<오라클 성능 고도화 원리와 해법2> Ch06-01 테이블 파티셔닝
오라클 성능 고도화 원리와 해법2 - Ch06-01 테이블 파티셔닝
파티셔닝(Partitioning)은 테이블 인덱스 데이터를 파티션(Partition) 단위로 나누어 저장하는 것을 말한다. 테이블을 파티셔닝하면 하나의 테이블일지라도 파티션 키에 따라 물리적으로는 별도의 세그먼트에 데이터가 저장되며, 인덱스도 마찬가지이다.
그림 6-1처럼 계절별로 옷을 관리하면 외출에 필요한 옷을 쉽고 빠르게 찾을 수 있는 것처럼 데이터를 월별, 분기별, 반기별, 연별로 저장해두면 조회할 때 매우 효과적이다. 일반적으로 시계열에 따라 분할 저장하지만 그 외 다른 기준(리스트 또는 해시)으로 분할할 수도 있다.
파티셔닝이 필요한 이유를 관리적 측면과 성능적 측면으로 나누어볼 수 있다.
- 관리적 측면: 파티션 단위 백업, 추가, 삭제, 변경
- 성능적 측면: 파티션 단위 조회 및 DML 수행
파티셔닝은 우선 관리적 측면에서 많은 이점을 제공한다. 보관 주기가 지난 데이터를 별도 장치에 백업하고 지우는 일은 데이터베이스 관리자들의 일상적인 작업이다. 만약 파티션 도움 없이 대용량 테이블에 그런 작업을 수행하려면 시간도 오래 걸리고 비효율적이다.
성능적 측면의 효용성도 매우 높다. 데이터를 빠르게 검색할 목적으로 데이터베이스마다 다양한 저장 구조와 검색 기법들이 개발되고 있지만, 인덱스를 이용하는 방법과 테이블 전체를 스캔하는 두 가지 방법에서 크게 벗어나지는 못하고 있다. 인덱스를 이용해 건건이 테이블을 액세스하는 방식은 일정량을 넘는 순간 오히려 테이블 전체를 읽는 것보다 못한 결과를 가져온다. 그렇다고 테이블 전체를 스캔하기에는 절대량이 많아 부담스러운 경우에 자주 직면하는데, 그럴 때 테이블을 적당한 단위로 나누어 저장한다면 Full Scan하더라도 일부 파티션 세그먼트만 읽고 멈출 수 있다. 그뿐만 아니라 파티셔닝과 병렬 처리가 만났을 때 그 효과가 배가된다.
파티셔닝도 클러스터, IOT와 마찬가지로 관련 있는 데이터가 흩어지지 않고 물리적으로 인접하도록 저장하는 클러스터링 기술에 속한다. 클러스터와 다른 점은 세그먼트 단위로 모아서 저장한다는 것이다. 클러스터는 블록 단위로 데이터를 모아 저장한다고 1장에서 설명하였다. IOT는 정렬된 순서로 데이터를 저장하는 구조인데, 1장에서 설명했듯이 IOT와 파티셔닝을 조합(Partitioned IOT)함으로써 놀라운 성능 효과를 얻을 수 있다.
테이블 파티션과 인덱스 파티션은 구분돼야 한다. 인덱스 파티션에 대해서는 3절에서 설명하며, 본 절에서는 테이블 파티션을 중심으로 설명할 것이다.
(1) 파티션 기본 구조
파티션 내부 구조에 대해 익숙하지 않은 독자들을 위해 수동 파티셔닝에 대한 설명부터 시작하려고 한다.
수동 파티셔닝
파티션 테이블이 처음 제공되기 시작한 것은 오라클 버전 8부터이다. 그 이전 7.3 버전에서는 파티션 뷰를 통해 파티션 기능을 구현했으며, 이를 ‘수동 파티셔닝(manual partitioning)’이라고 부른다. 아래 스크립트를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
-- 파티션 뷰를 정의할 때 사용할 Base 테이블을 만든다.
