<오라클 성능 고도화 원리와 해법2> Ch03-08 통계정보 2
오라클 성능 고도화 원리와 해법2 - Ch03-08 통계정보 2
(1) 전략적인 통계수집 정책의 중요성
지금까지 설명한 카디널리티와 비용 계산식의 세부 사항을 항상 기억할 필요는 없다. 다만, 그 원리를 이해함으로써 통계정보 수집이 얼마나 중요한지 깨닫는 것이 매우 중요하다.
4절 ‘통계정보 1’에서 개발자를 대상으로 통계정보의 기본 개념을 설명한 것이라면, 이 절은 실제 통계정보를 수집하고 관리해야 할 DB 관리자들이 효과적인 통계정보 수집 전략을 세울 수 있도록 돕는 데 목적이 있다.
CBO 능력을 최대한 끌어 올리는 핵심 요소
이 책은 오라클 성능 문제를 주로 개발자 중심으로 설명하고 있다. 아키텍처를 다룰 때 개발자에게 필요한 내용 위주로 구성했음을 읽은 독자라면 이해할 것이다. 그럼에도 본 절에서 통계정보를 관리적인 수준까지 좀 더 깊이 다루려는 것은 통계정보가 CBO에게 미치는 영향력이 그만큼 절대적이기 때문이다.
‘비용기반의 오라클 원리’를 번역하면서 역자 서문에 “옵티마이저가 그 능력을 최대한 발휘할 수 있도록 환경을 조성해주어야 한다”고 밝혔는데, 90%는 통계정보를 염두에 두고 한 말이다. 부정확한 통계정보를 옵티마이저에게 제공하고는 똑똑하지 못한 옵티마이저를 탓하는 일이 얼마나 많은가? “좋은 인덱스가 있는데도 엉뚱한 인덱스를 탄다”, “해시 조인이 낫는데 NIL 조인을 한다” 등등.
그런데 많은 경우 그 원인이 통계정보 이상(꽃)에 있음을 이해할 수 있겠는가? 마지막 장에서 효율화 원리에 서 통계정보의 중요성을 강조하면서 아래와 같이 언급한 것을 상기하기 바란다.
1
"전쟁에서 효과적으로 싸우려면 정보력이 뒷받침되어야 한다. 정보가 불충분하면 적군의 수효가 10만 명에 이르는 데 불과 20 ~ 30 명 소대원을 이끌고 무모하게 돌격 명령을 내리는 소대장이 나올 수 있다."
DB 관리자의 핵심 역할은 통계정보 관리
독자가 DBA 역할을 맡고 있다면 본 절에서 설명하는 내용에 대해 지금까지 충분한 이해가 있었는지 되돌아봐야 한다. 현재 개발 중인 DB에 접속해 가장 마지막 통계정보 수집일자가 언제인지 확인해보기 바란다. 만약 중요한 거래 테이블들의 마지막 통계 수집일자가 대부분 오래된 상태라면, 성능 문제 때문에 수많은 밤을 지샌 원인이 통계정보에 있을 가능성이 있으므로 DBA에게 본 절의 내용을 소개해주기 바란다.
DBA라고 하면 흔히 오브젝트 생성 관리, 백업 & 복구, 트러블 슈팅 등을 떠올리지만 CIBO 환경에서 그 이상으로 중요한 역할은 통계정보 수집 정책을 세우고 그에 따라 통계정보를 안정적으로 운영 • 관리 하는 데에 있다. 문제 없던 쿼리가 어느 날 갑자기 악성 SQL로 돌변했다면 가장 먼저 확인해야 할 테이블 통계정보에 이상이 없는지 확인해보라. 십중팔구 통계정보에서 비롯된 문제일 것이다.
통계정보 수집 시 고려사항
통계정보를 수집할 때 고려해야 할 중요한 네 가지 요소는 다음과 같다.
• 시간: 부하가 없는 시간대에 가능한 빠르게 수집을 완료해야 함 • 샘플 크기: 가능한 적은 양의 데이터를 읽어야 함 • 정확성: 전수검사할 때의 통계치에 근접해야 함 • 안정성: 데이터에 큰 변화가 없는데 매번 통계치가 바뀌지 않아야 함
가장 짧은 시간 내에 꼭 필요한 만큼만 데이터를 읽어 충분한 신뢰 수준을 갖춘 안정적인 통계정보를 옵티마이저에게 제공하려면 치밀한 전략이 있어야 한다. 자신이 관리하는 시스템 여건에 맞는 전략이 필요한 것이다.
어떤 테이블은 여러 파티션에 골고루 갱신이 이루어지는가 하면, 어떤 테이블은 특정 파티션에만 갱신이 이루어지기도 한다. 유지보수를 위한 서비스 다운타임이 매일 확보되는 시스템이 있는가 하면 24시간 가용성이 요구되는 시스템도 있다. OLTP냐 DW냐에 따라서도 다른 전략을 사용해야 한다. 또한 데이터 자체 특성에 따라서도 다른 전략이 필요한데, 만약 샘플 크기를 최소화하더라도 정확성, 안정성을 확보할 수 있다면 시간을 크게 줄일 수 있지만 그렇지 않다면 시간이 오래 걸리더라도 전수검사를 해야만 한다.
