<오라클 성능 고도화 원리와 해법2> Ch05-05 인덱스를 이용한 소트 연산 대체
오라클 성능 고도화 원리와 해법2 - Ch05-05 인덱스를 이용한 소트 연산 대체
인덱스는 항상 키 컬럼 순으로 정렬된 상태를 유지하므로 이를 이용해 소트 오퍼레이션을 생략할 수 있다. 소트 머지 조인에서 Outer 테이블 조인 컬럼에 인덱스가 있을 때 sort join 오퍼레이션을 생략하는 경우를 2장에서 이미 살펴보았다.
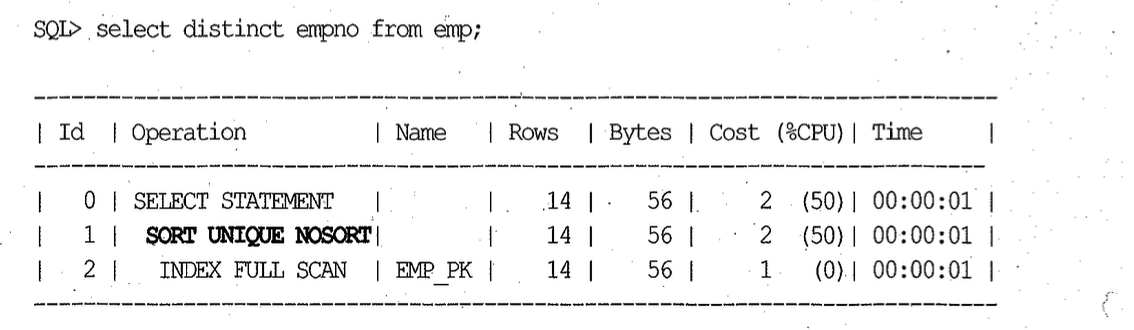
서브쿼리에 사용된 테이블이 Unique 인덱스를 갖는다면 Unnesting 되었을 때 sort unique 오퍼레이션이 생략된다는 사실도 4장에서 이미 설명하였다. PK 컬럼에 아래와 같은 DISTINCT 쿼리를 수행할 일은 없겠지만 혹시 수행한다면 이때도 sort unique 오퍼레이션이 생략된다. sort unique no sort가 그것을 표현하고 있는데, 소트를 수행하지 않고도 인덱스를 이용해 unique한 집합을 출력할 수 있다.
이들보다 활용도가 높은 것은 인덱스를 이용해 sort order by, sort group by를 대체하는 경우이다. 이에 대해 좀 더 자세히 살펴보기로 하자.
(1) Sort Order By 대체
아래 쿼리를 수행할 때 [region + custid] 순으로 구성된 인덱스를 사용한다면 sort order by 연산을 대체할 수 있다.
1
2
3
4
select custid, name, resno, status, tell
from customer
where region = 'A'
order by custid
인덱스가 region 단일 컬럼으로 구성됐거나, 결합 인덱스더라도 region 바로 뒤에 custid가 오지 않는다면 region = ‘A’ 조건을 만족하는 모든 레코드를 인덱스를 경유해 읽어야 한다. 그 과정에서 다량의 랜덤 액세스가 발생할 테고, 읽은 데이터를 custid 순으로 정렬하고 나서야 결과 집합 출력을 시작하므로 OLTP 환경에서 요구되는 빠른 응답 속도를 만족하기 어렵게 된다.
아래는 region 단일 컬럼 인덱스를 사용할 때의 실행 계획이다.