CREATE TABLE p1 AS SELECT * FROM scott.emp WHERE deptno = 10;
CREATE TABLE p2 AS SELECT * FROM scott.emp WHERE deptno = 20;
CREATE TABLE p3 AS SELECT * FROM scott.emp WHERE deptno = 30;
-- 체크 제약을 반드시 설정해야 함
ALTER TABLE p1 ADD CONSTRAINT c_deptno_10 CHECK (deptno < 20);
ALTER TABLE p2 ADD CONSTRAINT c_deptno_20 CHECK (deptno >= 20 AND deptno < 30);
ALTER TABLE p3 ADD CONSTRAINT c_deptno_30 CHECK (deptno >= 30 AND deptno < 40);
CREATE INDEX p1_empno_idx ON p1 (empno);
CREATE INDEX p2_empno_idx ON p2 (empno);
CREATE INDEX p3_empno_idx ON p3 (empno);
ANALYZE TABLE p1 COMPUTE STATISTICS;
ANALYZE TABLE p2 COMPUTE STATISTICS;
ANALYZE TABLE p3 COMPUTE STATISTICS;
-- 파티션 뷰를 정의한다.
CREATE OR REPLACE VIEW partition_view AS
SELECT * FROM p1
UNION ALL
SELECT * FROM p2
UNION ALL
SELECT * FROM p3;
p1, p2, p3 테이블을 UNION ALL로 묶어 파티션 뷰를 생성했다. 파티션 뷰의 핵심 기능은 뷰 쿼리에 사용된 조건절에 부합하는 테이블만 읽는다는 점이며, 이를 파티션 프루닝(Partition Pruning)이라고 한다.
파티션 테이블
오라클 8에서 도입된 파티션 테이블 기능을 이용하면 아래와 같이 훨씬 간편하게 파티션을 정의할 수 있을 뿐 아니라 기능적으로도 더 낫다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE TABLE partition_table (
empno NUMBER,
ename VARCHAR2(10),
deptno NUMBER
)
PARTITION BY RANGE (deptno) (
PARTITION p1 VALUES LESS THAN (20),
PARTITION p2 VALUES LESS THAN (30),
PARTITION p3 VALUES LESS THAN (40)
)
AS
SELECT * FROM emp;
CREATE INDEX ptable_empno_idx ON partition_table(empno) LOCAL;
PARTITION BY 절은 파티션 뷰의 Base 테이블에 체크 제약을 설정하는 것과 같은 역할을 한다. 위처럼 파티션 테이블을 정의하면 세 개의 세그먼트가 생성되므로 앞에서 파티션 뷰를 정의할 때와 구조적으로 같다. 인덱스를 만들 때도 LOCAL 옵션을 지정했으므로 각 파티션별로 개별적인 인덱스가 만들어져, 파티션 뷰 Base 테이블에 각각 인덱스를 만든 것과 같은 모습이다.
데이터베이스 관리자가 수동으로 작업하던 것을 CREATE TABLE 문장에 몇 가지 옵션을 지정함으로써 간단히 해결할 수 있게 된 것일 뿐, 내부 물리적인 구조는 파티션 뷰와 별반 다르지 않다. 쿼리를 작성하는 개발자 입장에서도 달라진 것이 없다. 자동으로 쿼리 조건절에 부합하는 세그먼트만 찾아 읽는 기능(파티션 프루닝)은 예나 지금이나 옵티마이저의 몫이기 때문이다.
이처럼 파티셔닝은 내부에 몇 개의 세그먼트를 생성하고 그것들이 논리적으로 하나의 오브젝트임을 메타 정보로 딕셔너리에 저장해두는 것에 지나지 않는다. 파티션되지 않은 일반 테이블일 때는 테이블과 세그먼트가 1:1 관계지만, 파티션 테이블일 때는 1:M 관계이다. 인덱스를 파티셔닝할 때도 마찬가지이다.
데이터베이스의 물리적인 저장 구조에 익숙한 DBA에게는 파티션 구조를 이해하는 것이 어렵지 않지만, 일반 개발자에게는 그렇지 않을 수 있다. 그래서 지금은 거의 쓰임새가 없다고 할 수 있는 파티션 뷰 개념을 빌어 파티션 테이블의 내부 구조를 설명해보았다.
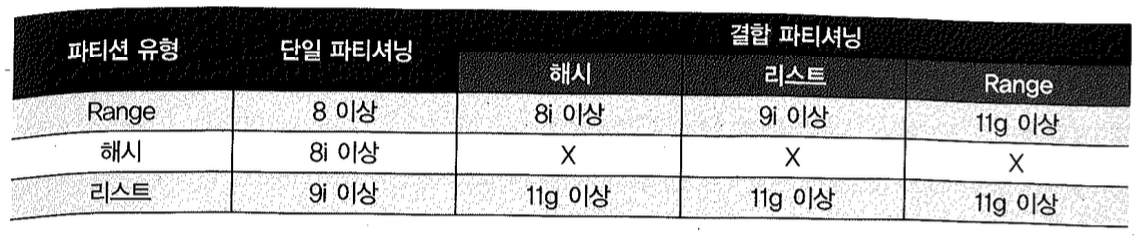
버전이 올라가면서 기능이 계속 확장되고 있는 테이블 파티션 유형에는 아래와 같은 것들이 있다.
