<오라클 성능 고도화 원리와 해법2> Ch04-02 서브쿼리 Unnesting
오라클 성능 고도화 원리와 해법2 - Ch04-02 서브쿼리 Unnesting
(1) 서브쿼리의 분류
서브쿼리는 SQL 문장 내에서 괄호로 묶인 별도의 쿼리 블록을 의미한다. 즉, 쿼리에 내장된 또 다른 쿼리다. 서브쿼리를 DBMS마다 조금씩 다르게 분류하는데, 오라클 매뉴얼에는 아래 3가지로 분류된다.
- 인라인뷰(InlineView): FROM 절에 나타나는 서브쿼리를 의미한다.
- 중첩된 서브쿼리(NestedSubquery): 결과 집합을 한정하기 위해 WHERE 절에 사용된 서브쿼리를 의미한다. 특히, 서브쿼리가 메인 쿼리에 있는 컬럼을 참조하는 형태를 ‘상관관계 있는 서브쿼리’라고 부른다.
- 스칼라 서브쿼리(Scalar Subquery): 한 레코드당 정확히 하나의 컬럼값만을 반환하는 것이 특징이다. 주로 SELECT-list에서 사용되지만 몇 가지 예외 사항을 뺀다면 대부분의 위치에서 사용할 수 있다.
이들 서브쿼리를 참조하는 메인 쿼리도 하나의 쿼리 블록이며, 옵티마이저는 쿼리 블록 단위로 최적화를 수행한다. 즉, 쿼리 블록 단위로 최적의 액세스 경로와 조인 순서, 조인 방식을 선택하는 것이 목표이다.
그러나 각 서브쿼리를 최적화했다고 해서 쿼리 전체가 최적화됐다고 말할 수는 없다. 팀을 나눠 부문별로 작품을 만들 때, 각각은 최상이지만 전체적으로는 부조화 상태일 수 있는 것과 마찬가지이다. 옵티마이저가 숲을 바라보는 시각으로 쿼리를 이해하려면 먼저 서브쿼리를 풀어내야만 한다.
서브쿼리를 풀어내는 두 가지 쿼리 변환 중 서브쿼리 Unnesting은 중첩된 서브쿼리와 관련이 있고, 다음 절에서 설명하는 ‘뷰 Merging’은 인라인뷰와 관련이 있다. (뷰 Merging은 인라인뷰 뿐만 아니라 ‘저장된 뷰’에도 작용한다.)
(2) 서브쿼리 Unnesting의 의미
‘nest’의 사전적 의미를 찾아보면, “상자 등을 차곡차곡 포개넣다”라는 설명이 있다. 즉, ‘중첩’의 의미를 갖는다. 여기에 ‘부정’ 또는 ‘반대’ 의미가 있는 접두사 ‘un-‘을 붙인 unnest는 “중첩된 상태를 풀어낸다”는 뜻이 된다. 따라서 ‘서브쿼리 Unnesting은 중첩된 서브쿼리 Nested Subquery를 풀어내는 것을 말하며, 풀어내지 않고 그대로 두는 것은 ‘서브쿼리 No-Unnesting’이라고 말할 수 있다.
아래는 하나의 쿼리에서 서브쿼리가 이중삼중으로 중첩(nest)될 수 있음을 보여준다.’
1
2
3
4
5
6
7
8
9
select * from emp a where exists (
select 'x' from dept where deptno = a.deptno
and sal >
(select avg(sal) from emp b
where exists (
select 'x' from salgrade
where b.sal between losal and hisal
and grade = 4)
)
위 쿼리의 논리적인 포함 관계를 상자로 표현하면 그림 4-2와 같다.
