<오라클 성능 고도화 원리와 해법2> Ch03-04 통계정보 1
오라클 성능 고도화 원리와 해법2 - Ch03-04 통계정보 1
실행 계획을 수립할 때 CBO는 SQL 문장에서 액세스할 데이터 특성을 고려하기 위해 통계 정보를 이용한다. 따라서 최적의 실행 계획을 위해서는 통계 정보가 데이터 상태를 정확하게 반영하도록 관리해 주어야 한다.
옵티마이저가 참조하는 통계 정보 종류로 아래 네 가지가 있다.
- 테이블 통계
- 인덱스 통계
- 컬럼 통계(히스토그램 포함)
- 시스템 통계
(1) 테이블 통계
테이블 통계만 수집할 때는 아래 명령어를 사용하며, compute는 전수 검사, estimate는 표본 조사를 뜻한다.
1
2
3
analyze table emo compute statistics for TABLE;
analyze table emp estimate statistics sample 5000 rows for TABLE;
analyze table emp estimate statistics sample 50 percent for TABLE;
통계 정보를 수집할 때 이제는 analyze 명령어를 사용하지 말라는 것이 오라클의 공식적인 입장이다. 그럼에도 이 명령어로 설명하는 이유는 테이블 통계, 인덱스 통계, 컬럼 통계를 따로 따로 수집하는 것을 보임으로써 이들 개념을 명확히 이해하는 데 도움을 주기 위해서다. 오라클이 권장하는 dbms_stats 패키지의 자세한 사용법은 8절에서 다루며, 본 절에서는 analyze 명령어와 대비되도록 간단한 사용법만 설명하면서 넘어가려고 한다.
(2) 인덱스 통계
인덱스 통계를 수집할 때는 아래 명령어를 사용한다.
1
analyze INDEX emp pk compute statistics;
테이블에 속한 모든 인덱스 통계를 수집할 때는 아래 명령어를 사용한다.
1
analyze table emp compute statistics for ALL, INDEXES;
테이블과 인덱스 통계를 함께 수집하려면 아래와 같이 한다.
1
analyze table emp compute statistics for TABLE for ALL INDEXES;
참고로, 인덱스를 최초 생성하거나 재생성할 때 아래와 같이 compute statistics 옵션을 주면 자동으로 인덱스 통계까지 수집된다. 인덱스는 이미 정렬되어 있으므로 통계 정보 수집에 오랜 시간이 소요되지 않는다.
1
2
create index emp ename_idx on emp (ename) COMPUTE STATISTICS;
alter index emp ename_idx rebuild COMPUTE STATISTICS;
10g부터는 사용자가 이 옵션을 명시하지 않아도 오라클이 알아서 인덱스 통계까지 수집해준다. (이 기능을 방지하려면 optimizer.compute_index_stats 파라미터를 false로 설정하면 된다.)
(3) 컬럼 통계
아래는 테이블, 인덱스 통계는 제외하고 컬럼 통계만 수집하는 방법이다.
1
analyze table emp compute statistics for ALL COLUMNS SIZE 254;
size 옵션은 히스토그램의 최대 버킷 개수를 지정하는 옵션으로서, 1부터 254까지 허용된다. size를 명시하지 않으면 오라클이 75를 기본값으로 사용하므로 히스토그램이 생성되지 않도록 하고 싶을 때는 size 옵션을 1로 명시해야 한다. 컬럼 히스토그램에 대해서는 6절에서 자세히 다룬다.
일부 컬럼에 대한 통계만 수집할 때는 아래와 같이 한다.
1
analyze table emp compute statistics for COLUMNS ENAME SIZE 10, SAL SIZE 20;
히스토그램 버킷 개수를 컬럼별로 지정하지 않고 똑같이 20으로 지정할 때는 아래와 같이 하면 된다.
1
analyze table emp compute statistics for COLUMNS SIZE 20 ENAME, SAL, HIREDATE;
물론 테이블, 인덱스, 컬럼 통계를 아래와 같이 동시에 수집할 수도 있다.
1
2
3
4
analyze table emp compute statistics
for table
for all indexes
for all indexed columns size 254;
(4) 시스템 통계
시스템 통계는 I/O, CPU 성능 같은 하드웨어적 특성을 측정한 것으로서, 아래와 같은 항목들을 포함한다.
- CPU 속도
- 평균적인 Single Block I/O 속도
- 평균적인 Multiblock I/O 속도
- 평균적인 Multiblock I/O 개수
- I/O 서브시스템의 최대 처리량(Throughput)
- 병렬 Slave의 평균적인 처리량(Throughput)
과거에는 이들 항목이 고정된 상수였다. 즉, 옵티마이저 개발팀의 하드웨어 사양에 맞춰져 있었다. 그러다 보니 실제 오라클이 설치된 운영 시스템 사양이 그보다 좋거나 나쁠 때 옵티마이저가 잘못된 선택을하기 쉽다.
