<오라클 성능 고도화 원리와 해법2> Ch03-05 카디널리티
오라클 성능 고도화 원리와 해법2 - Ch03-05 카디널리티
지금까지 옵티마이저 기본 원리와 통계 정보에 대해 살펴보았다. 지금부터는 데이터 딕셔너리에 저장된 통계 정보가 옵티마이저에 의해 구체적으로 어떻게 활용되는지 살펴볼 것이다.
5절(카디널리티), 6절(히스토그램), 7절(비용) 내용은 필자가 번역한 ‘비용 기반의 오라클 원리(원제: Cost-Based Oracle Fundamentals)’의 요약이라고 할 수 있다. 쉬운 예제와 함께 꼭 알아야 할 핵심 원리만 간추렸고, 일부 내용을 덧붙였다.
사실 옵티마이저의 복잡한 비용 계산 원리를 꼭 알 필요는 없다. 그것을 아는 만큼 SQL 튜닝을 잘 할 수 있는 것도 아니다. 그럼에도 본 서에서 간단하게나마 핵심 원리를 설명하려는 이유는, 8절에서 설명할 통계 정보 수집 전략의 필요성을 느끼도록 하는데 있다. 인덱스, 클러스터 등 옵티마이징 팩터가 동일한 상황에서 CBO 행동에 결정적 영향을 미치는 요소는 무엇보다 통계 정보다. 따라서 고성능 데이터베이스를 구축하는 데에는 정확하고 안정적인 통계 정보를 제공하는 일이 무엇보다 중요하다고 하겠다.
본 서에서 다루는 내용만으로 충분하다고 생각하지만 더 세부적인 비용 계산 원리를 공부하고 싶다면 ‘비용 기반의 오라클 원리’를 참조하기 바란다.
선택도를 통해 카디널리티가 구해지므로 선택도에 대한 개념부터 살펴보자.
(1) 선택도
선택도(Selectivity)는 전체 대상 레코드 중에서 특정 조건에 의해 선택될 것으로 예상되는 레코드 비율을 말한다. 선택도를 가지고 카디널리티를 구하고, 다시 비용을 구함으로써 인덱스 사용 여부, 조인 순서와 방법 등을 결정하므로 선택도는 최적의 실행 계획을 수립하는데 있어 가장 중요한 요인이라고 할 수 있다.
1
선택도 -> 카디널리티 -> 비용 -> 액세스 방식, 조인 순서, 조인 방법 등 결정
히스토그램이 있으면 그것으로 선택도를 산정하며, 단일 컬럼에 대해서는 정확도도 비교적 높다. 히스토그램이 없거나, 있더라도 조건에 바인드 변수를 사용하면 옵티마이저는 데이터 분포가 균일하다고 가정한 상태에서 선택도를 구한다.
히스토그램이 있을 때 선택도를 구하는 방식에 대해서는 다음 절에서 자세히 다루므로, 본절에서는 주로 히스토그램이 없을 때를 기준으로 설명한다. 비교를 위해 필요할 때만 중간중간 히스토그램을 생성하는 경우를 예로 들 것이다.
히스토그램 없이 등치(=) 조건에 대한 선택도를 구하는 공식은 다음과 같다.

히스토그램 없이 부등호, between 같은 범위 검색 조건에 대한 선택도를 구하는 기본 공식은 다음과 같다. (상수 조건일 때의 공식이며, 바인드 변수를 사용할 때의 규칙은 6절’(4) 바인드 변수 사용 시 카디널리티 계산’에서 설명한다.)

분자, 분모에 사용된 두 개의 값 범위는 컬럼 통계로서 수집된 high_value, low_value, num_distinct 등을 이용해 구한다 (dba_tab_columns 참조).
(2) 카디널리티
카디널리티(Cardinality)는 특정 액세스 단계를 거치고 나서 출력될 것으로 예상되는 결과 건수를 말하며, 총 로우 수에 선택도를 곱해서 구한다.
1
카디널리티 = 총 로우 수 × 선택도
컬럼 히스토그램이 없을 때 ‘=’ 조건에 대한 선택도가 1/num_distinct이므로 카디널리티는 아래와 같이 구해진다.
1
카디널리티 = 총 로우 수 X 선택도 = num_rows / num_distinct
선택도 및 카디널리티 계산식 테스트
옵티마이저가 실제로 위 공식에 따라 선택도와 카디널리티를 구하는지 테스트하기 위해 t_emp 테이블을 만들어보자.