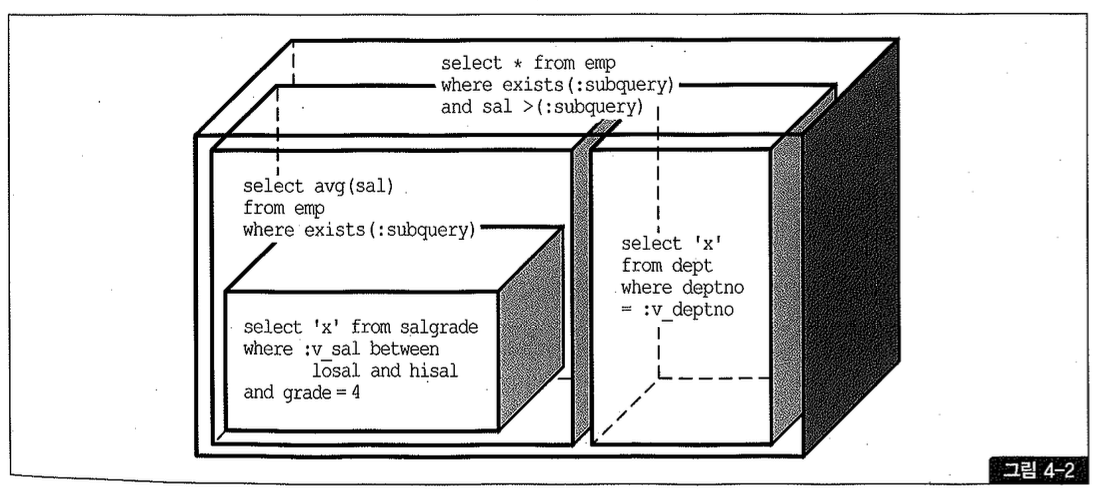
위 쿼리와 그림에서 알 수 있듯이, ‘중첩된 서브쿼리(nested subquery)’는 메인 쿼리와 부모와 자식이라는 종속적이고 계층적인 관계가 존재한다. 따라서 논리적인 관점에서 그 처리 과정은 IN, EXISTS를 불문하고 필터 방식이어야 한다. 즉, 메인 쿼리에서 읽히는 레코드마다 서브쿼리를 반복 수행하면서 조건에 맞지 않는 데이터를 골라내는 것이다.
하지만 서브쿼리를 처리하는 데 있어 필터 방식이 항상 최적의 수행 속도를 보장하지 못하므로 옵티마이저는 아래 둘 중 하나를 선택한다.
- 동일한 결과를 보장하는 조인 문으로 변환하고 나서 최적화한다. 이를 일컬어 ‘서브쿼리 Unnesting’이라고 한다.
- 서브쿼리를 Unnesting하지 않고 원래대로 둔 상태에서 최적화한다. 메인 쿼리와 서브쿼리를 별도의 서브플랜(Subplan)으로 구분해 각각 최적화를 수행하며, 이때 서브쿼리에 필터(Filter) 오퍼레이션이 나타난다.
1번 서브쿼리 Unnesting은 메인과 서브쿼리 간의 계층 구조를 풀어서 로 같은 레벨로 만들어 준다는 의미에서 ‘서브쿼리 Flattening’이라고도 불린다. 이렇게 쿼리 변환이 이루어지고 나면 일반 조인 문처럼 다양한 최적화 기법을 사용할 수 있게 된다.
2번처럼, Unnesting하지 않고 쿼리 블록별로 최적화할 때는 각각의 최적이 쿼리문 전체의 최적을 달성하지 못할 때가 많다. 그리고 Plan Generator가 고려 대상으로 삼을 만한 다양한 실행 계획을 생성해내는 작업이 매우 제한적인 범위 내에서만 이루어진다.
(3) 서브쿼리 Unnesting의 이점
서브쿼리Unnesting은 메인 쿼리와 같은 레벨로 풀어낸다면 다양한 액세스 경로와 조인 메소드를 평가할 수 있다. 특히 옵티마이저는 많은 조인 테크닉을 가지기 때문에 조인 형태로 변환했을 때 더 나은 실행 계획을 찾을 가능성이 높아진다.