시스템 사양뿐만 아니라 애플리케이션이 OLTP 성이냐 DW 성이냐에 따라서도 위 항목의 특성이 달라지므로 옵티마이저 개발팀의 테스트 환경과 다른 환경이라면 최적이 아닌 실행 계획을 수립할 가능성이 높아진다.
이에 오라클은 9부터, 제품이 설치된 하드웨어 및 애플리케이션 특성에 맞는 시스템 통계를 수집하고 이를 활용함으로써 옵티마이저가 보다 합리적으로 선택할 수 있도록 하였다.
Workload 시스템 통계
9i에서 처음 도입된 Workload 시스템 통계는, 애플리케이션으로부터 일정 시간 동안 발생한 시스템 부하를 측정하여 보관함으로써 그 특성을 최적화 과정에 반영할 수 있게 한 기능이다. 통계를 수집하는 동안 애플리케이션이 I/O 집약적인 쿼리를 주로 수행했다면 통계 정보에 그것이 반영될 것이므로 이를 적용한 이후 옵티마이저는 덜 I/O 집약적인 실행 계획을 선택할 것이다.
Workload 시스템 통계 항목에는 아래 6가지가 있다.
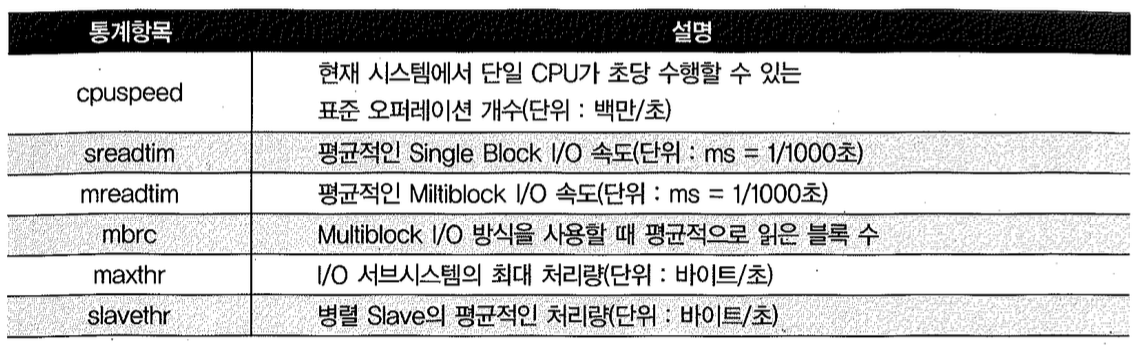
위 설명에 따라 앞서 본 sys.aux_stats$ 조회 결과를 해석하면 다음과 같다.
- 단일 CPU로 초당 1,149백만개의 표준 오퍼레이션을 수행할 수 있다.
- Single Block I/O 속도는 평균적으로 5.253ms이다.
- Multiblock I/O 속도는 평균적으로 3.122ms이다.
- Multiblock I/O 방식을 사용할 때 평균적으로 15개 블록씩 읽는다.
- I/O 서브시스템으로부터 초당 최대 1.73GB를 읽을 수 있다.
- 평균적으로 병렬 Slave가 초당 20MB를 읽는다.
뒤에서 설명할 NoWorkload 시스템 통계는 오라클이 무작위로 I/O를 발생시켜 측정한 값인 반면 Workload 시스템 통계는 실제 애플리케이션에서 발생하는 부하를 측정한 값이다. 만약 수집 기간 동안 애플리케이션에서 Full Table Scan이 발생하지 않는다면 mreadtim와 mbrc 항목이 측정되지 않을 것이며, 병렬 쿼리가 수행되지 않는다면 slavethr 항목이 측정되지 않는다.
따라서 Workload 시스템 통계를 제대로 활용하려면 통계 수집 전략을 잘 세워야 한다. 예를 들어 차세대 시스템을 구축 중이라면, 대표성 있는 시간대를 선택해 현 운영 서버에서 실제로 수집한 시스템 통계를 테스트 서버로 Export/Import 하고서 개발을 진행하면 된다. 개발 완료 후 현재와 다른 사양을 가진 서버에서 운영할 계획이거나, 전혀 새로운 애플리케이션을 개발할 때는 그 특성이 잘 반영되도록 부하 테스트 시나리오를 만들고 시스템 통계를 수집해야 한다.
NoWorkload 시스템 통계
관리자가 명시적으로 선택하지 않더라도 CPU 비용 모델이 기본 비용 모델로 사용되게 하려고 오라클 10g에서 NoWorkload 시스템 통계를 도입하였다. CPU 비용 모델은 시스템 통계가 있을 때만 활성화되기 때문이다.
