<오라클 성능 고도화 원리와 해법2> Ch05-01 소트 수행 원리
SQL 튜닝에서 빠질 수 없는 요소가 소트 튜닝이다. 소트 오퍼레이션은 수행 과정에서 CPU와 메모리를 많이 사용하고, 데이터량이 많을 때는 디스크 I/O까지 일으킨다. 많은 서버 리소스를 사용하는 것도 문제지만 부분범위 처리를 불가능하게 해 OLTP 환경에서 애플리케이션 성능을 저하시키는 주요인으로 작용하기도 한다.
오라클 성능 고도화 원리와 해법2 - Ch05-01 소트 수행 원리
(1) 소트 수행 과정
SQL 수행 도중 데이터 정렬이 필요할 때면 오라클은 PGA 메모리에 Sort Area를 할당하는데, 그 안에서 처리를 완료할 수 있는 지 여부에 따라 소트를 두 가지 유형으로 나눈다.
- 메모리 소트 (in-memory sort): 전체 데이터의 정렬 작업을 메모리 내에서 완료하는 것을 말하며, Internal Sort라고도 한다.
- 디스크 소트 (o-disk sort): 할당받은 Sort Area 내에서 정렬을 완료하지 못해 디스크 공간까지 사용하는 경우를 말하며, External Sort라고도 한다.
그림 5-1은 디스크 소트 과정을 표현한 것이다.
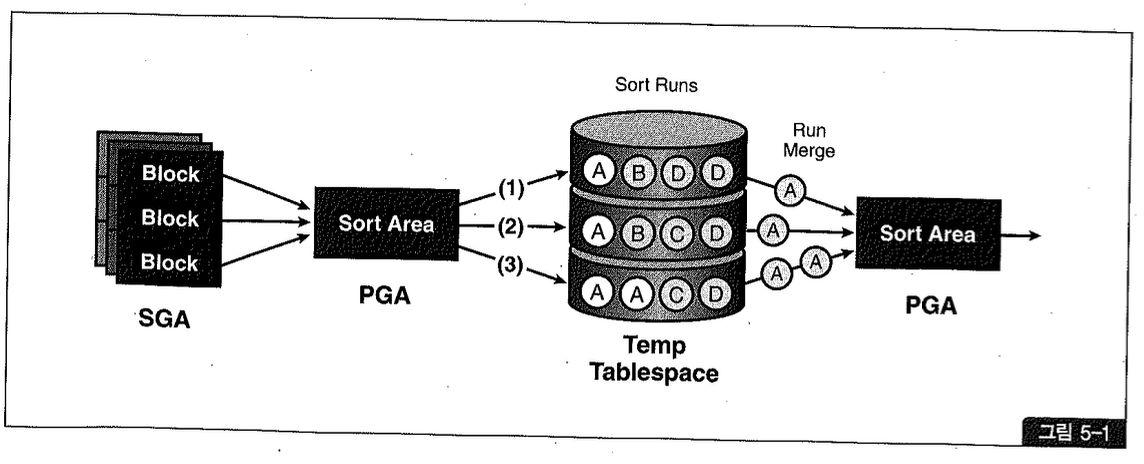
Sort Area 내에서 데이터 정렬을 마무리하는 것이 최적이지만 (-optimal 소트), 양이 많을 때는 정렬된 중간 결과 집합을 Temp 테이블 스페이스의 Temp 세그먼트에 임시 저장한다. Sort Area가 찰 때마다 Temp 영역에 저장해둔 중간 계산 결과를 Sort Run이라고 부른다. 그림 5-1에서 표현하고 있는 것처럼 Sort Run 생성을 마쳤으면, 이를 다시 Merge해야 정렬된 최종 결과 집합을 얻게 된다.
