<오라클 성능 고도화 원리와 해법2> Ch04-05 조건절 이행
오라클 성능 고도화 원리와 해법2 - Ch04-05 조건절 이행
‘조건절이행(Transitive Predicate Generation, Transtive Closure)’이라고 불리는 이 쿼리 변환을 한마디로 요약하면, “A=B이고(B=C)이면(A=C)이다”는 추론을 통해 새로운 조건을 내부적으로 생성해 주는 쿼리 변환이다. “A>B이고(B>C)이면(A>C)이다”와 같은 추론도 가능하다.
예를들어, A테이블에 사용된 필터조건이 조인조건을 타고 반대편 B테이블에 대한 필터조건으로 이행(주)될 수 있다. 한 테이블 내에서도 두 컬럼 간 관계정보(예를들어,col1=col2)를 이용해 조건절이 이행된다.
1
2
3
4
select * from dept d, emp e
where e.job = 'MANAGER'
and e.deptno = 10
and d.deptno = e.deptno
위 쿼리에서 deptno=10은 emp테이블에 대한 필터조건이다(스크립트ch4.17kt참조). 하지만 아래 실행계획에 나타나는 Predicate 정보를 확인해보면, dept테이블에도 같은 필터조건이 추가된 것을 볼 수 있다.
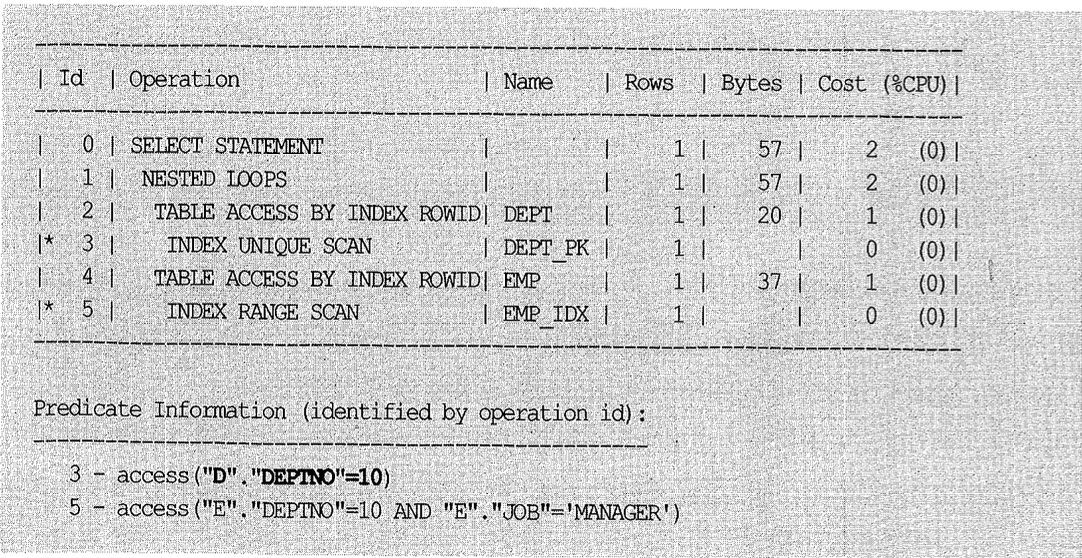
“e.deptno=10” 이고 “e.deptno=d.deptno”이므로 “d.deptno=10”으로 추론된 것이다. 이런 조건이 행(transitive)을 통해 쿼리가 아래와 같은 형태로 변환된 것이다.
1
2
3
4
select * from dept d, emp e
where e.job = 'MANAGER'
and e.deptno = 10
and d.deptno = 10
위와 같이 변환한다면, 해시조인 또는 소트머지조인을 수행하기 전에 emp와 dept테이블에 각 필터링을 적용함으로써 조인되는 데이터량을 줄일 수 있다. 그리고 dept테이블 액세스를 위한 인덱스 사용을 추가로 고려할 수 있게되어 더 나은 실행계획을 수립할 가능성이 커진다.
참고로, 새로운 필터조건이 추가되면서 기존에 있던 e.deptno=d.deptno 조인조건이 제거된 것을 눈여겨볼 필요가 있다. 이는 쿼리 수행시 예상비용을 더 정확히 계산하기 위해 행해진 조치다. 필터 또는 조인조건이 하나씩 추가될 때마다 카디널리티 예상치가 감소하고 그만큼 전체 쿼리 수행비용도 낮게 평가된다는 뜻이다. 그런데 “e.deptno=d.deptno”과 “d.deptno=10”은 같은 조건식으로 봐야 하므로 이를 비용 계산식에 중복산정하는 것을 방지하기 위해 옵티마이저가 그렇게 처리하는 것이다. 9i에서는 사용자가 의도적으로 e.deptno=d.deptno 조인문을 한번 더 기술하면 이 조인문이 다시 나타났는데, 10g부터는 아무리 여러번 기술하더라도 그런 현상이 생기지 않는다.