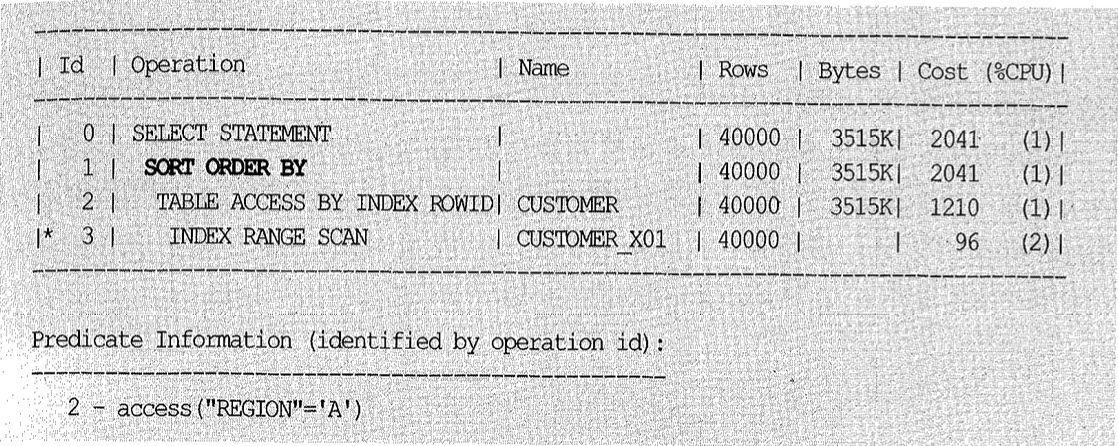
Full Table Scan 방식으로 처리하면 테이블 랜덤 액세스 부하는 줄일 수 있지만 필요 없는 레코드까지 모두 읽는 비효율이 따르고, 정렬 작업 때문에 전체 범위 처리가 불가피하다.
아래는 [region + custid] 순으로 구성된 인덱스를 사용할 때의 실행 계획이며, order by 절을 그대로 둔 상태에서 자동으로 sort order by 오퍼레이션이 제거된 것을 볼 수 있다. 이 방식으로 수행한다면 region = ‘A’ 조건을 만족하는 전체 로우를 읽지 않고도 결과 집합 출력을 시작할 수 있어 OLTP 환경에서 극적인 성능 개선 효과를 가져다준다.
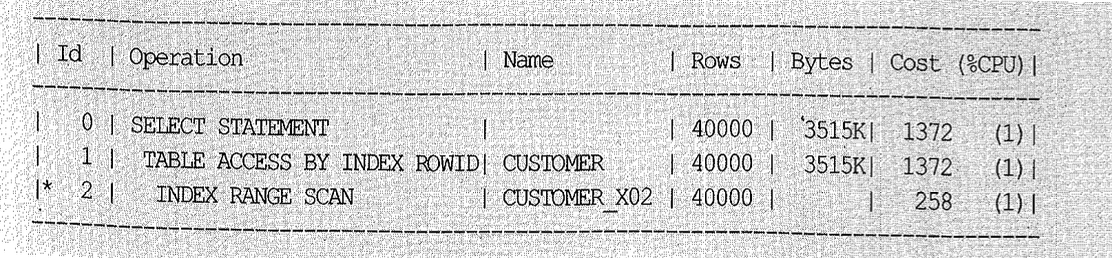

물론, 소트해야 할 대상 레코드가 무수히 많고 그중 일부만 읽고 멈출 수 있는 업무에서만 이 방식이 유리하다. 인덱스를 스캔하면서 결과 집합을 끝까지 Fetch 한다면 오히려 I/O 및 리소스 사용 측면에서 손해이다. 대상 레코드가 소량일 때는 소트가 발생하더라도 부하가 크지 않아 개선 효과도 미미하다.
(2) Sort Group By 대체
region이 선두 컬럼인 결합 인덱스나 단일 컬럼 인덱스를 사용하면 아래 쿼리에 필요한 sort group by 연산을 대체할 수 있다. 실행 계획에 ‘sort group by nosort’라고 표시되는 부분을 확인하기 바란다.
