덱스 높이, 클러스터링 패턴 같은 데이터 특성을 고려하지 않기 때문에 RBO는 대용량 데이터를 처리하는 데에 합리적이지 못할 때가 많다. 예를 들어, 조건 컬럼에 인덱스가 있으면 무조건 인덱스를 사용한다. 항상 인덱스를 신뢰하며, Full Table Scan과의 손익을 따지지 않는다. (인덱스를 경유하면서 액세스할 데이터량이 일정 수준 이상이면 오히려 Full Table Scan이 유리하다는 것은 일반적인 상식이지만 RBO는 그런 사실을 외면한다.)
또 다른 예로, 아래와 같은 문장을 수행할 때도 empno 컬럼에 인덱스가 있으면 무조건 그 인덱스를 이용해 sort order by 연산을 대체한다. 부분 범위 처리가 불가능한 상황이라면 Full Table Scan 하고 나서 정렬하는 편이 나은데도 RBO 우선 순위로는 인덱스 컬럼에 의한 order by(14위)가 Full Table Scan (15위) 보다 한 단계 높아서 그런 선택을 한다.
1
select /*+ rule */ * from emp order by empno
RBO는 이처럼 예측 가능하고 일관성 있는 실행 계획을 수립하며 사용자가 원하는 처리 경로로 유도하기가 쉽다. 그에 반해 CBO는 같은 SQL이더라도 데이터 특성에 따라 실행 계획이 달라지고 복잡한 비용 원리를 내포하고 있어 이를 정확히 이해하지 못한다면 제어하기가 쉽지 않다. 이 때문에 운영자 입장에서 불안한 측면이 있고 이것을 이유로 아직도 RBO를 옹호하는 분들을 종종 만나는데, 지금 같은 초대용량 데이터베이스 환경에서는 더는 RBO가 대안이 될 수 없다.
다른 RDBMS와 마찬가지로 오라클도 CBO만 지원하게 되었으므로 자꾸 뒤를 돌아보는 것은 소모적이다. 이제는 CBO에 대한 더 깊이 있는 연구를 통해 그 특성을 파악하고, 데이터와 시스템 특성에 맞는 통계 정보 수집 정책을 수립함으로써 옵티마이저가 최적의 결정을 할 수 있도록 돕는 쪽에 역량을 집중하는 것이 바람직하다. 옵티마이저 힌트 사용에 관한 찬반 논쟁과 훈동하지 말기를 바란다. 이에 대한 논쟁은 아직도 뜨겁다.
(3) 비용 기반 옵티마이저
비용 기반 옵티마이저는 말 그대로 비용을 기반으로 최적화를 수행한다. 여기서 ‘비용(Cost)’이란, 쿼리를 수행하는데 소요되는 일량 또는 시간을 뜻한다. 전통적인 I/O 비용 모델에서는 I/O 요청(cal) 횟수만으로 비용을 평가했지만, 최근 도입된 CPU 비용 모델에서는 CPU 연산 비용까지 감안한다. 그리고 수행 일량을 상대적인 시간 개념으로 환산해 비용을 평가한다.
CBO가 실행 계획을 수립할 때 판단 기준이 되는 비용은 어디까지나 예상치다. 미리 구해놓은 테이블과 인덱스에 대한 여러 통계 정보를 기초로 각 오퍼레이션 단계별 예상 비용을 산정하고, 이를 합산한 총 비용이 가장 낮은 실행 계획 하나를 선택한다. 비용을 산정할 때 사용되는 오브젝트 통계 항목에는 레코드 개수, 블록 개수, 평균 행 길이, 컬럼 값의 수, 컬럼 값 분포, 인덱스 높이, 클러스터링 팩터 같은 것들이 있다.
오브젝트 통계 뿐만 아니라 최근에는 하드웨어적 특성을 반영한 시스템 통계 정보(CPU 속도, 디스크 I/O 속도 등)까지 이용하는데, 자세한 내용은 4절에서 설명한다.