이런 이점 때문에 옵티마이저는 서브쿼리 Unnesting을 선호한다. 그래서 오라클9i에서는 정확히 같은 결과집합임이 보장된다면 무조건 서브쿼리를 Unnesting 하려고 시도한다. 즉, 휴리스틱 쿼리 변환 방식으로 작동한다.
10g부터는 서브쿼리Unnesting이 비용기반 쿼리 변환 방식으로 전환되었다. 따라서 변환된 쿼리의 예상 비용이 더 낮을 때만 Unnesting된 버전을 사용하고, 그렇지 않을 때는 원본 쿼리 그대로 필터 방식으로 최적화한다.
서브쿼리Unnesting과 관련한 힌트로는 아래 두 가지가 있다.
- unnest: 서브쿼리를 Unnesting함으로써 조인 방식으로 최적화하도록 유도한다.
- no_unnest: 서브쿼리를 그대로 둔 상태에서 필터 방식으로 최적화하도록 유도한다.
(4) 서브쿼리 Unnesting 기본 예시
실제 서브쿼리Unnesting이 어떻게 작동하는지 살펴보자. 아래처럼 IN 서브쿼리를 포함하는 SQL문이 있다.
1
2
select * from emp
where deptno in (select deptno from dept)
이 SQL문을 Unnesting하지 않고 그대로 최적화하면 옵티마이저는 필터 방식의 실행 계획을 수립한다.
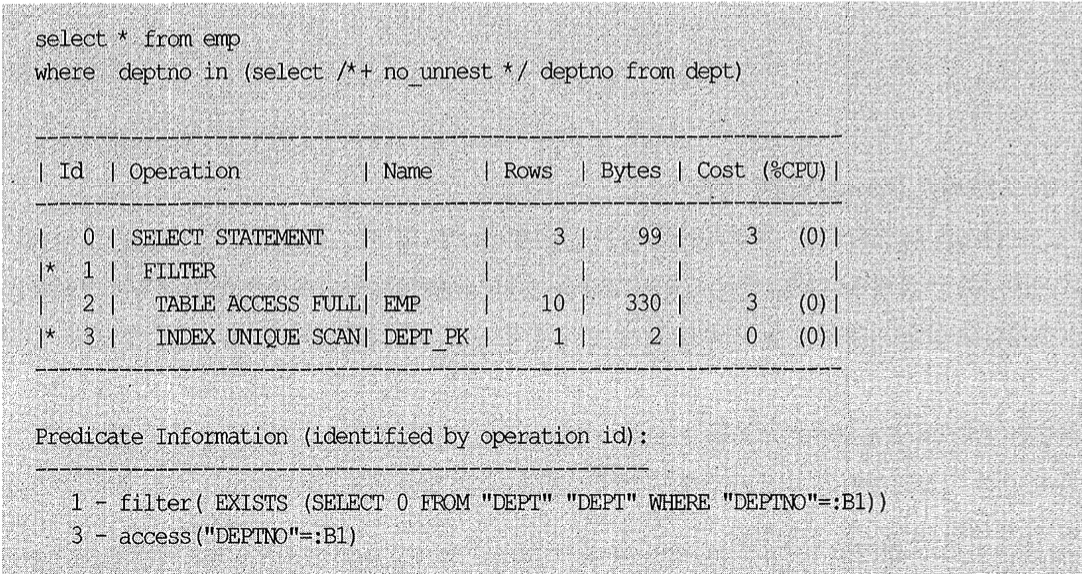
옵티마이저가 서브쿼리Unnesting을 선호하므로 이를 방지하려고 no_unnest 힌트를 사용해 실행 계획을 유도하였다. Predicate 정보를 보면 필터 방식으로 수행된 서브쿼리의 조건절이 바인드 변수로 처리된 부분이 눈에 띄는데, 이것을 통해 옵티마이저가 서브쿼리를 별도의 서브플랜(Subplan)으로 최적화한다는 사실을 알 수 있다.