주기적으로 통계 수집하면서 안정적이어야 최적
통계정보의 중요성은 무엇보다 좋은 실행 계획을 통해 쿼리 성능을 높이는 데 있다. 따라서 정확성이 무엇보다 중요하며, 특히 OLAP처럼 비정형(adhoc) 쿼리들이 많은 시스템에선 시스템 성능을 결정짓는 가장 중요한 변수로 작용한다.
하지만 절대적인 최적의 성능을 구현하기보다 안정적인 운영을 바라는 OLI P Production 시스템 관리자 입장에서는 통계정보의 안정성이 더 중요할 수 있다. 그런 연유로, 통계정보 수집을 꺼리는 DB 관리자들도 상당수 있다.
실제 통계정보를 수집하지 않고 오라클을 운영하는 고객사를 두 군데 경험한 적이 있는데, 한 곳은 원래 통계정보를 수집했으나 몇 번 장애를 경험하고는 어느 순간부터 수집을 멈춘 경우였다. 다른 한 곳은 초기부터 아예 통계정보 없이 운영을 시작한 경우였다. 오라클 버전은 둘 다 9i 였다.
이 두 회사의 공통점은 개발팀의 SQL 힌트 구사 능력이 웬만한 전문가 수준 이상이라는 점이다. 힌트 없이는 제대로 된 실행 계획을 기대하기 어려운 지경에 이르렀고, 이제라도 통계정보를 수집하자고 하면 어떤 사태가 벌어질지 몰라 손사래를 치는 형국이다.
두 번째 회사의 경우 최근에 방문해보니 조만간 RAC를 도입하면서 10g 버전으로 업그레이드 할 계획이라는 얘기를 들었다. 놀라운 것은, 10g에서도 계속해서 통계정보 없이 운영할 생각을 갖고 있더라는 사실이다. 필자가 우려를 표시했음에도 지금까지 통계정보 없이 운영하던 터라 불안해 서 어쩔 수 없다는 것이다.
안정성이 중요하더라도 CBO를 사용하는 한 통계정보를 수집하지 않을 수 없다는 사실을 기억하기 바란다. 통계정보를 주기적으로 수집하면서도 안정적으로 운영되는 시스템이야 말로 최적이라고 할 수 있으며, 이를 위해선 시스템 환경에 맞는 전략적인 통계 수집 정책이 반드시 필요하다.
통계수집정책 수립은 필수
몇 가지 운영 전략을 소개하면, 통계를 수집할 필요가 없는 오브젝트에 대해서는 Lock 옵션으로 통계정보를 고정할 수 있다. 그리고 통계정보에 영향을 받아선 안 되는 중요한 일부 핵심 프로그램에 대해선 옵티마이저 힌트를 적용해 실행계획을 고정시키는 것이 최선이다.
운영 DB에서 수집한 통계정보를 개발 DB에도 반영한 상태에서 개발을 진행해야 하며, 프로그램을 운영 서버에 배포하기 전 충분한 테스트를 거쳐야 한다. 운영 서버와 테스트 서버간에는 오브젝트 통계 뿐만 아니라 시스템 통계까지 일치시켜야 하며, 당연히 옵티마이저 관련 파라미터도 일치시켜야 한다.
통계정보 변화 때문에 애플리케이션 성능에 심각한 문제가 발생했을 때를 대비해 가장 안정적이었던 최근 통계정보를 항상 백업해두기 바란다. 그래야 정상적이던 이전 상태로 빠르게 되돌릴 수 있다.
전략을 세우는 가장 세부단계에서는 아래 표에 예시한 것처럼 오브젝트별 통계수집 주기와 샘플링 비율 등을 표로 정리해두어야 한다.
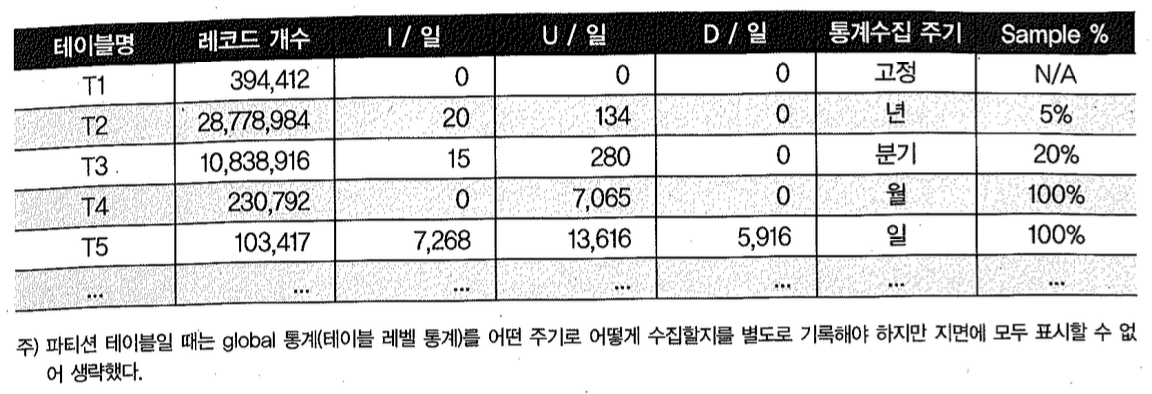
테이블 정의서에 기록하든 별도 산출물을 이용하든 데이터베이스 설계 시 주요 태스크로 진행해야 하고7), 이를 기준으로 스크립트를 작성해 시스템 오픈 전에 적정성 여부를 반드시 테스트해야 한다. 뒤에서 설명할 자동 수집 기능을 이용하더라도 그 안에 이 같은 전략을 담고 있어야지, 모든 걸 자동 기능에 의존한다면 시스템 운명을 오라클에 내맡기는 것과 다름없다.