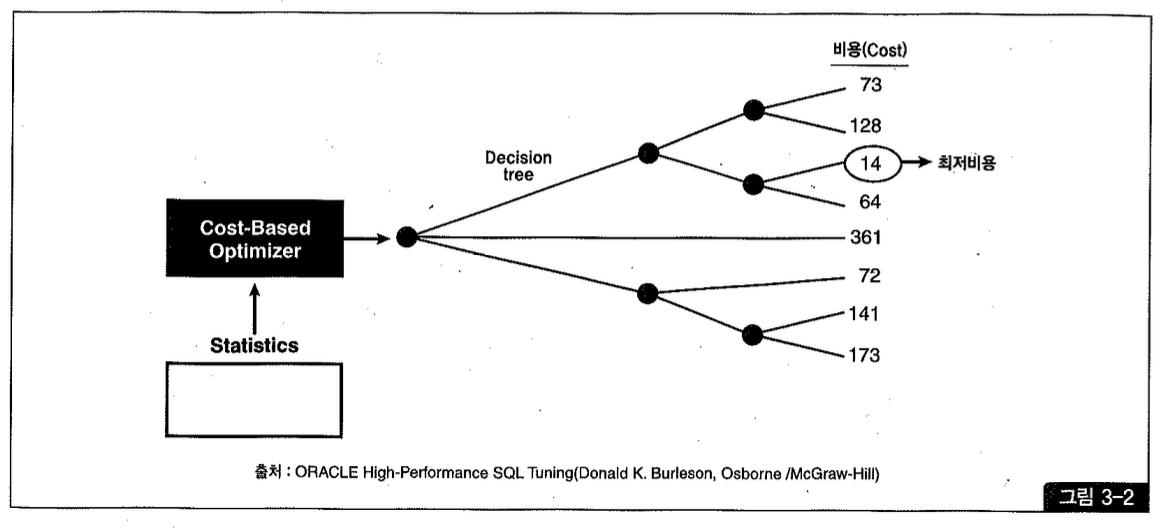
옵티마이저의 최적화 수행 단계를 요약하면 다음과 같다(그림 3-2 참조)
- 사용자가 던진 쿼리 수행을 위해, 후보군이 될 만한 실행 계획을 찾는다.
- 데이터 딕셔너리(Data Dictionary)에 미리 수집해놓은 오브젝트 통계 및 시스템 통계 정보를 이용해 각 실행 계획의 예상 비용을 산정한다.
- 각 실행 계획의 비용을 비교해서 최저 비용을 갖는 하나를 선택한다.
| 동적 샘플링(Dynamic Sampling) |
|---|
| 동적 샘플링(Dynamic Sampling)은 쿼리를 최적화할 때 미리 구해놓은 통계 정보를 이용한다고 했는데, 만약 테이블과 인덱스에 대한 통계 정보가 없거나 너무 오래돼 신뢰할 수 없을 때 옵티마이저가 동적으로 샘플링을 수행하도록 할 수 있다. optimizer dynamic sampling 파라미터로 동적 샘플링 레벨을 조정하며, 9i에서 기본 레벨이 1이던 것이 10g에서 2로 상향 조정되었다. 따라서 10g에서는 쿼리 최적화 시 통계 정보 없는 테이블을 발견하면 무조건 동적 샘플링을 수행한다. 레벨을 0으로 설정해 동적 샘플링이 일어나지 않게 할 수 있으며, 9i 기본값인 1로 설정할 때는 아래 조건을 모두 만족할 때만 동적 샘플링이 일어난다. (1) 통계 정보가 수집되지 않은 테이블이 적어도 하나 이상 있고, (2) 그 테이블이 다른 테이블과 조인되거나 서브쿼리 또는 Non-mergeable View(4장에서 자세히 다름)에 포함되고, (3) 그 테이블에 인덱스가 하나도 없고, (4) 그 테이블에 할당된 블록 수가 32개(동적 샘플링을 위한 표본 블록 수의 기본값보다 많을 때) 레벨 설정은 최대 10까지 가능하다. 레벨이 높을수록 옵티마이저는 더 적극적인 동적 샘플링을 수행하며 샘플링에 사용되는 표본 블록 개수도 증가한다. 동적 샘플링으로 얻은 통계 정보는 데이터 딕셔너리에 영구 저장되지 않는다. 통계 정보가 올바르지 않은 테이블을 참조하는 쿼리는 “하드 파싱할 때마다” 동적 샘플링을 위한 Recursive SQL이 추가로 수행되므로 성능이 좋을 리 없다. 따라서 DB 관리자는 이런 현상이 발생하지 않도록 통계 정보를 관리해 주어야 한다. 참고로, 동적 샘플링이 일어날 때면 SQL 트레이스에서 아래와 같은 주석을 포함한 Recursive SQL을 발견할 수 있다. SELECT /* OPT_DYN_SAMP */ ••• FROM ••• |
그림 3-3은 CBO를 기준으로 SQL 처리 절차를 요약한 것이다.