만약 조건절이 행이 작용해 조인조건이 사라지고 이로 인해 비용이 잘못 계산되는 문제가 생긴다면, 사용자가 명시적으로 d.deptno=10 조건을 추가하거나 조인문을 아래와 같이 가공하는 방법을 사용해볼 수 있다.
1
2
3
4
select * from dept d, emp e
where e.job = 'MANAGER'
and e.deptno = 10
and d.deptno = e.deptno + 0
그러면 조건절이 사라지지 않고 그대로 남게되며, 계산된 비용도 달라진다.
조건 이행이 효과를 발휘하는 사례
사실 우리가 주의깊게 관찰하지 않아서 그렇지 내부적으로 조건 이행이 여러 곳에서 일어나고 있으며, 아래가 좋은 사례가 될 것이다.
1
2
3
4
5
select *
from 상품이력 a, 주문 b
where b.거래일자 between '20090101' and '20090131'
and a.상품번호 = b.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
2009년 1월 1일부터 1월 31일까지의 주문 데이터를 조회하면서 선분 이력으로 설계된 상품 이력 테이블을 Between 조건으로 조인하는 쿼리다. 1절과 2절에서 자세히 설명했듯이 선분 이력을 Between 조건으로 조회할 때는 인덱스 구성과 검색 범위에 따라 인덱스 스캔 효율에 많은 차이가 생긴다. 따라서 가급적 검색 범위를 제한해주는 것이 도움이 되는데, 위 쿼리에서는 검색 범위가 주문 테이블에만 주어졌다. 하지만 조건을 잘 분석해보면 선분 이력 조건인 “b.거래일자 between a.시작일자 and a.종료일자”에 도 범위를 더 제한적으로 줄일 수 있는 방법이 있다.
그림 4-3처럼 A, B, C, D, E 5개 상품 이력이 있다고 하자. 각 상품이 등록된 시점이 다르고, 속성이 바뀌어 이력 레코드가 쌓인 시점도 다르다.
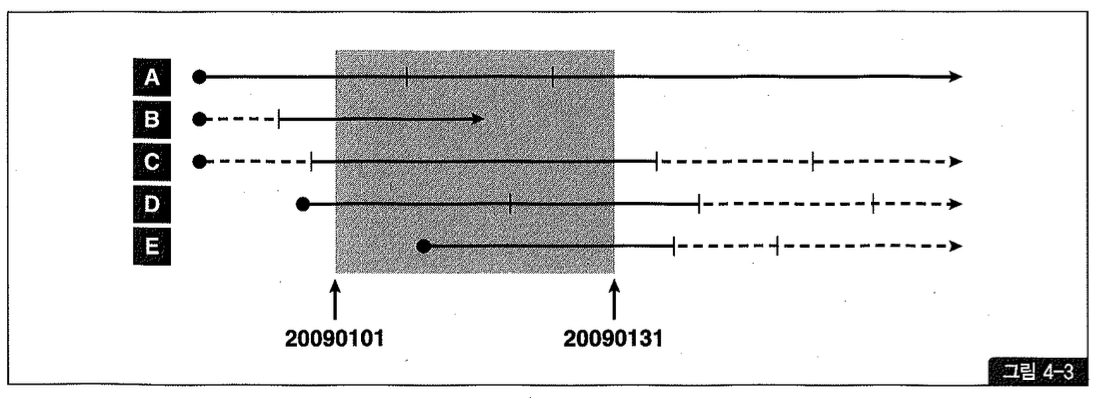
현재 사용자가 수행하고자 하는 쿼리는 2009년 1월 1일부터 1월 31일 사이에 발생한 주문 데이터만 조회하는 것이므로 상품 이력에서도 그 기간에 해당하는 이력 레코드만 읽으면 된다. 그림 4-3에서 사각형 박스 안에 걸쳐 있는 이력 레코드(실선으로 표시함)가 여기에 해당한다.
이 구간에 속하는 이력 레코드의 공통점은, 시작일자가 ‘20090131’ 보다 작고, 종료일자 ‘20090101’ 보다 크다는 것이다. 따라서 이 조건절을 명시적으로 넣어주면 상품 이력에서 읽는데 이터량을 줄일 수 있다.
• 상품이력.시작일자 >= ‘20090131’ • 상품이력.종료일자 >= ‘20090101’
그림 4-3을 보면 이 조건을 추가하더라도 A 상품은 3개 이력 레코드를 다 읽지만, 나머지 상품은 일부만 읽으면 되는 것을 알 수 있다.