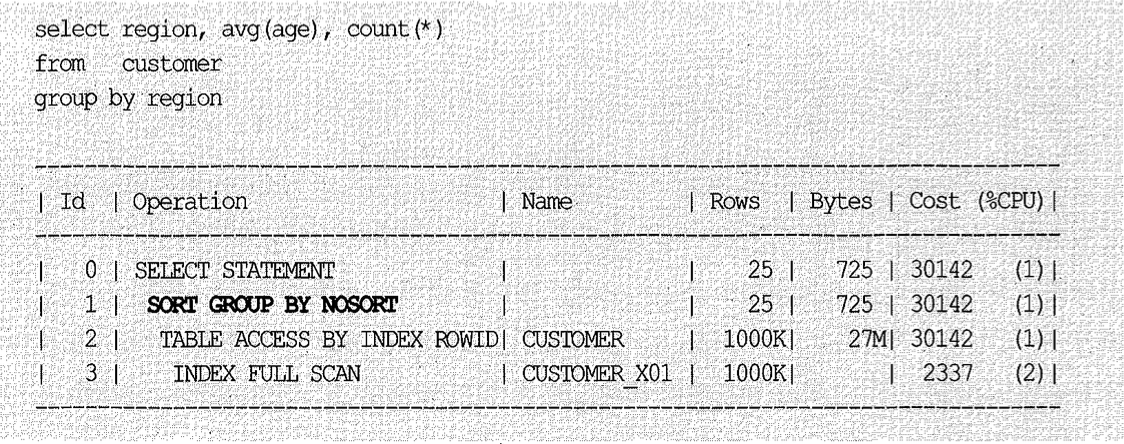
그림 5-9를 보면, 위 실행 계획이 어떻게 수행되는지 쉽게 이해할 수 있다.
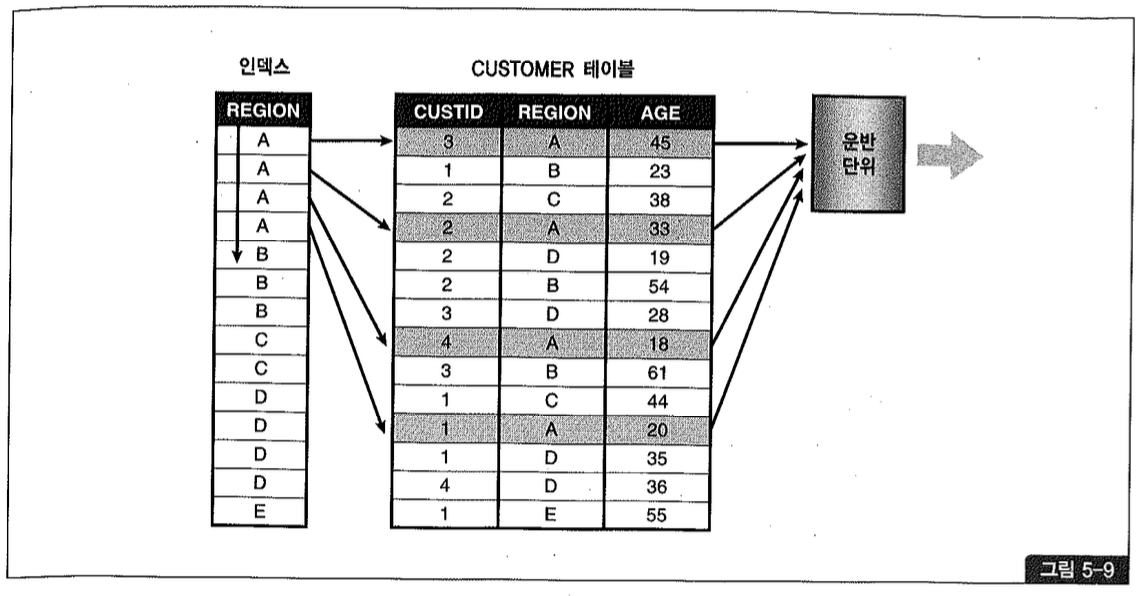
간단히 설명하면, 인덱스를 스캔하면서 테이블을 액세스하다가 ‘A’가 아닌 레코드를 만나는 순간 그때까지 집계한 값을 Oracle Net으로 내려보낸다. 이 값은 운반 단위에 해당하는 SDU(Session Data Unit)에 버퍼링될 것이다. 다시 인덱스를 스캔하다가 ‘B’가 아닌 레코드를 만나는 순간 그때까지 집계한 값을 Oracle Net으로 내려보낸다. 이런 과정을 반복하다가 사용자 Fetch Call에서 요청한 레코드 개수(Array Size)에 도달하면 전송 명령을 내려 보내고는 다음 Fetch Call이 올 때까지 기다린다.
이처럼 인덱스를 이용한 nosort 방식으로 수행될 때는 group by 오퍼레이션에도 불구하고 부분 범위 처리가 가능해져 OLTP 환경에서 매우 극적인 성능 개선 효과를 얻을 수 있다.