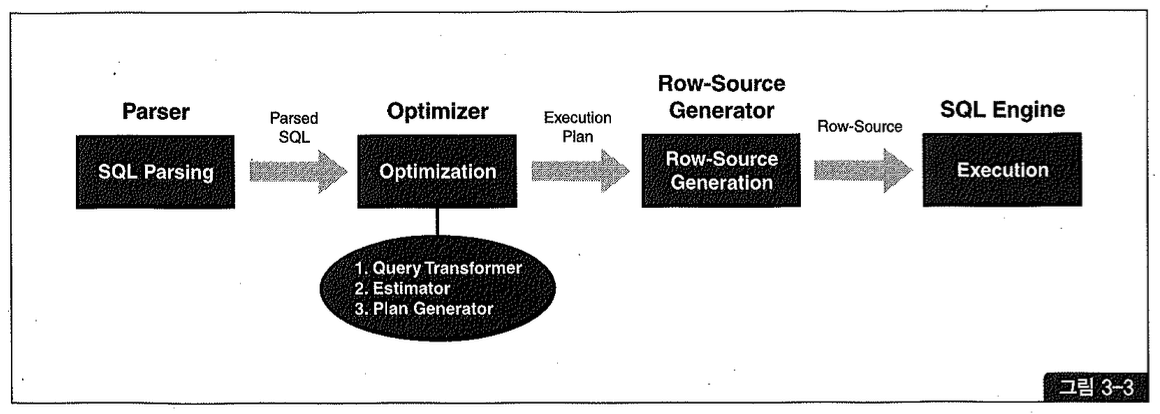
SQL 파서(Parser)와 Row-Source Generator의 역할에 대해서는 1권에서 설명하였으므로 여기서는 생략하기로 하겠다. 옵티마이저를 구성하는 세 서브 엔진의 역할에 대해서도 이미 설명했지만 잠시 상기해보기로 하자.
- Query Transformer는 사용자가 던진 SQL을 그대로 최적화하는 것이 아니라 우선 최적화하기 쉬운 형태로 변환을 시도한다. 물론 쿼리 변환 전후 결과가 동일함이 보장될 때만 그렇게 한다.
- Estimator는 쿼리 오퍼레이션 각 단계의 선택도(Selectivity), 카디널리티(Cardinality), 비용(Cost)을 계산하고, 궁극적으로는 실행 계획 전체에 대한 총 비용을 계산해낸다. 각 단계를 수행하는 데 필요한 I/O, CPU, 메모리 사용량 등을 예측하기 위해 데이터베이스 오브젝트(테이블, 인덱스 등) 통계 정보와 하드웨어적인 시스템 성능 통계 정보(CPU 속도, Single Block Read Time, Multiblock Read Time 등)를 이용한다.
- Plan Generator는 하나의 쿼리를 수행하는 데 있어, 후보군이 될 만 한 실행 계획들을 생성해내는 역할을 한다.