- Range 파티셔닝(8 이상)
- 해시 파티셔닝(8i 이상)
- 리스트 파티셔닝(9i 이상)
- Range-해시 파티셔닝(8i 이상)
- Range-리스트 파티셔닝(9i 이상)
- Range-Range 파티셔닝(11g 이상)
- 리스트-해시 파티셔닝(11g 이상)
- 리스트-리스트 파티셔닝(11g 이상)
- 리스트-Range 파티셔닝(11g 이상)
아래는 버전별 지원 여부를 표로 정리한 것이다.
(2) Range 파티셔닝
오라클 8버전부터 제공된 가장 기초적인 파티셔닝 방식으로서, 주로 날짜 컬럼을 기준으로 한다. 아래는 주문 테이블을 주문 일자 기준으로 분기별 Range 파티셔닝하는 방법을 예시하고 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
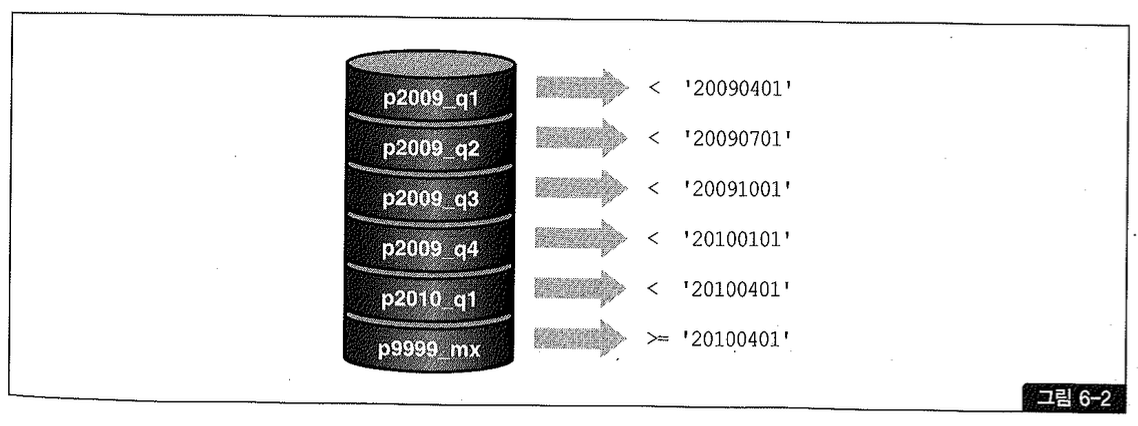
CREATE TABLE 주문 (
주문번호 NUMBER,
주문일자 VARCHAR2(8),
고객ID VARCHAR2(5)
)
PARTITION BY RANGE(주문일자) (
PARTITION p2009_q1 VALUES LESS THAN ('20090401'),
PARTITION p2009_q2 VALUES LESS THAN ('20090701'),
PARTITION p2009_q3 VALUES LESS THAN ('20091001'),
PARTITION p2009_q4 VALUES LESS THAN ('20100101'),
PARTITION p2010_q1 VALUES LESS THAN ('20100401'),
PARTITION p9999_max VALUES LESS THAN (MAXVALUE) # -> 주문일자 >= ' 20100401'
);
위 스크립트에 의해 생성된 파티션을 그림으로 표현하면 그림 6-2와 같다.
이와 같은 파티셔닝 테이블에 값을 입력하면 각 레코드를 파티션 키 컬럼 값에 따라 분할 저장하고, 읽을 때도 검색 조건을 만족하는 파티션만 읽을 수 있어 이력성 데이터 조회 시 성능을 크게 향상시킨다. 파티션 키로는 하나 이상의 컬럼을 지정할 수 있고, 최대 16개까지 허용된다.
보관 주기 정책에 따라 과거 데이터가 저장된 파티션만 백업하고 삭제하는 등 데이터 관리 작업을 효율적이고 빠르게 수행할 수 있는 것도 큰 장점이다.
DB 관리자의 실수로 신규 파티션 생성을 빠뜨리면 월초 또는 연초에 데이터가 입력되지 않는 오류가 발생하므로, MAXVALUE 파티션을 반드시 생성해두는 것이 좋다. 참고로 11g부터는 Range 파티션을 생성할 때 interval 기준을 정의함으로써 정해진 간격으로 파티션이 자동 추가되도록 할 수 있는데, (6)항에서 간단히 소개하므로 참조하기 바란다.
