<오라클 성능 고도화 원리와 해법2> Ch05-03 데이터 모델 측면에서의 검토
오라클 성능 고도화 원리와 해법2 - Ch05-03 데이터 모델 측면에서의 검토
불합리한 데이터 모델이 소트 오퍼레이션을 유발하는 경우를 흔히 접할 수 있다. 튜닝 과정에서 조사된 SQL에 group by, union, distinct 같은 연산자가 불필요하게 많이 사용되는 패턴을 보인다면 대개 데이터 모델이 잘 정규화되지 않았음을 암시한다. 데이터 모델이 상(%)으로 발생한 데이터 중복을 제거하려다 보니 소트 오퍼레이션을 수행하게 되는 것이다.
사례 1
M:M 관계(Relationship)를 갖도록 테이블을 설계한 경우가 대표적이다. 그림5-3에 있는 BRD를 보자.
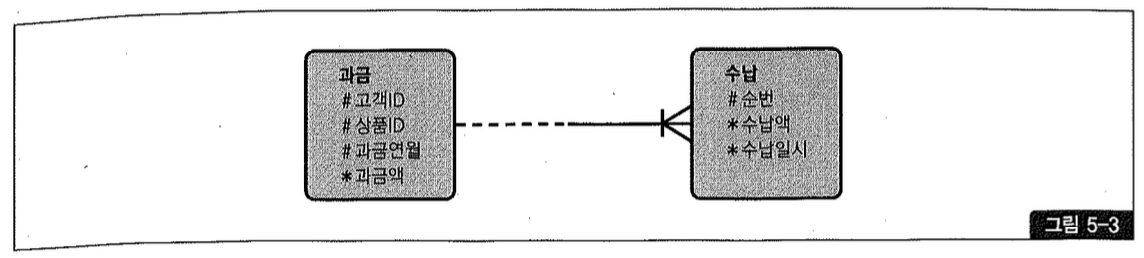
과금은 매달 한 번씩 발생하고, 하나의 과금에 대해 고객이 여러 번에 걸쳐 입금할 수 있기 때문에 수납과는 1:M 관계에 놓인다. 이 때문에 그림5-3과 같이 수납 테이블 PK 속성 그룹에는 순번 컬럼이 필요하다. 고객 ID, 상품 ID, 과금 연월은 과금 테이블로부터 상속받는다3).
- 바커 표기법(Barker Notation)에 익숙하지 않은 독자를 위해 설명하면, 수납쪽 Crowisfoot() 바로 왼쪽에 붙은 수직 Bar()는 부모 테이블 식별자를 자신의 식별자로 상속받음을 의미한다. 따라서 수납 테이블에 고객 ID, 상품 ID, 과금 연월을 표시하지 않았지만 암묵적으로 해당 속성이 순번과 더불어 PK 역할을 한다.
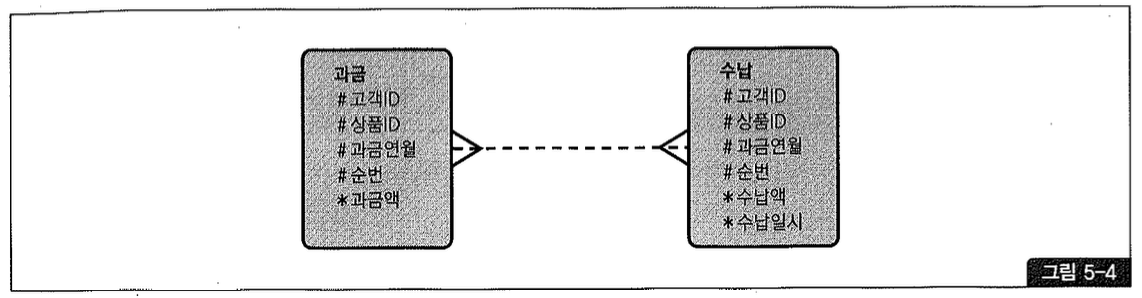
그런데 필자가 방문한 모회사는 그림5-4와 같이 M:M 관계로 설계돼 있었다. 과금 테이블에 있는 순번은 수납쪽 순번과 독립적으로 부여되는 속성이다. 따라서 과금과 수납 내역을 조회하려면 매번 아래처럼 과금 테이블을 먼저 group by해야만 한다.