이처럼, Unnesting하지 않은 서브쿼리를 수행할 때는 메인 쿼리에서 읽히는 레코드마다 값을 넘기면서 서브쿼리를 반복 수행한다. (Unnesting하지 않았지만 내부적으로 IN 서브쿼리를 EXISTS 서브쿼리로 변환한다는 사실도 Predicate 정보를 통해 알 수 있다.)
Unnest 힌트를 사용하거나 옵티마이저가 스스로 Unnesting을 선택한다면, 변환된 쿼리는 다음과 같은 조인 문 형태가 된다. (사용자가 발행한 SQL 텍스트를 변환하는 것은 아니며, 파서(Parser)에 의해 생성된 파싱트리 내에서 변환한다.)
1
2
3
select *
from (select deptno from dept) a, emp b
where b.deptno - a.deptno
그리고 이것은 다시 다음절에서 설명하는 뷰 Merging 과정을 거쳐 최종적으로 아래와 같은 형태가 된다.
1
2
select emo.* from dept, emo
where emp.deptno - dept.deptno
(5) Unnesting된 쿼리의 조인 순서 조정
여기서 주목할 점은, Unnesting에 의해 일반 조인문으로 변환된 후에는 emp, dept 어느 쪽이 드라이빙 집합으로 선택될 수 있다는 사실이다. 선택은 옵티마이저의 몫이며, 판단 근거는 데이터 분포를 포함한 통계 정보에 있다.
서브쿼리가 M쪽 집합이거나 Nonunique 인덱스일 때, 옵티마이저는 두 가지 방식 중 하나를 선택한다. Unnesting 후 어느 쪽 집합이 먼저 드라이빙되느냐에 따라 달라진다. Unnesting 후 어느 쪽 집합이 먼저 드라이빙되느냐에 따라 달라진다. Sort Unique 오퍼레이션을 수행하거나 세미 조인 방식으로 조인한다. Sort Unique 오퍼레이션을 수행하거나 세미 조인 방식으로 조인한다. Unnesting된 쿼리를 세미 조인으로 변환할 때의 장점은, NL 세미 조인뿐만 아니라 해시 세미 조인, 소트머지 세미 조인도 가능하다는데에 있다. 사용자가 직접 유도할 때는 unnest 힌트와 함께 각각 hash_sj, merge_sj 힌트를 사용하면 된다.
(6) 서브쿼리가 M쪽 집합이거나 Nonunique 인덱스일 때
현재까지 본 예제는 메인 쿼리의 emp 테이블과 서브쿼리의 dept 테이블이 M:1 관계이기 때문에 일반 조인문으로 바꾸더라도 쿼리 결과가 보장된다. 옵티마이저는 dept 테이블의 deptno 컬럼에 PK 제약이 설정된 것을 통해 dept 테이블이 1쪽 집합이라는 사실을 알 수 있다. 따라서 안심하고 쿼리 변환을 실시한다.
하지만 dept 테이블의 deptno 컬럼에 PK/Unique 제약 또는 Unique 인덱스가 없다면 옵티마이저는 emp와 dept 간의 관계를 알 수 없고, 결과를 확신할 수 없으니 일반 조인문으로의 쿼리 변환을 시도하지 않는다. (만약 SQL 튜닝 차원에서 위쿼리를 사용자가 직접 조인문으로 바꿨는데, 어느 순간 dept 테이블 deptno 컬럼에 중복값이 입력되면서 결과에 오류가 생기더라도 옵티마이저에게는 책임이 없다.)
이럴 때 옵티마이저는 두 가지 방식 중 하나를 선택하는데, Unnesting 후 어느 쪽 집합이 먼저 드라이빙되느냐에 따라 달라진다.