- 이미 운영 중인 시스템이라면 DBA 팀 역할이라고 보는 것이 자연스럽지만 신 시스템을 설계하고 구축 중이라면 어느 팀 역할이라고 단정하기 어렵다. 기본 정책은 DBA 팀이 수립하겠지만 그에 따라 오브젝트별 통계수집 주기를 설계하는 일은 프로젝트 규모와 역할 정의에 따라 다를 수 있다. DBA, DA 누가 담당하는 데이터 발생 주기를 잘 아는 개발팀 또는 현업 담당자의 도움이 필요하며, 고성능 데이터베이스 구축을 위해서는 공동의 노력하에 반드시 거쳐야 할 매우 중요한 태스크라는 인식을 공유해야 한다.
이런 사전 준비와 테스트 과정 없이 시스템을 오픈하는 경우가 얼마나 많은가? 다시 강조하지만 시스템 여건과 오브젝트 특성에 맞는 통계수집 정책을 마련하지 않고는 안정적인 고성능 데이터베이스 구축은 요원한 일이다.
지금부터 시스템 환경에 따라 최적의 통계수집 정책을 수립하기 위해 어떤 옵션을 선택할 수 있는지 자세히 살펴보자.
(2) DBMS_STATS
통계 정보 수집을 위해 오랫동안 사용되어 온 Analyze 명령어를 버리고 이제는 dbms_stats 패키지를 사용하는 것이 바람직하다. dbms_stats가 더 정교하게 통계를 계산해내기 때문이며, 특히 파티션 테이블/인덱스일 때는 반드시 dbms_stats를 사용해야 한다.
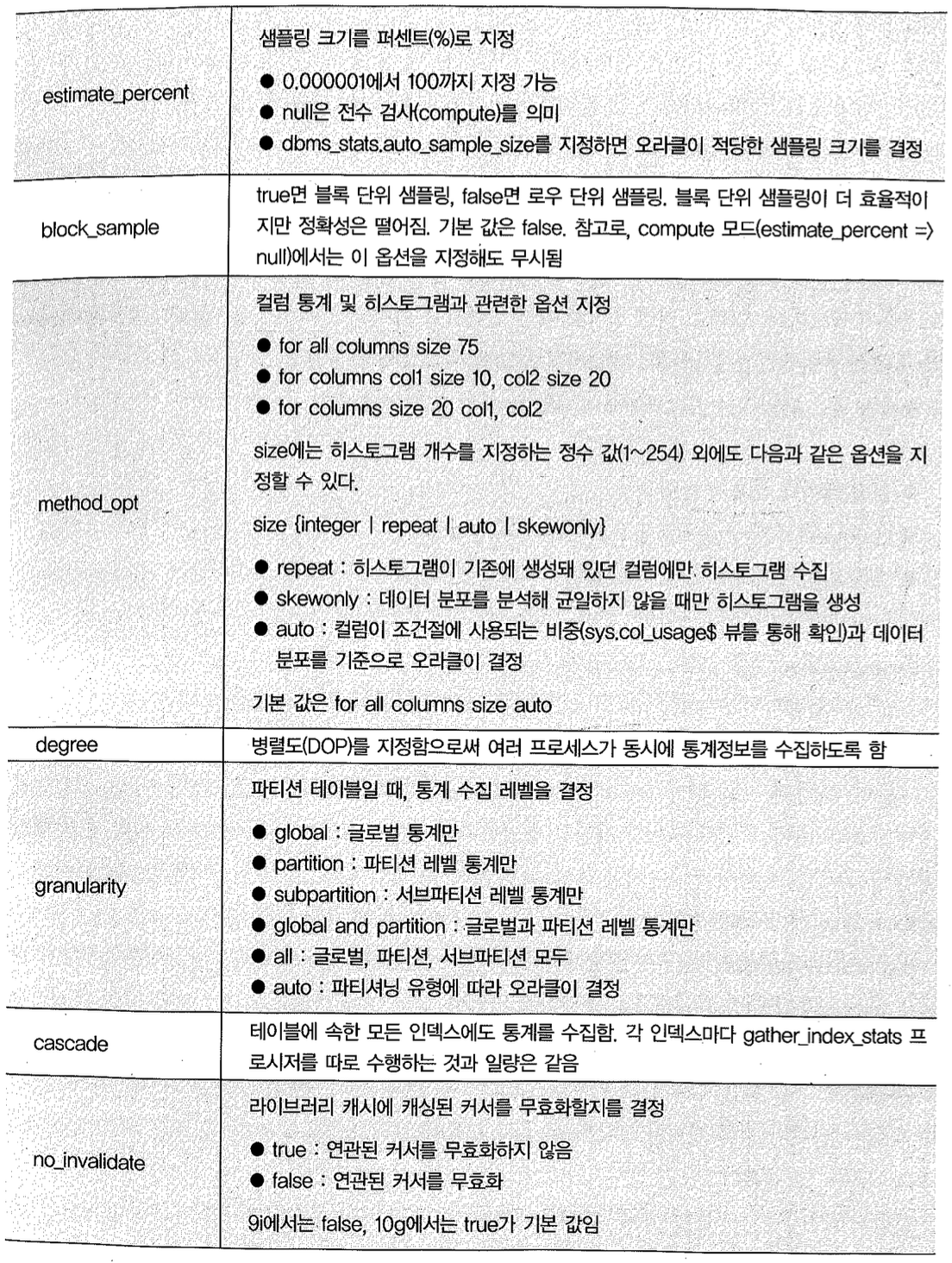
dbms_stats.gather_table_stats 프로시저의 인자를 표로 정리해 보면 다음과 같다. 참고로 버전마다 옵션 리스트와 기본 선택값이 조금씩 다르며, 여기서는 10g를 기준으로 설명하겠다.