이처럼, 정렬된 결과를 Temp 영역에 임시 저장했다가 다시 읽어들이는 디스크 소트가 발생하는 순간 SQL 수행 성능은 크게 나빠진다. Sort Area가 각 Sort Run으로 분할되나의 청크(Chunk)씩 읽어들이는 정도가 되면 추가적인 디스크 I/O가 발생하지 않아 그나마 낫다 (one pass 소트). 만약 그 정도의 크기도 못된다면 Sort Run으로부터 읽은 데이터를 다시 디스크에 썼다가 읽어들이는 과정을 여러번 반복하게 되므로 성능은 극도로 나빠진다 (multipass 소트).
- Optimal 소트: 소트 오퍼레이션이 메모리 내에서만 이루어짐
- Onepass 소트: 정렬 대상 집합이 디스크에 한 번만 쓰임
- Multipass 소트: 정렬 대상 집합이 디스크에 여러 번 쓰임
(2) 소트 오퍼레이션 측정
소트 오퍼레이션이 AutoTrace에서 어떻게 측정되는지 살펴보자 (스크립트 Ch5_01.0t 참조).
1
2
3
4
5
6
7
8
SQL> create table t_emp
2 as
3 select *
4 from emp, (select rownum no from dual connect by level <= 100000);
SQL> alter session set workarea_size_policy = manual;
SQL> alter session set sort_area_size = 1048576;
1권 6강에서도 설명했듯이 소트 과정에서 발생하는 디스크 I/O는 Direct Path I/O 방식을 사용하므로 버퍼 캐시를 경유하는 일반적인 디스크 I/O에 비해 무척 가볍다.
(3) Sort Area
데이터 정렬을 위해 사용되는 Sort Area는 소트 오퍼레이션이 진행되는 동안 공간이 부족해질 때마다 청크(Chunk) 단위(예를 들어, block size 파라미터로 결정)로 조금씩 할당된다. 세션마다 사용할 수 있는 최대 크기를 예전에는 sort_area_size 파라미터로 설정하였으나, 9i부터는 새로운 workarea_size_policy 파라미터를 auto(기본값 설정하면 오라클이 내부적으로 결정한다. 자세한 설명은 7절을 참조하길 바란다.)
| SORT_AREA_RETAINED_SIZE |
|---|
| Sort area_retained_size는 데이터를 정렬을 끝내고 나서 결과 집합을 모두 Fetch 할 때까지(또는 쿼리의 다음 수행 단계로 모두 전달할 때까지 유지할 Sort Area 크기를 지정한다. 이 크기를 초과한 데이터는 Temp 세그먼트에 저장했다가 Fetch 과정에서 다시 읽어들인다. 따라서 sort_area_size가 충분히 커서 메모리 소트 방식으로 처리했더라도 이 파라미터가 정렬된 결과 집합보다 작다면 디스크 I/O가 발생한다. 참고로, 0으로 설정하면 정렬 후 곧바로 Sort Area를 모두 해제하겠다는 의미로 이해하기쉽지만, 그와는 반대로 Fetch가 완료될 때까지 Sort Area 크기를 그대로 유지하겠다는 의미다. |
그럼 Sort Area는 어떤 메모리 영역에 할당될까? 이를 이해하려면 먼저 PGA, UGA, SGA 개념을 알아야만 한다.
PGA
각 오라클 서버 프로세스는 자신만의 PGA(Process/Program/Private Global Area) 메모리 영역을 할당 받고, 이를 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용한다. PGA는 다른 프로세스와 공유되지 않는 독립적인 메모리 공간으로서, 래치 메커니즘이 필요 없어 똑같은 개수의 블록을 읽더라도 SGA 버퍼 캐시에서 읽는 것보다 훨씬 빠르다.
UGA
전용 서버(Dedicated Server) 방식으로 연결할 때는 프로세스와 세션이 1:1 관계를 갖지만, 공유 서버(Shared Server 또는 MTS) 방식으로 연결할 때는 1:N 관계를 갖는다. 즉, 세션이 프로세스 개수보다 많아질 수 있는 구조로서, 하나의 프로세스가 여러 개 세션을 위해 일한다. 따라서 각 세션을 위한 독립적인 메모리 공간이 필요해지는데, 이를 ‘UGA(User Global Area)’라고 한다.