- 1쪽 집합임을 확신할 수 없는 서브쿼리 쪽 테이블이 드라이빙된다면, 먼저 Sort Unique 오퍼레이션을 수행함으로써 1쪽 집합으로 만든 다음에 조인한다.
- 메인 쿼리 쪽 테이블이 드라이빙된다면 세미조인(SemiJoin) 방식으로 조인한다. 이것이 세미조인(Semi Join)이 탄생하게 된 배경이다.
Sort Unique 오퍼레이션 수행
dept 테이블에서 PK 제약을 제거하고, deptno 컬럼에 Nonunique 인덱스를 생성한 후 실행 계획을 다시 확인해보자 (스크립트 ch4_03.t 참조).
실제로 dept 테이블은 Unique한 집합이지만 옵티마이저는 이를 확신할 수 없어 Sort Unique 오퍼레이션을 수행하였다.
세미조인 방식으로 수행
NL 세미조인으로 수행할 때는 Sort Unique 오퍼레이션을 수행하지 않고도 결과 집합이 M쪽 집합으로 확장되는 것을 방지하는 알고리즘을 사용한다. 기본적으로 NL조인과 동일한 프로세스로 진행하지만, Outer=Driving) 테이블의 한 로우가 Inner 테이블의 한 로우와 조인에 성공하는 순간 진행을 멈추고 Outer 테이블의 다음 로우를 계속 처리하는 방식이다.
세미조인 방식으로 변환할 때의 장점은, NL 세미조인 뿐만 아니라 해시 세미조인, 소트 머지 세미조인도 가능하다는데에 있다. 사용자가 직접 유도할 때는 unnest 힌트와 함께 각각 hash_sj, merge_sj 힌트를 사용하면 된다.
(7) 필터 오퍼레이션과 세미조인의 캐싱 효과
옵티마이저가 쿼리 변환을 수행하는 이유는, 전체적인 시각에서 더 나은 실행 계획을 수립할 가능성을 높이는 데에 있다. 서브쿼리를 Unnesting해 조인문으로 바꾸고나면 NL조인은 물론 해시 조인, 소트 머지 조인 방식을 선택할 수 있고, 조인 순서도 자유롭게 선택할 수 있음을 앞에서 살펴보았다.
서브쿼리를 Unnesting하지 않으면 쿼리를 최적화하는 데 있어 선택의 폭이 넓지 않아 불리하다. 메인 쿼리를 수행하면서 건건이 서브쿼리를 반복 수행하는 단순한 필터 오퍼레이션을 사용할 수밖에 없기 때문이다. 대량의 집합을 기준으로 이처럼 Random 액세스 방식으로 서브쿼리 집합을 필터링한다면 결코 빠른 수행 속도를 얻을 수 없다.
다행히 오라클은 필터 최적화 기법을 한 가지 갖고 있는데, 서브쿼리 수행 결과를 버리지 않고 내부 캐시에 저장하고 있다가 같은 값이 입력되면 저장된 값으로 출력하는 방식이다. 2장 6절에서 스칼라 서브쿼리의 캐싱 효과를 설명했는데, 그것과 같다.
조나단 루이스 설명에 의하면, 오라클은 8i와 9i에서 256개, 10g에서 1,024개 해시 엔트리를 캐싱한다고 한다. 테스트 결과를 기반으로 추측된 값이라고도 밝혔다. 실제 캐싱할 수 있는 엔트리 개수가 몇 개이건 간에 브쿼리와 조인되는 컬럼의 Distinct Value 개수가 캐시 상한선을 초과하지만 않는다면 필터 오퍼레이션은 매우 효과적인 수행 방식일 것이다.
(8) Anti 조인
not exists, not in 서브쿼리도 Unnesting하지 않으면 아래와 같이 필터 방식으로 처리된다.

기본 처리 루틴은 exists 필터와 동일하며, 조인에 성공하는 레코드가 하나도 없을 때만 결과 집합에 포함시킨다는 점이 다르다.