실제로 예전에는 이런 조건절을 명시적으로 추가해줌으로써 SQL을 튜닝하곤했다. 하지만 9i 부터는 옵티마이저가 이들 조건을 묵시적으로 추가하고 최적화를 수행한다.
튜닝 사례 1
우선 IP 주소 목록 테이블에 ‘종료 IP 주소’ 컬럼을 추가하는 방안을 고려할 수 있다. 이 쿼리를 32분(= 1922초) 씩 걸리게 만든 핵심 부하 요인이 과도한 테이블 Random 액세스에 있으므로 종료 IP 주소 조건을 인덱스에서 필터링하는 것만으로도 상당한 성능 개선 효과가 있을 것이다.
그런데 인덱스를 스캔하는 과정에서 이미 31,980개 I/O가 발생하였고, 여기에 ‘종료 IP 주소’ 컬럼까지 추가하면(크기가 증가하므로) 스캔량은 더 늘어날 것이다. 게다가 사용자가 바인드값을 아래와 같이 입력한다면 인덱스 스캔량 자체도 무시 못할 정도로 늘어난다.
1
2
:startIpAddr := '001.001.001.001'
:endIpAddr := '001.001.001.255'
어떻게 튜닝할 수 있을까? 옵티마이저는 모르고 우리만 아는 정보가 한 가지 있다. IP 주소 목록 테이블에 입력된 종료 IP 주소가 시작 IP 주소보다 크다는 사실(각 IP 주소가 속한 서브넷 범위 정보이므로)이다. 이 정보를 추가해주면 인덱스 스캔량을 획기적으로 줄일 수 있다.
1
2
3
4
5
SELECT ...
FROM IP 주소 목록
WHERE 시작IP주소 >= :strtipAddr ........ 1
AND 종료IP주소 <= :endipaddr ........ 2
AND 시작IP주소 <= 종료IP주소 ........ 3
여기서 주목할 점이 있다. 위와 같이 직접 between으로 풀어서 기술할 필요 없이 ‘종료 IP 주소’ 가 ‘시작 IP 주소’ 보다 크다는 사실만 옵티마이저에게 알려줘도 된다는 사실이다. 그러면 우리가 유추해낸 것과 같은 조건절을 옵티마이저가 내부적으로 생성해낸다.
옵티마이저에게 많은 정보를 제공할수록 SQL 성능이 더 좋아짐을 알 수 있는 좋은 사례라고 하겠다.
튜닝 사례 2
지금 설명할 내용도 우리가 흔히 접하는 튜닝 사례 중 하나다. 데이터 모델은 그림 4-4와 같다.

고객 번호에 대한 두 조인 조건식을 잘 따져보면, 고객과 주문 상세가 연결되었고, 주문과 주문 상세도 연결되었다. 그런데 NL 조인 순서는 ordered 힌트에 따라 고객 - 주문 - 주문 상세 순으로 결정된다. 따라서 고객과 주문을 먼저 조인하는 단계에서는 고객 번호를 연결 조건으로 사용하지 못하는 문제가 생긴다.
아래 Predicate 정보 ①에서, 고객 번호에 대한 조인 조건식은 없고 주문 상세 테이블 조건으로부터 전이된 주문 일자 조건만 있는 것을 확인하기 바란다. 고객 테이블 고객 번호에 대한 조인은 주문 상세 PK 인덱스를 액세스하는 단계에서 모두 이루어지고 있다.
1
2
3
4
5
① access(O.주문일자=TO_CHAR(SYSDATE@!,'YYYYMMDD'))
② access(D.주문일자=TO_CHAR(SYSDATE@!,'YYYYMMDD')) AND
D.고객번호=O.고객번호 AND D.주문번호=O.주문번호
filter(D.고객번호=C.고객번호)
이 때문에 주문 테이블과 조인하고 나서 9,000개나 더 많은 레코드가 출력되었고, 그만큼 주문 상세 PK 인덱스를 여러 번 탐색하면서 10,000개가량의 블록/IO도 추가로 발생했다.
만약 아래처럼 사용자가 기술한 ①②번 조인문을 통해 내부적으로 ③번 조인문이 생성되었다면 위와 같은 문제는 발생하지 않았을 것이다.
1
2
3
4
where d.고객번호 = c.고객번호 ........ ①
and d.고객번호 = o.고객번호 ........ ②
and o.고객번호 = c.고객번호 ........ ③
이처럼 조인 조건은 상수와 변수 조건처럼 전이되지 않으므로 최적의 조인 순서를 결정하고 그 순서에 따라 조인문을 기술해주는 것이 매우 중요하다.