(3) 컬럼 히스토그램 수집
히스토그램을 가지면 더 나은 실행계획을 수립하는 데 도움이 되지만 이를 수집하고 관리하는 비용이 만만치 않다. 따라서 필요한 컬럼에만 히스토그램을 수집해야 하며, 조건절에 자주 사용되면서 편중된(skewed) 데이터 분포를 갖는 컬럼이 주 대상이다.
흔히 인덱스 컬럼에만 히스토그램이 필요하다고 생각하기 쉬운데, 그렇지 않다. 테이블을 액세스한 후에 최종 선택도를 계산할 때는 인덱스가 없는 조건 컬럼의 선택도도 인자로 사용되고, 그렇게 구해진 선택도에 따라 다른 집합과의 조인 순서 및 조인 방식이 결정되기 때문에 히스토그램이 필요하다. 인덱스 컬럼 조건에 대한 선택도를 가지고 인덱스 사용 여부를 결정하게 되므로 인덱스 컬럼에는 두말할 것도 없이 히스토그램이 중요하다.
아래와 같은 컬럼에는 히스토그램이 불필요하다.
- 컬럼 데이터 분포가 균일
- Unique하고 항상 등치 조건으로만 검색되는 컬럼
- 항상 바인드 변수로 검색되는 컬럼
dbms_stats.gather_table_stats에서 컬럼 히스토그램 수집과 관련된 인자는 method_opt이다. 8i와 9i에서의 기본 값은 ‘for all columns size 1’ 이었는데 이는 모든 컬럼에 대해 히스토그램을 수집하지 말라는 의미다.
그런데 10g부터 기본값이 ‘for all columns size auto’로 바뀌었고 이는 오라클이 모든 컬럼에 대해 skew 여부를 조사해서 버킷 개수를 결정하라는 뜻이다. auto가 skew only와 다른 점은 해당 컬럼이 조건절에 사용되는 비중까지 고려해서 결정한다는 점이다. 이를 위해 오라클은 sys.colusage% 뷰를 참조한다.
10g에서 dbms_stats의 기본 동작 방식이 변경된 사실을 모른 채 시스템을 업그레이드 했다간 낭패를 보는 경우가 종종 발생하므로 주의하기 바란다.
없던 히스토그램이 생기면서 주요 SQL의 실행계획이 오히려 나쁜 쪽으로 바뀌는 예도 있거니와 통계 정보 수집 시간이 늘어나는 문제도 간과할 수 없다. 특히, 큰 테이블일수록 디스크 소트 부하 때문에 시간이 오래 걸린다. (그나마 auto는 조건절 사용 비중까지 고려해 히스토그램 생성 컬럼을 결정하므로 Skew only보다 조금 빠르다.)
통계 수집에 걸리는 시간이 짧은 테이블은 기본값으로 두어도 상관 없지만, 대용량 테이블일 때는 관리자가 직접 히스토그램 수집 컬럼을 아래와 같이 지정해주는 것이 바람직하다.
1
method opt →'for columns coll size 20 col2 size 254 col3 size 100'
10g부터는 기본값을 table-driven 방식으로 관리하므로 만약 dbms_stats 기본 동작 방식이 문제를 일으킨다면 dbms_stats.set_param 프로시저를 통해 기본값을 이전처럼 돌려놓을 수 있다.
(4) 데이터 샘플링
샘플링 비율을 높일수록 통계 정보의 정확도는 높아지지만 통계 정보를 수집하는 데 더 많은 시간이 소요된다. 반대로 샘플링 비율을 낮추면 정확도는 다소 떨어지지만 더 효율적이고 빠르게 통계를 수집할 수 있다.
샘플링 비율
dbms_stats 패키지에서 샘플링 비율을 조정하기 위해 estimate percent 인자를 사용한다. 이 값을 무작정 크게 한다고 정확도가 선형적으로 증가하는 것은 아니며, 일정 비율 이상이면 대개 충분한 신뢰 수준에도 달한다. 따라서 각 테이블별로 적정 샘플링 비율을 조사할 필요가 있는데, 모든 테이블을 조사 대상으로 삼기는 쉽지 않으므로 가장 큰 몇몇 테이블만 그렇게 하더라도 상당한 효과를 얻을 수 있다. 5%(-> 대개 이 정도면 충분한 신뢰 수준을 보임)에서 시작해 값은 늘려가며 두세 번만 통계를 수집해보면 적정 크기를 결정할 수 있다.
