<오라클 성능 고도화 원리와 해법2> Ch05-04 소트가 발생하지 않도록 SQL 작성
오라클 성능 고도화 원리와 해법2 - Ch05-04 소트가 발생하지 않도록 SQL 작성
데이터 모델 측면에서는 이상이 없는데, 불필요한 소트가 발생하도록 SQL을 작성하는 경우가 있다. 예를 들어, 아래처럼 UNION을 사용하면 옵티마이저는 상단과 하단의 두 집합 간 중복을 제거하려고 SORT UNIQUE 연산을 수행한다.
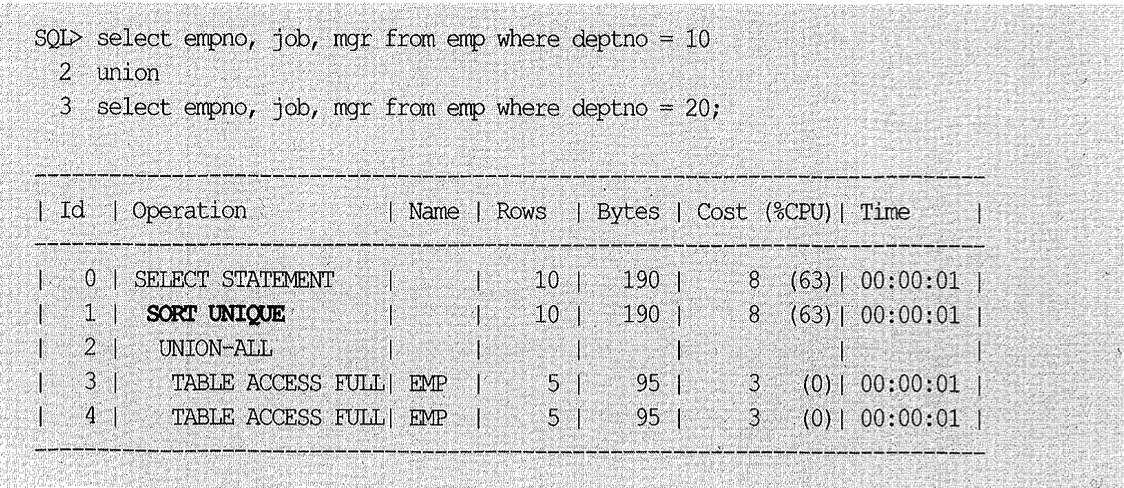
하지만 PK 컬럼인 empno를 SELECT 리스트에 포함하므로 두 집합 간에는 중복 가능성이 전혀 없다. 따라서 UNION ALL을 사용해야 한다. UNION ALL은 중복을 확인하지 않고 두 집합을 단순히 결합하므로 소트 부하가 없다. 사원이 중복될 가능성이 없으면 UNION과 UNION ALL의 의미가 달라지지 않는다.
그럼에도 불구하고 위와 같이 UNION을 즐겨 사용하는 개발자를 종종 볼 수 있다. 이들은 두 가지 중 하나에 속하는데, UNION과 UNION ALL 처리 방식의 차이를 모르거나 집합 개념이 부족해 혹시 중복이 발생할지도 모른다는 불안감 때문에 그렇게 하는 경우이다.
DISTINCT를 사용하는 경우도 매우 흔한데, 대부분 EXISTS 서브쿼리로 대체함으로써 소트 연산을 없앨 수 있다.
EXISTS 서브쿼리의 가장 큰 특징은, 메인 쿼리로부터 건건이 입력받은 값에 대한 조건을 만족하는 첫 번째 레코드를 만나는 순간 TRUE를 반환하고 서브쿼리 수행을 마친다는 점이다. 따라서 과금 테이블에 [과금연월 + 지역] 순으로 인덱스를 구성해주기만 하면 가장 최적으로 수행될 수 있다.
그 결과, 소트를 발생시키지 않았음은 물론 82개 블록만 읽고 0.01초 만에 수행을 완료했다. 물론 연월(yyyymm)을 관리하는 테이블이 따로 있을 때 적용 가능한 기법이다.