NoWorkload 시스템 통계 항목과 (처음 데이터베이스를 기동할 때 설정되는) 기본값은 다음 표와 같다.
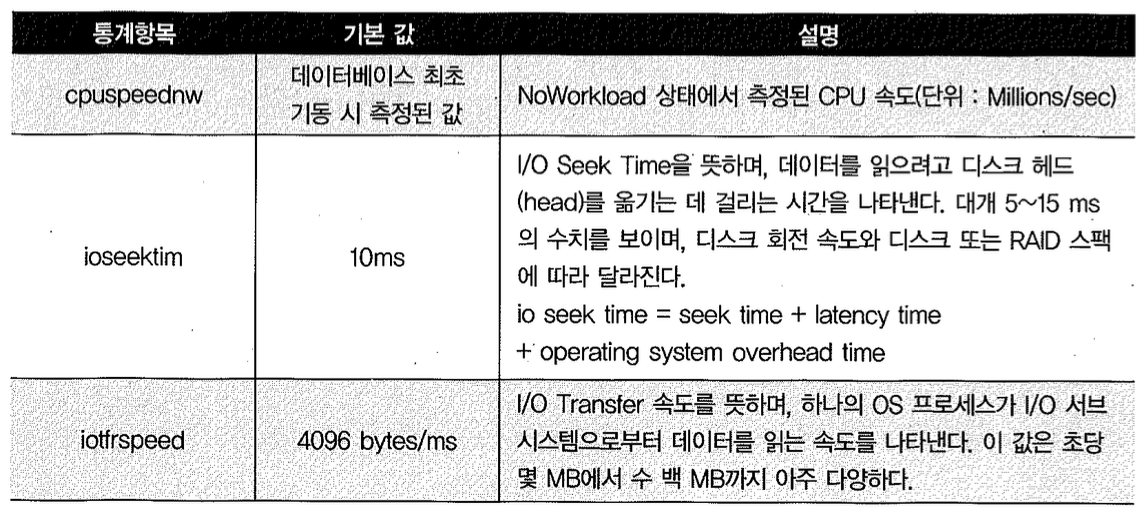
Workload 시스템 통계를 수집하고 반영하는 순간 NoWorkload 시스템 통계는 무시된다. Workload 시스템 통계가 수집되기 전까지는 아래 공식을 이용해 추정된 값으로 사용한다.
- cpuspeed = cpuspeednw
- mbrc = db file_multiblock_read_count
- sreadtim = ioseektim + db_block_size / iotfrspeed
- mreadtim = joseektim + mbrc * db_block size / iotfrspeed
시스템 통계를 제대로 활용하기 위해서는 Workload 시스템 통계가 바람직하지만 이를 수집하기 어려운 환경이 존재하며, 그럴 때 NoWorkload 시스템 통계를 사용한다. 예를 들어, 시스템 통계는 프로젝트 초기, 늦어도 단위 테스트 전에는 확정되어야 하는데 그 시점에 의미있게 부하 테스트 시나리오를 만들기 어려울 때가 많다.
어떤 이유에서 건 NoWorkload 시스템 통계를 이용하기로 했다면 기본 설정 값을 그대로 사용하지 말고, 적당한 부하를 준 상태에서 NoWorkload 시스템 통계를 수집해주어야 한다. NoWorkload는 부하가 없는 상태에서 수집하는 것이라고 오해하기 쉽지만, Workload와 마찬가지로 부하를 준 상태에서 측정된 값을 사용해야 시스템 통계로서 의미가 있다.
Workload 통계와 주요 차이점은 통계를 수집하는 방식에 있다. 즉, Workload는 실제 애플리케이션에서 발생하는 부하를 기준으로 각 항목의 통계치를 측정하는 반면 NoWorkload는 모든 데이터 파일 중에서 오라클이 무작위로 I/O를 발생시켜 통계를 수집한다. 따라서 시스템 부하 정도가 심할 때 NoWorkload 시스템 통계를 수집하면 구해진 값들도 달라진다.
이런 차이점을 이해한다면 Workload와 마찬가지로 NoWorkload도 시스템 부하가 어느 정도 있는 상태에서 수집되는 것이 바람직하다는 것을 알 수 있다. 시스템 통계를 도입한 취지가 최적화 과정에 시스템 특성을 반영하자는 것임을 상기하자.
NoWorkload 시스템 통계를 수집할 때는 dbms_stats.gather_system_stats 프로시저를 아무런 인자도 주지 않고 호출하거나 gathering_mode 인자를 아래와 같이 지정하면 된다.
1
2
3
begin
dbms_stats.gather_system_stats(gathering_mode => 'NOWORKLOAD');
end;
이 프로시저를 실행하는 동안 I/O 서브시스템에 약간의 부하가 발생하며, I/O 성능과 데이터베이스 크기에 따라 적게는 수초, 길게는 수분이 소요될 수 있다.