블록 단위 샘플링
block_sample 인자를 통해 블록 단위 샘플링을 할지 로우 단위 샘플링을 할지 결정한다. 블록 단위 샘플링이 더 빠르고 효율적이긴 하지만 데이터 분포가 고르지 않을 때 정확도가 많이 떨어진다. 기본값은 로우 단위 샘플링이다.
안정적인 통계 정보의 필요성
전수검사할 때는 그런 일이 없겠지만 샘플링 방식을 사용하면 매번 통계치가 다르게 구해질 수 있고 이는 실행계획에 영향을 미쳐 SQL 성능을 불안정하게 만든다.
특히 컬럼에 Null 값이 많거나 데이터 분포가 고르지 않을 때 그렇다. 선택도 구하는 공식의 세 가지 구성 요소가 Null 값을 제외한 로우 수, Distinct Value 개수, 총 레코드 개수를 상기하길 바란다. 특히, 총 레코드 개수에 비해 나머지 두 통계치는 컬럼 분포가 고르지 않을 때 샘플링 비율에 의해 크게 영향을 받는다.
해시 기반 알고리즘으로 NDV 계산 - 11g
컬럼 히스토그램을 사용할 수 없을 때는 NDV(number of distinct values )를 가지고 선택도를 계산하므로 이 값의 정확도가 매우 중요하다. 그런데 방금 얘기했듯이 분포가 고르지 않은 상황에서 샘플링 방식을 사용하면 이 값이 매번 다르게 구해질 수 있어 안정적인 실행 계획을 기대하기 어렵다.
그래서 오라클 11g는 해시 기반의 새로운 알고리즘을 고안해냈고, 대용량 파티션 또는 테이블 전체를 스캔하더라도 기존에 샘플링 방식을 사용할 때보다 오히려 빠른 속도를 낼 수 있게 되었다. 소트를 수행하지 않기 때문이며, 전체를 대상으로 NDV를 구하므로 정확도는 당연히 100%에 가깝다. 빠르고, 정확하면서도 안정적인 통계 정보를 구현할 수 있게 된 것이다.
(5) 파티션 테이블 통계 수집
파티션 테이블이면 오라클은 테이블 레벨 통계(‘global 통계’라고 함)와 파티션 레벨 통계를 따로 관리한다.
- 파티션 레벨 통계: Static Partition Pruning이 작동할 때 사용된다. 결합 파티션일 때는 서브 파티션 레벨로 통계를 관리할 수도 있다.
- 테이블 레벨 통계: Dynamic Partition Pruning이 작동할 때 사용된다. 쿼리에 바인드 변수가 사용됐거나, 파티션 테이블이 NIL 조인에서 Inner 쪽 테이블이면 액세스해야 할 대상 파티션 목록을 쿼리 최적화 시점에 정할 수 없기 때문이다. 또한 파티션 키에 대한 조건절이 없을 때도 테이블 레벨 통계가 사용된다.
analyze 명령을 이용해 통계 정보를 구하는 것은 deprecated된 기능이라고 설명했는데, 파티션 테이블일 때 특히 그렇다. dbms_stats은 global 통계를 위한 쿼리를 별도로 수행하는 반면, analyze는 파티션 통계를 가지고 global 통계를 유추하므로 부정확하다.
dbms_stats 패키지를 이용해 파티션 테이블의 통계를 수집할 때는 granularity 옵션을 신중하게 선택해줘야하며, 아래와 같은 값들이 선택 가능하다.
- global: 테이블 레벨 통계 수집
- partition: 파티션 레벨 통계 수집
- subpartition: 서브 파티션 레벨 통계 수집
- global and partition: 테이블과 파티션 레벨 통계 수집
- all: 테이블, 파티션, 서브 파티션 레벨 통계 수집
- auto: 파티션 유형에 따라 오라클이 결정
‘global’은 테이블 레벨 통계를 수집하고, ‘partition’은 파티션 레벨 통계를 수집한다. 파티션 레벨 통계를 수집할 때 테이블 레벨 통계가 미리 수집돼 있으면 그대로 두지만, 그렇지 않을 때는 파티션 레벨 통계로부터 추정된 값으로 테이블 레벨 통계를 설정한다.
참고로, dba/al/user_tables에서 볼 수 있는 항목 중 globalstats은 테이블 레벨 통계 수치들이 어떻게 구해졌는지를 알려준다. 즉, 테이블 레벨 통계를 따로 수집했다면 YES, 파티션 통계를 이용해 추정했다면 NO로 표시된다.
테이블 통계와 파티션 통계를 같이 수집하려면 ‘global and partition’을 선택하면 된다. 내부적으로 global 통계를 위한 쿼리를 한 번 더 수행하므로 각각 수집할 때와 비교해 속도 차이는 없다.