CLERK과 SALESMAN 모두 카디널리티(=Rows)를 200으로 추정하였다. 히스토그램이 없으므로 평균적인 컬럼 분포를 가정해 정해진 계산식에 따라 선택도와 카디널리티를 구한 것이다.
(3) NULL 값 포함할 때
조건절 컬럼이 Null 값을 포함할 때는 카디널리티를 어떻게 구할까? 이를 테스트하기 위해 no <= 50인 500개 레코드의 job을 Null로 치환해보자.
1
2
3
4
5
SQL> update tenp set job = NUL where no <= 50;
500 행이 갱신되었습니다.
SQL> commit;
이제 아래 조건식에 의한 결과 건수는 500개일 것이다.
1
select * from t_emp where job is null;
아래와 같은 조건식은 어떤가?
1
select * from t_emp where job = null;
등치(=) 조건으로 비교할 때 양 쪽 값이 모두 Null이면 ‘참(true)’을 반환하도록 옵션을 제공하는 DBMS도 있지만 오라클은 이를 허용하지 않는다. 따라서 위 쿼리 결과는 항상 공집합이다.
따라서 아래와 같은 조건식일 때 바인드 변수에 어떤 값이 입력되든(Nu값이 입력되더라도) job이 Null 인 레코드는 결과 집합에서 제외된다.
1
select * from t_emp where job = job
’=’ 조건에 대한 선택도를 구할 때 이런 특성을 반영하려면 기존 공식에 Null 값이 아닌 로우 비중을 곱하고, 분모인 Distinct Value 개수에서 Null 값을 제외시키면 된다.
(4) 조건절이 두 개 이상일 때
조건절이 두 개 이상일 때의 카디널리티를 구하는 공식은 간단하다. 각 컬럼의 선택도와 전체 로우 수를 곱해주기만 하면 된다.
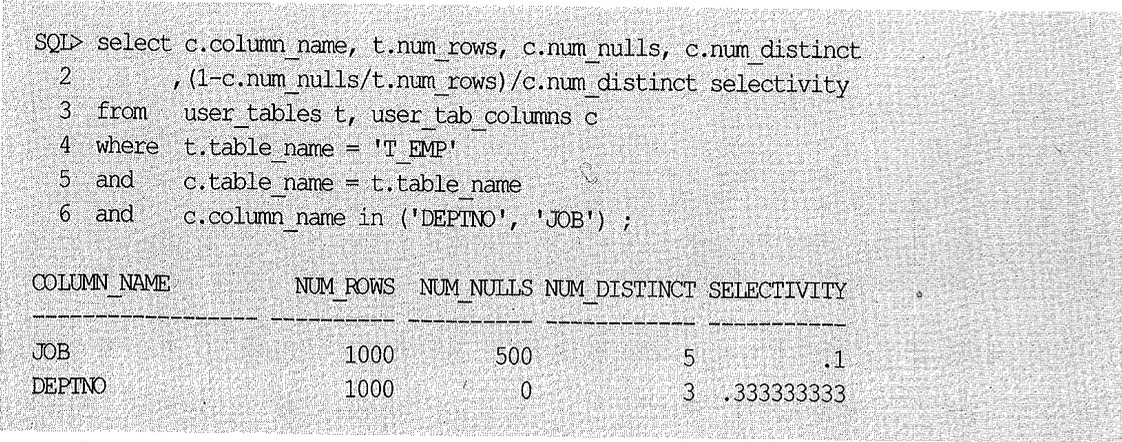
job과 deptno 컬럼의 선택도가 각각 0.1과 0.3이므로 옵티마이저가 구한 카디널리티는 (33-100 × 0.1 × 0.33)일 것이다. 실제 그런지 확인해보자.