| 스스로 학습하는 옵티마이저(Self-Learning Optimizer) |
|---|
| V$SQL, V$SQL_PLAN_STATISTICS, V$SQL_PLAN_STATISTICS_ALL, V$SQL_WORKAREA 등에 SQL 별로 저장된 수많은 런타임 수행 통계를 보면 앞으로 옵티마이저의 발전 방향을 예상할 수 있다. 옵티마이저는 지금까지 오브젝트 통계와 시스템 통계로부터 산정한 ‘예상’ 비용만으로 실행 계획을 수립했지만 앞으로는 예상치가 빗나갔을 때 이들 런타임 수행 통계를 보고 실행 계획을 조정할 움직임을 보이고 있다. 수년 전부터 회자되기 시작한 이른바 스스로 학습하는 옵티마이저를 9i와 10g에서 선보이는 듯하더니 11g부터 이를 본격화한 것이 아닌가 싶다. 1권에서 설명했던 적응적 서 공유(Adaptive Cursor Sharing) 기법이 그런 가능성을 시사하고, 이미 9i에서 소개된 동적 실시간 최적화(Dynamic Runtime Optimizations, 다음 절에서 설명함) 개념도 그 일환이라고 말할 수 있다. 전조등 광량을 자동 조절하고, 실내 온도에 따라 에어컨 바람 세기를 스스로 조절하며, 비가 내리는 양에 따라 와이퍼(wiper) 속도를 자동 조절하는 최첨단 자동차처럼 스스로 학습하면서 SQL을 최적화하는 옵티마이저의 탄생을 보게 될 날도 머지 않은 듯하다. (하지만, 정말 믿고 쓸 만한 물건이 나오기까지는 꽤 오랜 시간이 걸리지 않을까? 인류가 운전까지 대신해 주는 자동차를 상상한 지 꽤 오래됐지만 아직 상용화되지 못하고 테스트 수준에 머무는 것처럼 말이다.) |
(4) 옵티마이저 모드
옵티마이저 모드로 선택할 수 있는 값으로는 아래 5가지가 있고, 시스템 레벨, 세션 레벨, 쿼리 레벨에서 바꿀 수 있다.
- rule
- all_rows
- first_rows
- first_rows_n
- choose
1
2
3
alter system set optimizer mode = all_rows; -- 시스템 레벨 변경
alter session set optimizer mode = all_rows; -- 세션 레벨 변경
select /*+ all_rows */ * from t where ... ; -- 쿼리 레벨 변경
RULE
RBO 모드를 선택하고자 할 때 사용한다.
ALL ROWS
쿼리 최종 결과 집합을 끝까지 Fetch하는 것을 전제로, 시스템 리소스(VO, CPU, 메모리 등)를 가장 적게 사용하는 실행 계획을 선택한다.
DML 문장은 일부 데이터만 가공하고 멈출 수 없으므로 옵티마이저 모드에 상관없이 항상 all_rows 모드로 작동한다. select 문장도 union, minus 같은 집합( G e ) 연산자나 for update 절을 사용하면 all_rows 모드로 작동한다. PL/SQL 내에서 수행되는 SQL도 힌트를 사용하거나 기본 모드가 rule인 경우를 제외하면 항상 all_rows 모드로 작동한다.
FIRST ROWS
전체 결과 집합 중 일부 로우만 Fetch하다가 멈추는 것을 전제로, 가장 빠른 응답 속도를 낼 수 있는 실행 계획을 선택한다. 사용자가 만약 끝까지 Fetch한다면 오히려 더 많은 리소스를 사용하고 전체 수행 속도도 느려질 수 있다.
first_rows는 비용과 규칙(휴리스틱)을 혼합한 형태의 옵티마이저 모드다. 얼마만큼을 Fetch할지 지정하지 않았으므로 정확한 비용을 예측할 수 없고, 따라서 옵티마이저는 내부적으로 정해진 규칙을 사용한다. 예를들어, order by 컬럼에 인덱스가 있으면 Table Full Scan 비용과 비교해보지도 않고 무조건 그 인덱스를 이용해 sort order by 연산을 대체한다. 이것이 규칙 (14위)이다. 규칙을 사용하긴 하지만 통계 정보를 이용하므로 비용기반 옵티마이저임에는 틀림없다.
first_rows가 RBO보다 낫긴 해도 완벽한 비용에 근거하지 않기 때문에 불합리한 결정을 할 때가 종종 있다. 이를 보완하기 위해 9i부터 새로운 옵티마이저 모드 first_rows_n이 도입되었고, first_rows는 이제 과거 버전과의 호환성을 위한 용도로만 남게 되었다.
FIRST_ROWS_N
사용자가 처음 1개 로우만 Fetch하는 것을 전제로, 가장 빠른 응답 속도를 낼 수 있는 실행 계획을 선택한다. n으로 지정할 수 있는 값은 1, 10, 100, 1000 네 가지며, 사용자가 지정한 n개 로우 이상을 Fetch한다면 오히려 더 많은 리소스를 사용하고 전체 수행 속도도 느려질 수 있다.