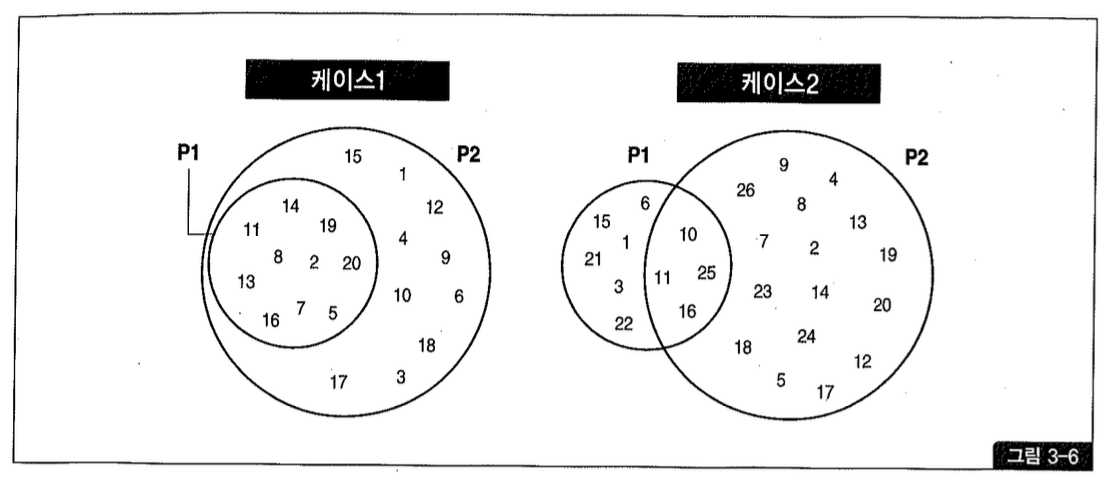
쿼리를 한 번 더 수행할 필요 없이 파티션 통계를 이용해 테이블 전체 통계를 구하면 될 것 같은데 오라클이 그렇게 하지 않는 이유는 NDV 때문이다. 예를 들어, 어떤 컬럼의 NDV가 파티션 P1과 P2에서 각각 10개와 20개일 때 테이블 레벨 NDV는 몇 개인지 추정할 수 있겠는가? 물론 20과 30 사이의 값 이 라는 것 쯤 은 추 정 할 수 있 지 만 그 중 하 나 를 선 택 할 수 는 없 다.
- 20: P2에 있는 어떤 컬럼 값의 집합(Domain)이 P1의 값 집합을 완전히 포함할 때
- 30: 어떤 컬럼 값의 집합이 P1, P2간에 완전히 배타적일 때
그림3-6에 예시한 케이스1은 테이블 레벨 NDV가 20이고, 케이스2는 26이다.
Range 파티션 테이블은 대개 새 파티션을 추가하면 그곳에만 데이터가 입력되는데, 통계를 수집하려고 대용량 파티션 테이블 전체를 두 번 스캔하는 것은 문제가 있어보이지 않는가? 그렇다고 데이터가 입력되는 파티션만 통계 정보를 계속 갱신한다면 테이블 통계는 어느 순간부터 매우 부정확한 상태에 놓이게 된다. NDV는 물론 low value/high value와 히스토그램이 특히 그렇다.
실제 이 문제로 골머리를 앓는 DBA가 많고, 파티션 테이블에 대한 통계 관리 소홀로 시스템 정찰이 발생하는 예도 있다. 대용량 파티션 테이블에 대한 통계 수집 효율성을 높일 방안과 전략이 필요해보인다.
10g 이하 버전을 사용하고 있다면, 아래처럼 최근 파티션만 통계를 수집하고나서 테이블 전체 통계를 한 번 더 수행하는 방식을 사용하는 것이 효과적이다. 테이블마다 프로시저를 두 번 호출하도록 스크립트를 작성하는 것이 성가시더라도 어쩔 수 없다.
NDV를 제외한 Incremental Global 통계 - 10.2.0.4
10.2.0.4 버전에서 granularity 인자에 선택할 수 있는 값으로, ‘approx global and partition’이 추가되었다. 이 옵션은 ‘global and partition’과 다른 점은, 테이블 통계를 위한 쿼리를 따로 수행하지 않고 파티션 레벨 통계로부터 집계한다는 데에 있다. 테이블 레벨 컬럼 히스토그램도 파티션 레벨로부터 집계한다. 단, 컬럼 NDV와 인덱스의 Distinct Key 개수는 제외된다.
NDV를 포함한 완벽한 Incremental Global 통계 - 11g
앞에서, 전체 데이터를 읽지만 소트 없이 해시 방식으로 빠르게 NDV를 구하는 11g 신기능을 소개했는데, 11g에서는 파티션 레벨 NDV를 이용해 Global NDV를 정확히 구할 수 있는 방법까지 제공하기 시작했다.
파티션 레벨 NDV로부터 테이블 레벨 NDV를 구하는 것이 불가능하다고 설명했는데, 어떻게 11g에서 가능해진 것일까? 오라클은 NDV를 포함한 Incremental Global 통계 수집’ 기능을 제공하려고 파티션 레벨 컬럼별로 synopsis라고 하는 별도의 메타데이터를 관리하기로 했다.
synopsis는 Distinct Value에 대한 샘플(그림3-6에 표현된 각 원소)이라고 생각하면 된다. 모든 파티션마다 각 컬럼이 갖는 값의 집합(Domain)을 보관했다가 이를 머지(merge)함으로써 Global NDV를 구한다. (기존에는 집합 개수만 보관했기 때문에 불가능했던 것이다.)