(3) 해시 파티셔닝
해시 파티셔닝은 Range 파티셔닝에 이어 오라클 8i 버전부터 제공되기 시작했다. 파티션 키에 해시 함수를 적용한 결과 값이 같은 레코드를 같은 파티션 세그먼트에 저장하는 방식이며, 주로 고객 ID처럼 변별력이 좋고 데이터 분포가 고른 컬럼을 파티션 기준 컬럼으로 선정해야 효과적이다.
검색할 때는 조건 비교 값(상수 또는 변수)에 해시 함수를 적용해 읽어야 할 파티션을 결정하며, 해시 알고리즘 특성상 등치(=) 조건 또는 IN-List 조건으로 검색할 때만 파티션 프루닝이 작동한다.
아래는 고객 ID 기준으로 고객 테이블을 해시 파티셔닝하는 방법을 예시하고 있다.
1
2
3
4
5
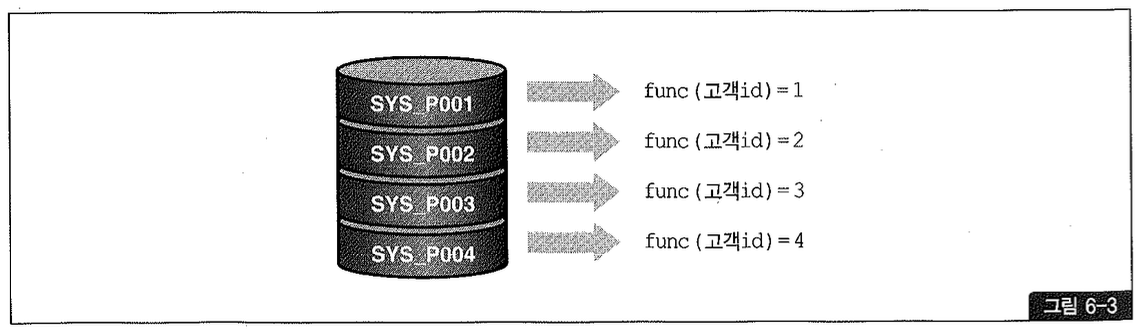
CREATE TABLE 고객 (
고객ID VARCHAR2(5),
고객명 VARCHAR2(10)
)
PARTITION BY HASH(고객ID) PARTITIONS 4;
위 스크립트에 의해 생성된 파티션을 그림으로 표현하면 그림 6-3과 같다.
테이블 파티셔닝 여부를 결정할 때는 데이터가 얼마나 고르게 분산될 수 있느냐가 가장 중요한 관심사이다. 해시 파티셔닝할 때 특히 데이터 분포를 신중히 고려해야 하는데, 사용자가 직접 파티션 기준을 정하는 Range, 리스트 파티셔닝과 다르게 해시 파티셔닝은 파티션 개수만 사용자가 결정하고 데이터를 분산시키는 해싱 알고리즘은 오라클에 의해 결정되기 때문이다. 따라서 파티션 키를 잘못 선정하면 데이터가 고르게 분산되지 않아 파티셔닝의 이점이 사라질 수 있다.
오라클은 특정 파티션에 데이터가 몰리지 않도록 하려면 파티션 개수를 2의 제곱(2, 4, 8, 16 등)으로 설정할 것을 권고한다. 이 규칙을 따르더라도 파티션 키 컬럼의 Distinct Value 개수가 적다면 데이터가 고르게 분산되지 않을 가능성이 높으므로, 이때는 리스트 파티션을 이용해 파티션 기준을 사용자가 수동으로 결정해주는 것이 낫다.
병렬 쿼리 성능 향상
데이터가 모든 파티션에 고르게 분산돼 있다면, 더구나 각 파티션이 서로 다른 디바이스에 저장돼 있다면 병렬 I/O 성능을 극대화할 수 있다. 반대로 데이터가 고르게 분산되지 않을 때는 병렬 쿼리 효과가 반감된다.
DML 경합 분산
병렬 쿼리 성능 향상뿐만 아니라 동시 입력이 많은 대용량 테이블이나 인덱스에 발생하는 경합을 줄일 목적으로도 해시 파티셔닝을 사용한다. 대용량 거래 테이블일수록 DML 발생량이 많아 경합 발생 가능성도 그만큼 크다.