1
2
alter session set optimizer mode = first_rows_100;
select /*+ first_rows (100) */ * from t where ... ;
힌트를 사용할 때는 괄호 안에 0보다 큰 어떤 정수 값이라도 입력 가능하므로 파라미터를 이용할 때보다 더 정밀하게 제어할 수 있다.
f irst_rows 와 달리 first_rows_n 은 완전한 CBO 모드로 작동한다. 예를 들어, first_rows_100 이면 100개 로우를 가장 빨리 리턴할 수 있는 최저 비용의 실행 계획을 선택하며, Table Full Scan 비용이 오히려 낮다면 그것을 선택한다.
CHOOSE
액세스되는 테이블 중 적어도 하나에 통계 정보가 있다면 CIBO, 그 중에서도 all_rows 모드를 선택한다. 어느 테이블에도 통계 정보가 없으면 RBO를 선택한다.
9i 까 지 는 choose 가 기 본 설 정 이 었 으나 10g 부 터 는 all_rows 가 기 본 옵 티 마 이 저 모 드 로 설 정 된다. 10g부터 RBO를 공식적으로 지원하지 않게된 탓이며, 동적 샘플링 기본 레벨이 2로 바뀐 것과도 무관하지 않다. 즉, 통계 정보 없는 테이블을 발견하면 무조건 동적 샘플링이 일어나기 때문에 RBO로 작동할 일이 없어진 것이다.
옵티마이저 모드 선택
일반적으로 first rows 는 OLTP 환경에서, all_rows 는 DW나 배치 프로그램 등에서 사용하는 옵티마이저 모드라고 알려져 있다. 하지만 요즘과 같은 웹 애플리케이션 환경에서는 OLTP이더라도 대개 all_rows 가 올바른 선택이다. 이유는 간단하다. 애플리케이션에서 수행되는 쿼리 자체가 전체 범위 처리를 요구하기 때문이다.
all_rows 모드는 SQL 결과 집합을 모두 Fetch하기에 가장 효율적인 실행 계획을 옵티마이저에게 요구하는 것이고, first_rows 는 그 중 일부만 Fetch하고 멈추는 것을 전제로 하는 옵티마이저 모드다. 따라서 DW 시스템 또는 배치 프로그램이라면 all_rows 모드를 선택하는 것이 당연하게 느껴진다. OLTP인 경우는 어떤가? OLTP일 때는 애플리케이션 아키텍처에 따라 다르다고 할 수 있다.
first_rows 모드가 효과적인 애플리케이션 아키텍처는 주로 2-Tier 환경의 클라이언트/서버 구조다. 이 애플리케이션 구조의 특징은 전체 결과 집합이 아무리 많아도 사용자가 스크롤을 통해 일부만 Fetch하다가 멈춘다는 점이다. 결과 집합을 끝까지 Fetch하거나 다른 쿼리를 수행하기 전까지 SQL 커서는 오픈된 상태를 유지한다.
반면, OLTP 성 애플리케이션인 경우로 3-Tier 구조는 클라이언트와 서버 간 연결을 지속하지 않는 환경이므로 오픈 커서를 계속 유지할 수 없어 페이지 처리 기법을 주로 사용한다. 이를 위해 rownum으로 결과 집합을 10건 내지 20건으로 제한하는 쿼리를 주로 사용한다. 요지는, 대량의 데이터에서 일부만 Fetch하다 멈추는 것이 아니라 집합 자체를 소량으로 정의한다는 것이다.
바인드 변수와 연관해 테스트해보면 좀 더 복잡한 이슈들을 발견하게 되지만 그런 불합리한 요소들은 옵티마이저 버전이 올라가면서 개선될 것으로 판단된다. 어차피 모든 SQL을 만족하게 하는 옵티마이저 모드는 현존하지 않는다. 애플리케이션 특성상 확실히 first_rows 가 적합하다는 판단이 서지 않는다면 all_rows를 기본 모드로 선택하고, 필요한 쿼리 또는 세션 레벨에서 first_rows 모드로 전환할 것을 권고한다.