사실 Incremental Global 통계 수집 기능은 당연히 제공됐어야할 기능이다. 그렇지 못한 상태에서 오라클 10g부터 자동 통계 수집 기능(뒤에서 설명함)이 기본으로 설정된 것을 보고 적잖은 우려가 됐었다. 현재 기업들이 보유한 엄청난 데이터량을 감안하면 매번 대용량 파티션 테이블을 두 번씩 읽는 기존 방식의 문제점을 쉽게 예상할 수 있다.
실제 이 옵션을 그대로 받아들인 시스템들이 기간 통계 수집 시간 때문에 곤혹을 치렀고, 곳곳에서 아우성하니까 부랴부랴 10.2.0.4에서 패치를 통해 ‘NDV를 제외한 Incremental 방식’을 제공하게된 것이다. 늦긴 했지만 11g에서 ‘NDV까지 포함한 Incremental Global 통계’를 수집할 수 있도록 개선한 것은 무척 다행스럽고, 이제는 자동 통계 수집 기능을 이용해볼 만하다는 생각이든다.
(6) 인덱스 통계 수집
테이블 통계를 수집하면서 cascade 옵션을 true로 설정하면 테이블에 속한 모든 인덱스 통계도 같이 수집된다. 통계를 같이 수집한다고해서 더 빠른 것은 아니며, 인덱스마다 gather index_stats 프로시저를 따로 수행하는 것과 일랑은 같다.
문제는, 대용량 테이블이어서 샘플링 비율을 지정하면 인덱스 통계까지도 같은 비율이 적용된다는 데에 있다. 인덱스는 통계 수집에 걸리는 시간은 매우 짧아 굳이 샘플링 방식을 사용할 필요가 없는데도 말이다. (테이블 통계 수집에는 소트 연산이 발생하지만 인덱스는 이미 정렬된 상태여서 소트 연산이 불필요하기 때문에 빠르다.)
그럴 때는 아래와 같이 테이블 통계만 샘플링 방식을 사용하고, 인덱스는 전수검사하도록 각기 통계를 수집해주는 것이 좋다.
1
2
3
4
5
6
7
8
begin
-- 테이블 통계는 estimate mode
dbms_stats.gather_table_stats(user, 'big_table', cascade=> false, estimate_percent=>10);
-- 인덱스 통계는 compute mode
dbms_stats.gather_index_stats(user, 'big_table_pk', estimate_percent=>100);
dbms_stats.gather_index_stats(user, 'big_table_x1', estimate_percent=>100);
end;
/
(7) 캐싱된 커서 Invalidation
no_invalidate 옵션을 어떻게 지정하느냐에 따라 통계를 수집한 테이블과 관련된 SQL 커서의 무효화 시점이 달라진다.
- false: 통계 정보 변경 시 관련된 SQL 커서들이 즉시 무효화된다. 따라서 곧이어 첫 번째 수행하는 세션에 의해, 새로 갱신된 통계 정보를 이용한 실행 계획이 로드(하드 파싱)된다.
- true: 통계 정보 변경 시 관련된 SQL 커서들을 무효화하지 않는다. SQL 커서가 자동으로 Shared Pool에서 밀려났다가 다시 로드될 때 비로소 새로 갱신된 통계 정보를 사용한다.
- dbms_stats.auto_invalidate: 통계 정보 변경 시 관련된 SQL 커서들을 한꺼번에 무효화하지 않고 정해진 시간(Invalidation time window) 동안 조금씩 무효화한다. 무효화된 수많은 커서가 동시에 수행되면서 하드 파싱에 의한 라이브러리 캐시 경합이 발생하는 현상을 방지하려고 10g에서 도입된 기능이다.
중요한 것은, 9i에서 false이던 기본값이 10g에서 dbms._stats.auto_invalidate로 바뀌었다는 사실이다. 따라서 기존 통계 수집 스크립트를 그대로 사용하면 관련 SQL 커서들이 곧바로 무효화되지 않는 현상이 발생한다.
이 기능을 제어하는 파라미터는 _optimizer_invalidation_period이고, 기본 값은 18000 초다. 즉, 늦어도 5시간 이내에는 관련 SQL 커서가 무효화된다.
(8) 자동 통계 수집
오라클 10g부터 기본적으로 매일 밤 10시부터 다음 날 아침 6시까지 모든 살 자오브젝트에 대한 통계를 자동 수집하도록 100이 등록돼있다. 이 기능은 gather_stats_job에 의해 자동 수행되며, 통계 정보가 없거나 통계 정보 수집 후 DML이 많이 발생(_ab.statistics 뷰에서 Stats.slais 컬럼 참조) 한 모든 오브젝트를 대상으로 한다.
GATHER_STATS_JOB
gather_stats_job은 데이터베이스 생성시 자동으로 등록되며, Maintenance 윈도우 그룹(maintenance_window_group)에 등록된 윈도우가 열릴 때마다 스케쥴러에 의해 수행된다.
통계 정보 갱신 대상 식별
오라클은 통계 정보 수집이 필요한 오브젝트인지를 판별하기 위해 테이블 모니터링 기능을 제공한다. 9i에서는 nomonitoring 옵션이 기본이었고 필요한 테이블에만 관리자가 아래와 같이 monitoring 옵션을 지정했지만 10g에서는 이 옵션이 아예 deprecated 돼 모든 사용자 테이블이 모니터링되고 있다.