오라클이 UGA를 사용하게 된 배경을 설명했는데, 그렇다고 전용 서버 방식에서 UGA를 사용하지 않는 것은 아니다. UGA는 서버 프로세스와의 연결 방식에 따라 위치가 달라지는데, 전용 서버 방식으로 연결할 때는 PGA에, 공유 서버 방식으로 연결할 때는 SGA에 할당된다. 후자 방식에서는 구체적으로, Large Pool이 설정됐을 때는 Large Pool에, 그렇지 않을 때는 Shared Pool에 할당된다.
그림 5-2는 방금 설명한 프로세스, 세션, PGA, UGA, SGA의 관계를 쉽게 이해할 수 있도록 ERD로 표현해본 것이다.
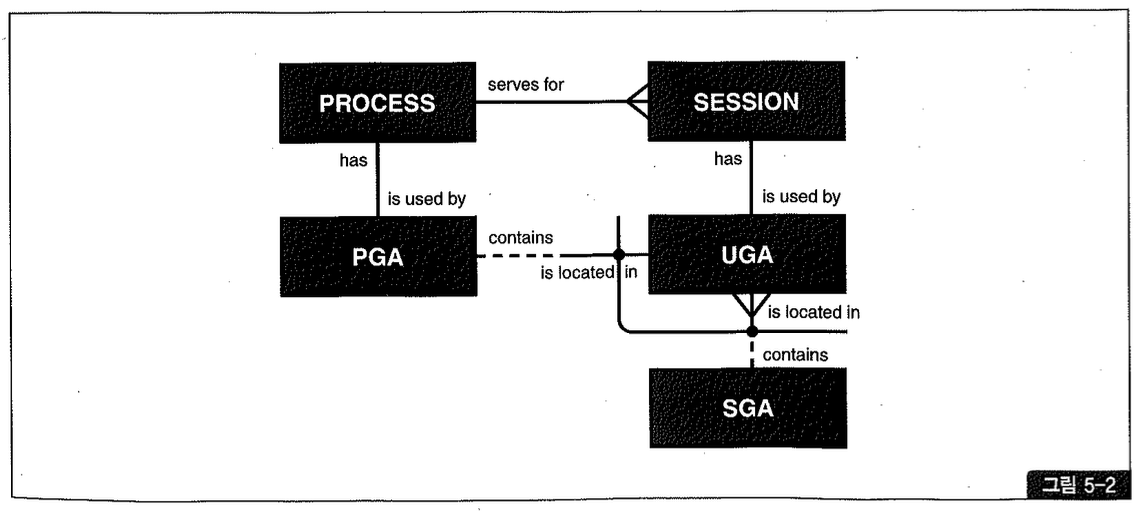
기억해야할 주요 사항만 요약해보자.
- 하나의 프로세스는 하나의 PGA를 갖는다.
- 하나의 세션은 하나의 UGA를 갖는다.
- PGA에는 세션과 독립적인 프로세스만의 정보를 관리한다.
- UGA에는 프로세스와 독립적인 세션만의 정보를 관리한다.
- 거의 대부분 전용 서버 방식을 사용하므로 세션과 프로세스는 1:1 관계고, 따라서 UGA도 PGA 내에 할당된다고 이해하면 쉽다.
CGA
PGA에 할당되는 메모리 공간으로는 CGA(Call Global Area)도 있다. 오라클은 하나의 데이터베이스 Call을 넘어서 다음 Call까지 계속 참조되어야 하는 정보는 UGA에 담고, Call이 진행되는 동안에만 필요한 데이터는 CGA에 담는다. CGA는 Parse Call, Execute Call, Fetch Call마다 매 번 할당받는다. Call이 진행되는 동안 Recursive Call이 발생하면 그 안에서도 Parse, Execute, Fetch 단계별로 CCA가 추가로 할당된다. CGA에 할당된 공간은 하나의 Call이 끝나자마자 해제돼 PGA로 반환된다.