(3) 인덱스가 소트 연산을 대체하지 못하는 경우
아래는 sal 컬럼을 선두로 갖는 인덱스가 있는데도 정렬을 수행하는 경우이다.
1
SQL> select * from emp order by sal;

옵티마이저가 이런 결정을 하는 가장 흔한 원인은, 인덱스를 이용하지 않는 편이 더 낫다고 판단하는 경우이다. 위 실행 계획에서 옵티마이저 모드가 all_rows인 것을 볼 수 있고, 이때 옵티마이저는 전체 로우를 Fetch하는 것을 기준으로 쿼리 수행 비용을 산정한다. 따라서 데이터량이 많을수록 인덱스를 이용한 테이블 랜덤 액세스 비용이 높아져 옵티마이저는 차라리 Full Table Scan 하는 쪽을 택할 가능성이 높아진다.
옵티마이저 모드를 first_rows로 바꾸면 사용자가 일부만 Fetch하고 멈출 것임을 시사하므로 옵티마이저는 인덱스를 이용해 정렬 작업을 대체한다. 아래는 first_rows 힌트를 사용했을 때의 실행 계획이다.

옵티마이저 모드를 바꿨는데도 옵티마이저가 계속해서 소트 오퍼레이션을 고집한다면 그럴 만한 이유가 있다. 십중팔구 sal 컬럼에 not null 제약이 정의돼 있지 않을 것이다. 단일 컬럼 인덱스일 때 값이 null이면 인덱스 레코드에 포함되지 않는다. 따라서 인덱스를 이용해 정렬 작업을 대체한다면 결과에 오류가 생길 수 있어 옵티마이저는 사용자의 뜻을 따를 수 없는 것이다.
group by도 마찬가지이다. group by nosort를 위해 사용하려는 인덱스가 단일 컬럼 인덱스일 때는 해당 컬럼에 not null 제약이 설정돼 있어야 제대로 작동한다.
인덱스가 있는데도 소트를 대체하지 못하는 사례가 또 한 가지 있다. 아래 스크립트와 실행 계획을 보자.
1
2
3
SQL> create index emp_deptno_ename_idx on emp(deptno, ename);
SQL> set autotrace traceonly exp
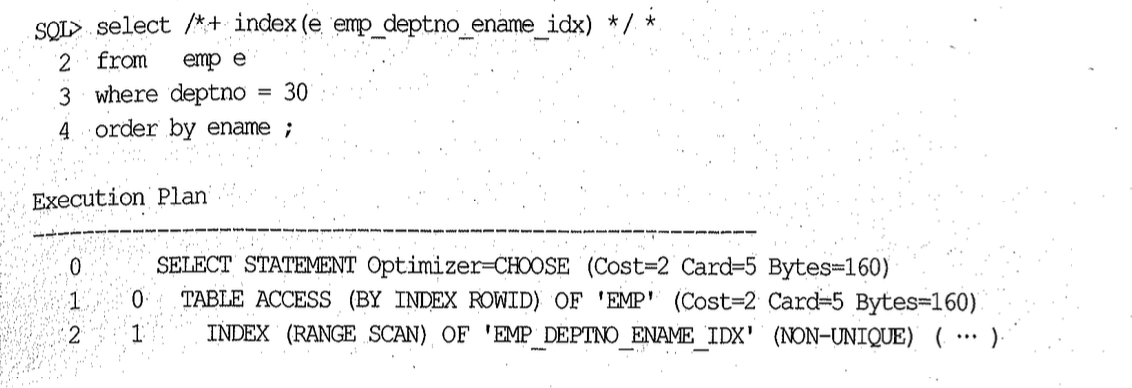
정상적으로 인덱스를 사용하는 것을 확인할 수 있다. 그런데 null 값이 먼저 출력되도록 하려고 아래처럼 nulls first 구문을 사용하는 순간 실행 계획에 sort order by가 다시 나타난다.

단일 컬럼 인덱스일 때는 null 값을 저장하지 않지만 결합 인덱스일 때는 null 값을 가진 레코드를 맨 뒤쪽에 저장한다. 따라서 null 값을 출력하려고 할 때는 인덱스를 이용하더라도 소트가 불가피하다.