1
alter table emp monitoring;
statistics level이 typical 또는 all 일 때 오라클은, monitoring 옵션 이 지정된 테이블에 발생하는 DML 발생량을 모니터링한다. 수집된 테이블별 DML 발생량은 *_tab_modifications 뷰를 통해 조회해볼 수 있으며, inserts, updates, deletes 컬럼에 표시된 수치는 마지막 통계 정보가 수집된 이후의 DML 발생량이다.
오라클은 모니터링 대상 테이블에 10% 이상 변경이 발생했을 때 해당 테이블을 stale/상태(Jabstanistes 뷰에서 stale-stais=VES)로 바꾼다. 그러고 나서 gather_database_stats 또는 gather_schema_stats 프로시저를 호출하면서 option 인자에 gather stale’ 또는 gather
auto. 를 지정하면 stale 상태인 테이블들에 대해 통계 정보를 새로 수집한다. 참고로, 11g에서는 stale 상태로 바뀌는 임계치를 오브젝트 별로 조정할 수 있다.
실제 테스트해보면 테이블에 10% 이상 변경을 가하더라도 *_tab_modifications과 *_tab.statistics 뷰 stalestats 컬럼에 변화가 생기지 않는 것을 발견한다. 이는 모니터링 결과를 Shared Pool에 모아두고 SMON 이 주기적으로(대략 3시간) 딕셔너리에 반영하기 때문이다. 현재까지의 변경 사항이 딕셔너리에 바로 반영되도록 하려면 dbms_stats.flush_database_monitoring_info 프로시저를 호출하면 된다.
자동 통계 수집 기능 활용 가이드
평소 관심을 두지 않다가 일 년에 한 두 번쯤만 통계 정보를 수집하는 DBA 팀을 종종 볼 수 있는데, 그런 경우라면 오라클이 제공하는 자동 수집 기능에 의존하는 것이 나을 수 있다. (10g에서 자동 통계 수집 기능이 활성화된 사실을 모르고 매일 새벽에 수동으로 통계 정보를 수집하는 경우도 본 적이 있다. 그 결과, 통계 정보를 두 번씩 수행하는 셈이다.)
하지만 대형 데이터베이스를 관리한다면 10g에서 제공하는 자동 통계 수집 기능은 사용하지 않는 편이 좋겠다. 특히, Maintenance 윈도우 이내에 통계 수집이 완료되지 않는 경우가 생기면 시스템을 불안정한 상태에 빠뜨릴 수 있으므로 주의해야 한다. 될 수 있으면 앞에서 설명한 것처럼 오브젝트별 전략을 세우고 가장 짧은 시간 내에 정확하고 안정적인 통계 정보를 수집할 수 있도록 별도의 스크립트를 준비하는 것이 좋다.
11g에서는 앞서 소개한 여러 기능과 바로 이어서 설명할 Statistics Preference 기능 때문에 자동 통계 수집 기능이 꽤 유용해졌다. 그렇더라도 오브젝트별 수집 전략은 여전히 필요하며, 과거에 스크립트를 직접 작성하던 것이 이제 파라미터 driven 방식으로 바뀐 것에 불과하다. 개별 오브젝트별 선택 사양을 입력해두면 자동 수집 기능이 작동할 때 오라클이 그 내용에 따라 통계 정보를 수집해준다.
(9) Statistics Preference
지금까지 설명한 몇 가지 이유 때문에 오라클 10g에서는 자동 통계 수집 기능을 그대로 사용하기에 무리가 따른다. gather_stats_job을 제거하고 시스템 환경과 애플리케이션 특성에 맞게 설정된 별도의 프로시저를 작성해서 Job에 등록해주는 것이 바람직하다.
오브젝트별로 일일이 스크립트를 작성하는 게 귀찮아 자동 통계 수집 기능을 그대로 사용하고 싶다면, 기본 설정을 적용하고 싶지 않은 오브젝트에만 Lock을 설정(dars.statslocklablestats 프로시저 참조한 상태에서 전체 통계를 수집하는 방법을 생각해볼 수 있다. 전체 통계 수집이 끝나면 Lock을 설정했던 오브젝트에 Lock을 풀고 통계를 수집하는, 별도의 Job을 수행하면 된다.
관리자들의 그런 불편을 모를 리 없는 오라클이 11g에서 매우 유용한 기능을 선보였다. Statistics Preference라고 불리는 기능으로서 gather_stats_job을 그대로 활성화한 상태에서 테이블 또는 스키마별로 통계 수집 방식을 따로 설정할 수 있게 한 것이다. 그러면 자동 통계 수집 기능이 작동할 때 해당 테이블 또는 스키마에 대해서는 기본 설정값을 무시하고 사용자 지시사항에 따라 통계 정보를 수집한다.
이제 시스템 여건과 테이블 특성에 맞는 통계 수집 정책을 자동 통계 수집 기능에 반영할 수 있게 되었고, 이 기능과 Incremental Global 통계 기능을 이용함으로써 11g에서 자동 통계 수집 기능의 활용 가능성이 훨씬 높아졌다.