데이터가 입력되는 테이블 블록에도 경합이 발생할 수 있지만, 그보다는 입력할 블록을 할당받기 위한 Freelist 조회 때문에 세그먼트 헤더 블록에 대한 경합이 더 자주 발생한다. 그럴 때 테이블을 해시 파티셔닝하면 세그먼트 헤더 블록에 대한 경합을 줄일 수 있다.
Right Growing 인덱스(예를 들어, 순차적으로 증가하는 일련번호 컬럼에 인덱스를 생성하는 경우)도 자주 경합 지점이 되곤 하는데, 맨 우측 끝 블록에만 값이 입력되는 특징 때문이다. 이때도 인덱스를 해시 파티셔닝함으로써 경합 발생 가능성을 낮출 수 있다.
경합 분산이나 병렬 쿼리 성능 향상, 두 가지 모두 트랜잭션이 많이 발생하는 대용량 거래 테이블일 때라야 효과가 있다. 단일 해시 파티셔닝보다는 Range와 해시를 조합한 결합 파티셔닝을 주로 사용하게 되는 이유가 여기에 있다. 다만, 대용량 거래 테이블과의 Full Partition-Wise 조인을 위해 단일 해시 파티셔닝을 선택하는 경우가 종종 있는데, 이에 대해서는 7장에서 자세히 다룬다.
(4) 리스트 파티셔닝
오라클 9i 버전부터 제공되기 시작한 리스트 파티셔닝은 사용자가 미리 정해진 그룹핑 기준에 따라 데이터를 분할 저장하는 방식이다. 아래는 지역 분류 기준으로 인터넷 매물 테이블을 리스트 파티셔닝하는 방법을 예시하고 있다.
1
2
3
4
5
6
7
8
9
10
CREATE TABLE 인터넷매물 (
물건코드 VARCHAR2(5),
지역분류 VARCHAR2(4)
)
PARTITION BY LIST(지역분류) (
PARTITION p_지역1 VALUES ('서울'),
PARTITION p_지역2 VALUES ('경기', '인천', '대전', '광주'),
PARTITION p_지역3 VALUES ('부산', '대구'),
PARTITION p_기타 VALUES (DEFAULT) # -> 기타 지역
);
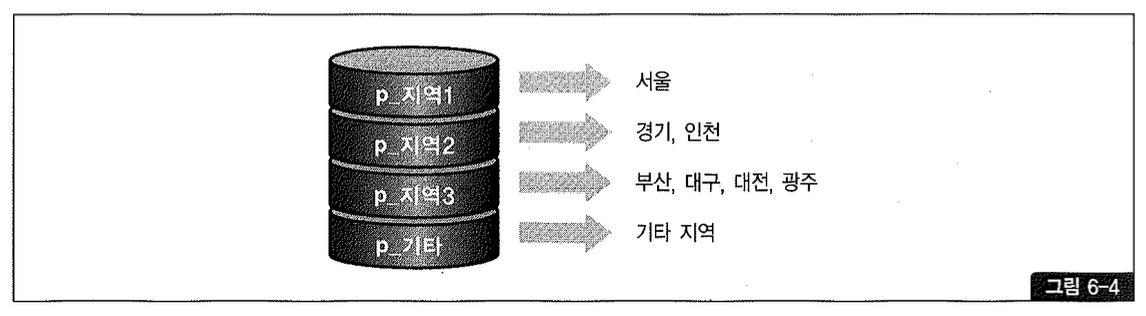
Range 파티션에서는 값의 순서에 따라 저장할 파티션이 결정되지만, 리스트 파티션에서는 순서와 상관없이 불연속적인 값의 목록으로써 결정된다.
해시 파티션과 비교하면, 해시 파티션은 오라클이 정한 해시 알고리즘에 따라 임의로 분할하는 구조인 반면 리스트 파티션은 사용자가 정의한 논리적인 그룹에 따라 분할한다. 업무적인 친화도에 따라 그룹핑 기준을 정하더라도 될 수 있으면 각 파티션에 값이 고르게 분산되도록 설계해야 한다.
Range, 해시 파티셔닝과 달리 리스트 파티셔닝에는 단일 컬럼으로만 파티션 키를 지정할 수 있다. 그리고 Range 파티션에 MAXVALUE 파티션을 반드시 생성하라고 권고한 것과 같은 이유로, 리스트 파티션에도 DEFAULT 파티션을 생성해 두어야 안전하다.
(5) 결합 파티셔닝
결합 파티셔닝(composite partitioning)은 주 파티션마다 세그먼트를 하나씩 할당하고, 서브 파티션 단위로 데이터를 저장한다. 즉, 주 파티션 키에 따라 1차적으로 데이터를 분배하고, 서브 파티션 키에 따라 최종적으로 저장할 위치(세그먼트)를 결정한다.