1
2
3
4
5
6
7
8
9
10
11
select a.상품id, a.과금액, b.수납액, b.수납일시
from (select 고객1d, 상품1g, 과금연월, sum(과금액) 과금액
from 과금
where 과금연월= :과금연월
and 고객 id = :고객id
group by 고객id, 상품id, 과금연월) a
, 수납 b
where b.고객id(+) = a.고객id
and b.상품id(+) = a.상품id
and b.과금연월(+) = a.과금연월
order by a.상품id, b.순번
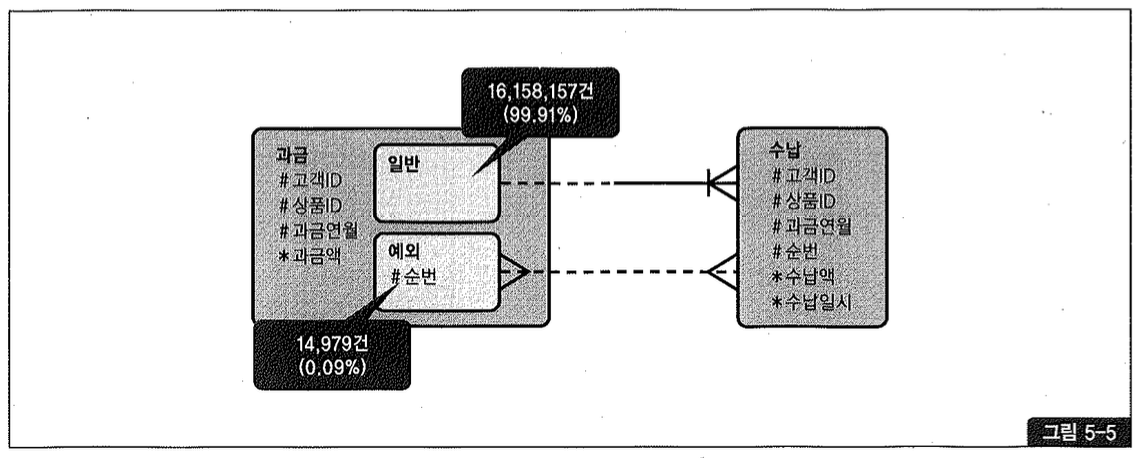
튜닝 과정에서 업무 담당자를 통해 확인한 결과, 정상적으로는 1:M 관계가 맞지만 과거 데이터 이관(Migration) 시 발생한 예외 케이스 때문에 M:M 모델이 되었다고 한다. 실제 데이터를 조회해본 결과, 그림5-5에 표현한 것처럼 불과 0.09%에 해당하는 14,979건만 M:M 관계에 놓여 있었다.
업무 담당자 및 개발팀과 협의한 끝에 데이터를 정제(Cleasing)하고 그림5-3과 같이 정상적인 1:M 관계를 갖도록 모델을 수정하였다. 그 결과, 불필요한 group by 연산을 제거할 수 있어 쿼리가 아래와 같이 간단해졌음은 물론 성능도 전반적으로 향상되었다.
1
2
3
4
5
6
7
8
select a.상품id, a.과금액, b.수납액, b.수납일시
from 과금 a, 수납 b
where a.과금연월 = :과금연월
and a.고객id = :고객id
and b.고객id (+) = a.고객id
and b.상품id (+) = a.상품id
and b.과금연월(+) = a.과금연월
order by a.상품id, b.순번
사례 2
두 번째 사례를 살펴보자. 정상적인 데이터 모델은 그림 5-6과 같다.
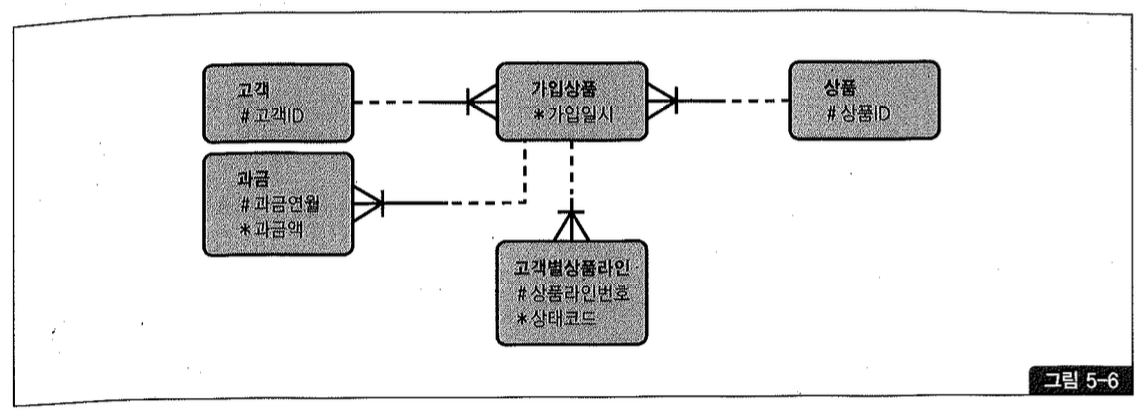
PK 외에 관리할 속성이 아예 없거나 그림 5-6의 ‘가입상품’처럼 소수(여기서는 가입일시 하나뿐임)일 때, 테이블 개수를 줄인다는 이유로 자식 테이블에 통합시키는 경우를 종종 볼 수 있다. 가입상품 테이블을 없애고 그림 5-7처럼 ‘고객별상품라인’에 통합하는 식이다.