- CGA: Call이 진행되는 동안만 필요한 정보 저장
- UGA: Call을 넘어서 다음 Call까지 계속 참조되는 정보 저장
Sort Area 할당 위치
이제 Sort Area가 어디에 할당되는지 설명할 준비가 되었다. 결론부터 말하면, Sort Area가 할당되는 위치는 SQL 문 종류와 소트 수행 단계에 따라 다르다.
DML 문장은 하나의 Execute Call 내에서 모든 데이터 처리를 완료하며, Execute Call이 끝나는 순간 자동으로 커서가 닫힌다. 따라서 DML 수행 도중 정렬한 데이터를 Call을 넘어서까지 참조할 필요가 없으므로 Sort Area를 CGA에 할당한다.
SELECT 문에서의 데이터 정렬은 상황에 따라 다르다. SELECT 문장이 수행되는 가장 마지막 단계에서 정렬된 데이터는 계속 이어지는 Fetch Call에서 사용되어야 한다. 따라서 sort_area_retained_size 제약이 없다면(0 또는 Sort area size와 같은 값이면) 그 마지막 소트를 위한 Sort Area는 UGA에 할당한다. 반면 마지막보다 앞선 단계에서 정렬된 데이터는 첫 번째 Fetch Call 내에서만 사용되므로 Sort Area를 CGA에 할당한다.
지금까지 설명한 내용을 요약하면 다음과 같다.
- DML 문장 수행 시 발생하는 소트는 CGA에서 수행
- SELECT 문장 수행 시
- (1) 쿼리 중간 단계의 소트
- CGA에서 수행. sort_area_retained_size 제약이 있다면 다음 단계로 넘어가기 전에 이 값을 초과하는 CGA 영역을 반환
- (2) 결과 집합을 출력하기 직전 단계에서 수행하는 소트
- ① sort_area_retained_size 제약이 있으면, CGA에서 소트 수행.
- 이 제약만큼의 UGA를 할당해 정렬된 결과를 담았다가 이후 Fetch Call에서 Array 단위로 전송
- ② sort_area_retained_size 제약이 없으면, 곧바로 UGA에서 소트 수행
- ① sort_area_retained_size 제약이 있으면, CGA에서 소트 수행.
- (1) 쿼리 중간 단계의 소트
CCA에 할당된 Sort Area는 하나의 Call이 끝나자마자 PGA에 반환된다. UGA에 할당된 Sort Area는 마지막 로우가 Fetch될 때 비로소 UCA Heap에 반환되고, 거의 대부분 그 부모 Heap(전용 서버 방식에서는 PGA, 공유 서버 방식에서는 SGA)에도 즉각 반환된다.
(4) 소트 튜닝 요약
소트 오퍼레이션은 메모리 집약적일뿐만 아니라 CPU 집약적인데다가, 데이터량이 많을 때는 디스크 I/O까지 발생시키므로 쿼리 성능을 좌우하는 가장 중요한 요소다. 특히, 부분 범위 처리를 할 수 없게 만들어 OLTP 환경에서 성능을 떨어뜨리는 주요한 요인으로 작용한다. 따라서 될 수 있으면 소트가 발생하지 않도록 SQL을 작성해야하고, 소트가 불가피하다면 메모리 내에서 수행을 완료할 수 있도록 해야한다.
앞으로 설명할 소트 튜닝 방안을 요약하면 다음과 같다.
- 데이터 모델 측면에서의 검토
- 소트가 발생하지 않도록 SQL 작성
- 인덱스를 이용한 소트 연산 대체
- Sort Area를 적게 사용하도록 SQL 작성
- Sort Area 크기 조정
3절 이하부터 이들 내용을 중심으로 설명할 텐데, 그 전에 소트를 발생시키는 오퍼레이션에 어떤 것들이 있는지부터 살펴보자.