8i에서는 “Range + 해시” 형태만 가능했지만, 9i부터 “Range + 리스트” 형태도 지원하기 시작했다. 11g부터는 주 파티션이 해시 방식이 아닌 모든 조합을 지원한다.
「Range + 해시」 결합 파티셔닝
아래는 주문 일자 기준으로 주문 테이블을 분기별 Range 파티셔닝하고, 그 안에서 다시 고객 ID 기준으로 해시 파티셔닝하는 방법을 예시하고 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CREATE TABLE 주문 (
주문번호 NUMBER,
주문일자 VARCHAR2(8),
고객ID VARCHAR2(5)
)
PARTITION BY RANGE(주문일자)
SUBPARTITION BY HASH(고객ID)
SUBPARTITIONS 8 (
PARTITION p2009_q1 VALUES LESS THAN ('20090401'),
PARTITION p2009_q2 VALUES LESS THAN ('20090701'),
PARTITION p2009_q3 VALUES LESS THAN ('20091001'),
PARTITION p2009_q4 VALUES LESS THAN ('20100101'),
PARTITION p2010_q1 VALUES LESS THAN ('20100401'),
PARTITION p9999_max VALUES LESS THAN (MAXVALUE)
);
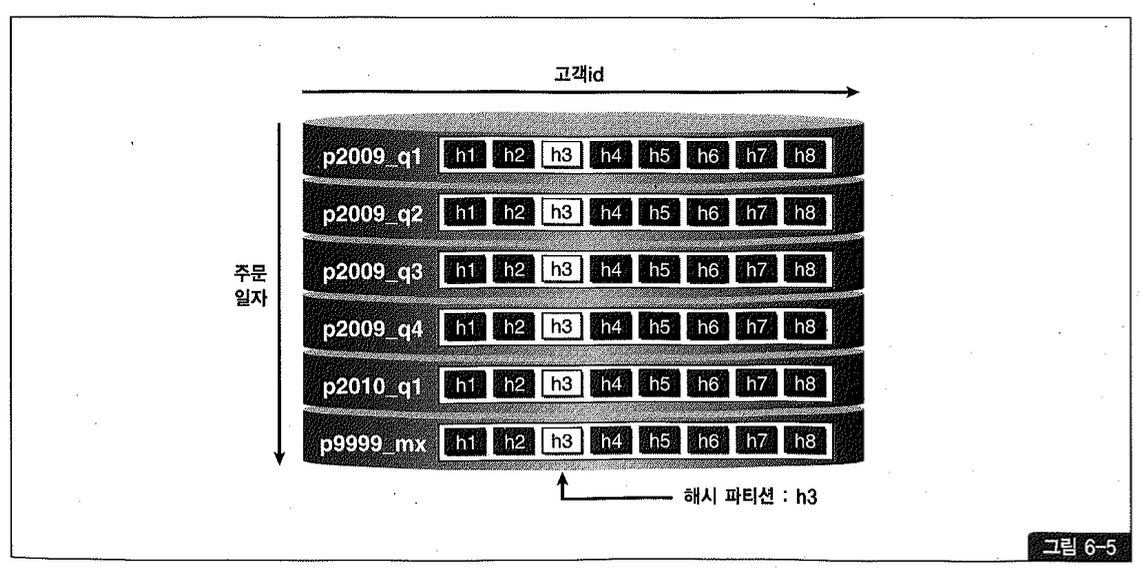
그림 6-5를 보면, 각 Range 파티션 내에서 다시 해시 알고리즘을 사용해 각 서브 파티션으로 데이터를 분할 저장한 것을 볼 수 있다. 이와 같은 파티션 테이블에 아래 쿼리를 수행하면 Range 파티션 p2009_q3(2009년 3분기)에 속한 8개 서브 파티션을 탐색한다.
1
SELECT * FROM 주문 WHERE 주문일자 BETWEEN '20090701' AND '20090930';
만약 아래와 같이 주문 일자 조건 없이 고객 ID만으로 조회하면, 각 Range 파티션당 하나씩 총 6개의 서브 파티션(그림 6-5에서 하이라이트된 h3 서브 파티션들)을 탐색한다.
1
SELECT * FROM 주문 WHERE 고객ID = :custid;
대용량 거래 테이블을 이와 같이 파티셔닝하면 Range 파티셔닝과 해시 파티셔닝의 장점을 둘 다 누릴 수 있으며, 각각의 장점에 대해서는 이미 설명하였다.