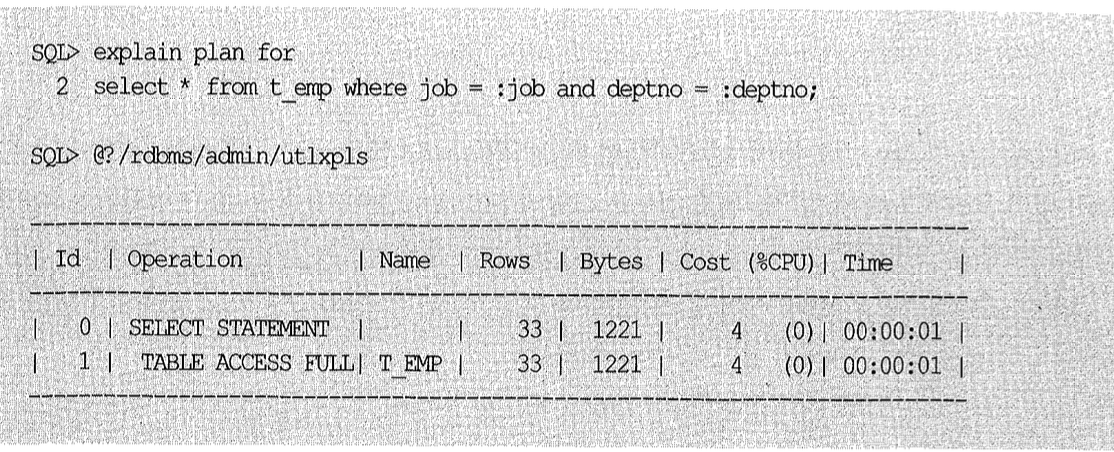
(5) 범위 검색 조건일 때
범위 검색 조건일 때는 선택도를 아래와 같은 식으로 구한다고 (1)항에서 설명하였다.

공식에서 알 수 있듯이, 옵티마이저는 조건 절에서 요청한 범위에 속한 값들이 전체 값 범위에 고르게 분포돼 있음을 가정한다.
(6) cardinality 힌트를 이용한 실행 계획 제어
옵티마이저가 계산한 카디널리티가 부정확할 때는 힌트를 이용해 사용자가 직접 카디널리티 정보를 제공할 수 있다.
아래 쿼리를 수행하면 dept의 카디널리티가 4이고, emp의 카디널리티가 14이므로 해시 조인을 위한 BuildInput으로서 dept가 선택된다. 만약 dept의 실제 카디널리티가 16이라면, 그래서 emp 테이블을 Build Input으로 삼고 싶다면 어떻게 해야할까?
1
2
select /*+ use_hash(d e) * / * from dept d, emp e
where d.deptno = e.deptno
leading이나 swap_join_inputs 힌트가 있지만 아래와 같이 cardinality 힌트를 이용할 수도 있다.
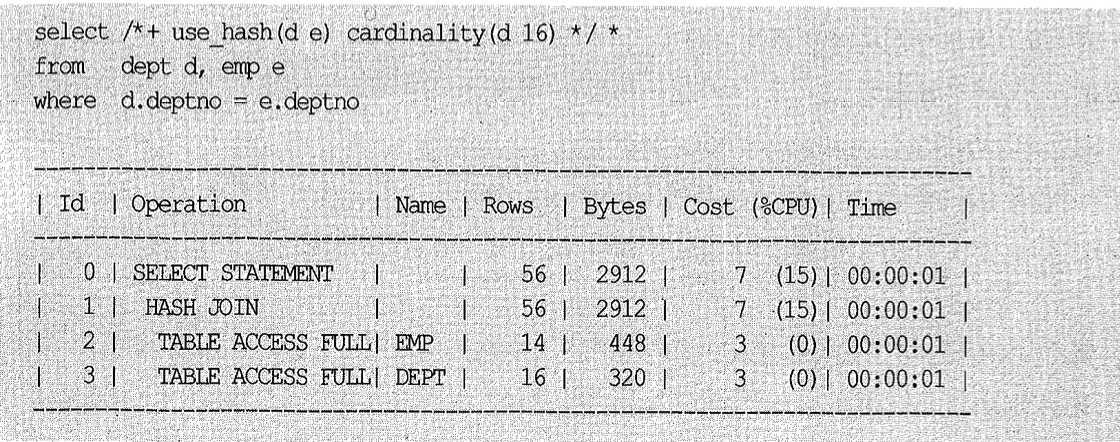
참고로, 10g부터는 opt_estimate를 이용할 수도 있다. 아래는 옵티마이저가 예상한 카디널리티(=4)에 4를 곱하라는 뜻이며, 바로 위 실행 계획과 똑같은 결과를 가져다준다.
1
2
3
select /*+ use_hash(d e) opt_estimate(table, d, scale_rows=4) * / *
from dept d, emp e
where d.deptno = e.deptno