- exists 필터: 조인에 성공하는 (서브) 레코드를 만나는 순간 결과 집합에 담고 다른 (메인) 레코드로 이동한다.
- not exists 필터: 조인에 성공하는 (서브) 레코드를 만나는 순간 버리고 다음 (메인) 레코드로 이동한다. 조인에 성공하는 (서브) 레코드가 하나도 없을 때만 결과 집합에 담는다.
똑같은 쿼리를 Unnesting 하면 아래와 같이 Anti 조인 방식으로 처리된다.
NL Anti 조인과 머지 Anti 조인은 기본 처리 루틴이 not exists 필터와 같지만, 해시 Anti 조인 온조금다르다. 해시 Anti 조인으로 수행할 때는, 먼저 dept를 해시 테이블로 빌드한다. emp를 스캔하면서 해시 테이블을 탐색하고, 조인에 성공한 엔트리에만 표시를 한다. 마지막으로, 해시 테이블을 스캔하면서 표시가 없는 엔트리만 결과 집합에 담는 방식이다.
(9) 집계 서브쿼리 제거
집계함수를 포함하는 서브쿼리를 Unnesting하고, 이를 다시 분석 함수로 대체하는 쿼리 변환이 10g에서 도입되었다.
10g부터 옵티마이저가 선택할 수 있는 옵션이 한 가지 더 추가되었는데, 서브쿼리로부터 전환된 인라인뷰를 제거하고 아래와 같이 메인쿼리에 분석함수를 사용하는 형태로 변환하는 것이다. 이 기능은 _remove_aggr_subquery 파라미터에 의해 해제되며 비용 기반으로 작동한다.
(10) Pushing 서브쿼리
앞에서 설명한 것처럼 Unnesting되지 않은 서브쿼리는 항상 필터 방식으로 처리되며, 대개 실행 계획 상에서 마지막 단계에 처리된다. 만약 서브쿼리 필터링을 먼저 처리했을 때 다음 단계로 넘어가는 행 주를 크게 줄일 수 있다면 성능은 그만큼 향상된다. Pushing 서브쿼리는 이처럼 실행 계획 상 가능한 앞단계에서 서브쿼리 필터링이 처리되도록 강제하는 것을 말하며, 이를 제어하기 위해 사용하는 옵티마이저 힌트가 push_subq이다.
Pushing 서브쿼리는 Unnesting되지 않은 서브쿼리에만 작동한다는 사실을 기억할 필요가 있다. 따라서 push_subq 힌트는 항상 no_unnest 힌트와 같이 기술하는 것이 올바른 사용법이다. 만약 옵티마이저가 서브쿼리를 Unnesting하기로 결정한다면 push_subq 힌트는 무용지물이 되기 때문이다.
push_subq 힌트가 잘 작동하지 않는다는 질문을 종종 받는데, 대개 no_unnest 힌트를 같이 사용하지 않은 경우였다. 그리고 9i와 10g 사이에 push_subq 힌트를 기술하는 위치가 바뀐 것에도 기인한다.
서브쿼리가 여러 개 일때 push_subq 힌트를 서브쿼리에 직접 기술해야 세밀한 제어가 가능하므로 10g에서 바뀐 것이다.
서브쿼리가 조인으로 풀릴 때 서브쿼리에서 참조하는 테이블이 먼저 드라이빙되도록 제어할 목적으로 push_subq 힌트를 사용한다고 잘못 알고 있는 분들을 자주 만난다. 서브쿼리가 조인으로 풀린다는 것은 Unnesting되었다는 뜻인데, 다시 말하지만 Pushing 서브쿼리는 Unnesting되지 않은 서브쿼리의 처리 순서를 제어하는 기능이다. Unnesting된 서브쿼리의 조인 순서를 조정하는 방법에 대해서는 앞에서(5항) 이미 살펴보았다.