「Range + 리스트」 결합 파티셔닝
오라클 9i에서 리스트 파티셔닝이 도입됨과 동시에 Range + 리스트 형태의 결합 파티셔닝도 가능해졌다. 아래는 판매 테이블을 판매 일자 기준으로 분기별 Range 파티셔닝하고, 그 안에서 다시 판매점 기준으로 리스트 파티셔닝하는 방법을 예시하고 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
CREATE TABLE 판매 (
판매번호 VARCHAR2(10),
판매일자 VARCHAR2(8),
판매점 VARCHAR2(20)
)
PARTITION BY RANGE(판매일자)
SUBPARTITION BY LIST(판매점)
SUBPARTITION TEMPLATE (
SUBPARTITION lst_01 VALUES ('강남지점', '강북지점', '강서지점', '강동지점'),
SUBPARTITION lst_02 VALUES ('부산지점', '대전지점'),
SUBPARTITION lst_03 VALUES ('인천지점', '제주지점', '의정부지점'),
SUBPARTITION lst_99 VALUES (DEFAULT)
) (
PARTITION p2009_q1 VALUES LESS THAN ('20090401'),
PARTITION p2009_q2 VALUES LESS THAN ('20090701'),
PARTITION p2009_q3 VALUES LESS THAN ('20091001'),
PARTITION p2009_q4 VALUES LESS THAN ('20100101')
);
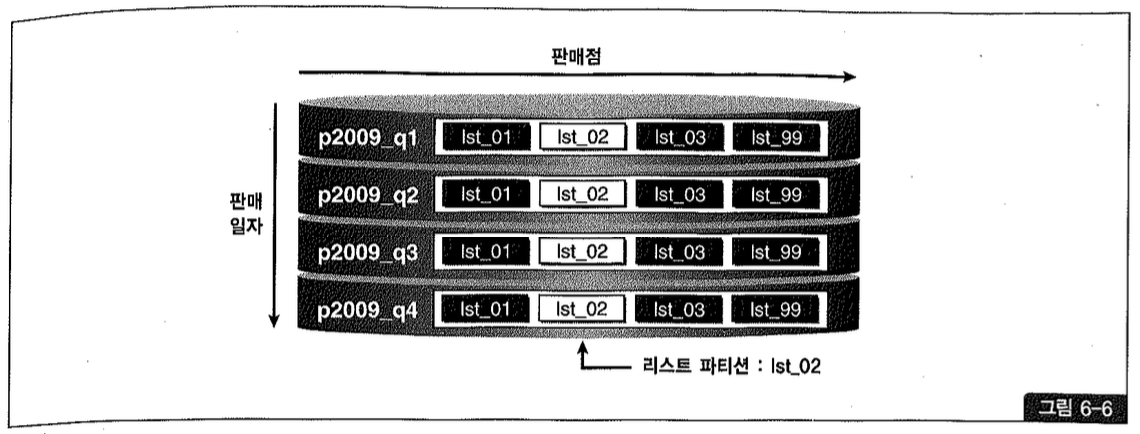
각 Range 파티션 내에서 사용자가 지정한 그룹핑 기준에 따라 각 리스트 서브 파티션으로 데이터를 분할 저장한 것을 볼 수 있다. Range 파티셔닝과 리스트 파티셔닝의 이점을 둘 다 누릴 수 있는 이유이다.
이 결합 파티셔닝 전략은 초대형 이력성 테이블을 Range 파티셔닝하고, 각 파티션을 업무적으로 다시 분할하고자 할 때 주로 사용된다. 예를 들어, 의류, 식품, 가전, 생활용품 각각에 특화된 인터넷 쇼핑몰을 하나의 시스템으로 통합(상품 대분류로 구분)한다고 하자. 그런데 조직과 시스템을 통합하더라도 조회 및 트랜잭션은 기존처럼 독립적으로(상품 대분류별로) 일어난다.
그럴 때, 상품 테이블은 상품 대분류 기준으로 리스트 파티셔닝하고, 주문과 주문 상세 테이블 등은 주문 일자와 상품 대분류 기준으로 Range + 리스트 형태로 파티셔닝하는 전략이 효과적이다. 논리적으로 하나의 테이블이지만 물리적으로 별도 세그먼트에 나누어 저장되기 때문에 성능을 떨어뜨리지 않으면서 통합의 이점을 누릴 수 있는 것이다.