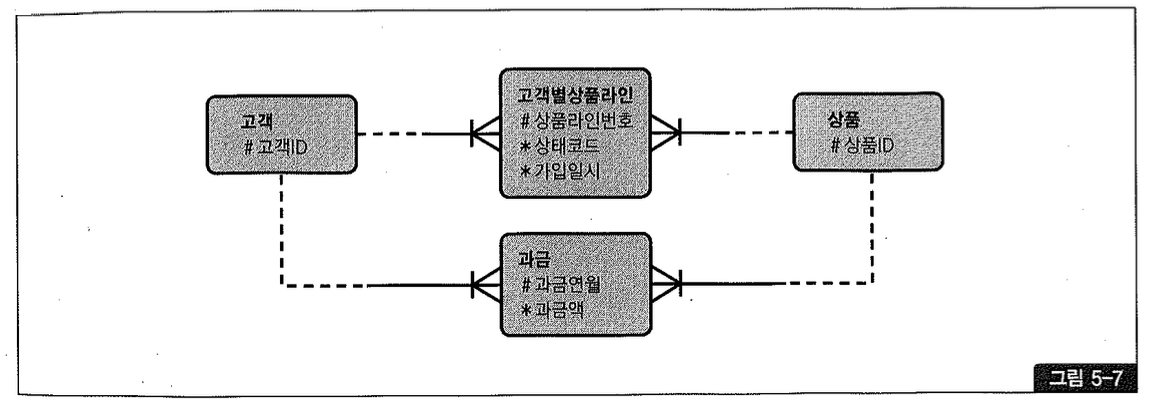
정보 누락이 없고, 가입일시는 최초 입력 후 변경되지 않는 속성이므로 정합성에도 문제가 안 생기겠지만 이 회사는 고객별 가입상품 레벨의 데이터 조회가 매우 빈번하게 발생한다. 그때마다 아래처럼 ‘고객별상품라인’ 테이블을 group by 해야 한다면 성능이 좋을 리 없다.
1
2
3
4
5
6
7
8
select 과금.고객id, 과금.상품id, 과금.과금액, 가입상품.가입일시
from 과금,
(select 고객id, 상품id, min(가입일시) 가입일시
from 고객별상품라인
group by 고객id, 상품id) 가입상품
where 과금.고객id(+) = 가입상품.고객id
and 과금.상품id(+) = 가입상품.상품id
and 과금.과금연월(+) = yyyymm
만약 그림 5-6처럼 잘 정규화된 데이터 모델을 사용했다면 쿼리도 아래처럼 간단해지고 시스템 전반의 성능 향상에도 도움이 된다.
1
2
3
4
5
select 과금.고객id, 과금.상품id, 과금.과금액, 가입상품.가입일시
from 과금, 가입상품
where 과금.고객id(+) = 가입상품.고객id
and 과금.상품id(+) = 가입상품.상품id
and 과금.과금연월(+) = :yyyymm
이 외에도 데이터 모델 때문에 소트 부하를 일으키는 사례는 무궁무진하지만 한 가지만 더 살펴보기로 하자.
사례 3
순번(seq) 컬럼을 증가시키면서 순서대로 데이터를 적재하는 점 이력 모델은 선분 이력에 비해 DML 부하를 최소화할 수 있는 장점이 있다. 그러나 대량 집합의 이력을 조회할 때 소트가 많이 발생하는 단점이 있다. 특히, 마지막 이력만 조회하는 업무가 대부분일 때 비효율이 크다.
여러 이력 테이블로부터 최근 데이터만을 읽어 조인하는 아래 쿼리를 보자.


이력 조회하는 모든 부분을 인라인 뷰로 감싸고, 분석 함수를 이용해 순번상 가장 큰 값을 갖는 레코드만을 추출하고 있다. 이 쿼리뿐만 아니라 대부분 쿼리가 이런 형태를 띠고 있다면 다른 대안 모델을 고려해봄 직하다.
예를 들어, 순번 컬럼을 99로 입력하거나 플래그 컬럼을 둔다면 소트를 일으키지 않고도 마지막 레코드를 쉽게 추출할 수 있다. 또한, 선분 이력 모델을 채택한다면 더 큰 유연성을 얻을 수 있다.
이들 대안 모델을 채택하면 새로운 이력이 쌓일 때마다 기존 값을 갱신해야 하는 부담이 생긴다. 하지만 한번의 갱신으로 수백 번의 조회를 빠르게 할 수 있다면 그것이 더 나은 선택일 것이다. 현재(=최종) 데이터만 주로 조회한다면, 데이터 중복이 있더라도 마스터 테이블을 이력 테이블과 별도로 관리하는 것도 좋은 방안이다.
방금 전 사례를 두고 모델이 잘못됐다고 말할 수는 없지만, 어떤 데이터 모델을 선택하느냐에 따라 성능에 차이가 생길 수 있음을 잘 보여준다. (데이터 모델은 다각적인 측면에서 평가가 이루어져야 한다. 단순히 소트가 많이 발생한다고 해서 잘못된 모델이라고 얘기해서는 안 된다. 소트 발생량 때문에 업무가 틀렸다고 말할 수 없는 것처럼 말이다.)