또 다른 예로서, 전국 초중고 학생의 학사 및 수험 정보를 관리하는 시스템이 있다고 하자. 각 시도별로 1:1 리스트 파티셔닝할 수도 있지만, 데이터 분포에 따라 논리적인 그룹을 만들어 그룹별로 파티션을 할당하는 방식을 사용할 수 있다. 즉, 학생 수가 가장 많은 서울시, 경기도는 각각 하나의 파티션을 할당하고 나머지는 몇 시도를 적절히 묶어서 관리하는 방식을 말한다.
이처럼 학생 정보는 시도별로 리스트 파티셔닝하고, 수험 정보 같은 기간별 데이터는 수험 일시와 시도 기준으로 Range + 리스트 형태의 결합 파티셔닝을 도입하면 효과적이다.
기타 결합 파티셔닝
11g부터 아래 네 가지 형태의 결합 파티셔닝 기능이 추가되었다. 따라서 주 파티션이 해시 방식이 아닌 모든 조합이 가능해졌다.
- Range-Range
- 리스트-해시
- 리스트-리스트
- 리스트-Range
(6) 11g에 추가된 파티션 유형
Reference 파티셔닝
그림 6-7과 같은 데이터 모델이 있다고 하자.
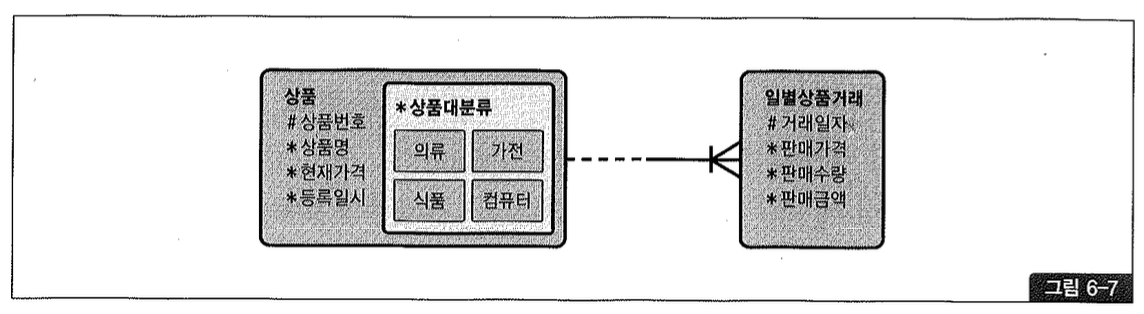
상품 테이블을 상품 대분류 기준으로 리스트 파티셔닝하고, 일별 상품 거래 테이블도 부모 테이블인 상품과 똑같은 방식과 기준으로 파티셔닝하려고 한다. 이럴 때 10g까지는 상품에 있는 상품 대분류 컬럼을 일별 상품 거래 테이블에 반정규화(상품 번호에 종속적인 컬럼이므로 2차 정규형 위배)해야만 했다.
이 문제를 해소하려고 11g에서 부모 테이블 파티션 키를 이용해 자식 테이블을 파티셔닝하는 기능이 도입되었는데, 이를 Reference 파티셔닝이라고 부른다.
아래 스크립트에 굵은 글씨체로 표시한 것처럼 이 기능을 사용하려면 일별 상품 거래 테이블의 상품 번호 컬럼에 not null과 FK 제약이 설정되어 있어야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
CREATE TABLE 상품 (
상품번호 NUMBER NOT NULL PRIMARY KEY,
상품명 VARCHAR2(50) NOT NULL,
현재가격 NUMBER NOT NULL,
상품대분류 VARCHAR2(4) NOT NULL,
등록일시 DATE NOT NULL
)
PARTITION BY LIST(상품대분류) (
PARTITION p1 VALUES ('의류'),
PARTITION p2 VALUES ('식품'),
PARTITION p3 VALUES ('가전'),
PARTITION p4 VALUES ('컴퓨터')
);
CREATE TABLE 일별상품거래 (
상품번호 NUMBER NOT NULL,
거래일자 VARCHAR2(8),
판매가격 NUMBER,
판매수량 NUMBER,
판매금액 NUMBER,
CONSTRAINT 일별상품거래_fk FOREIGN KEY (상품번호) REFERENCES 상품(상품번호)
)
PARTITION BY REFERENCE (일별상품거래_fk);
Interval 파티셔닝
11g부터는 Range 파티션을 생성할 때 아래와 같이 interval 기준을 정의함으로써 정해진 간격으로 파티션이 자동 추가되도록 할 수 있다. 특히 테이블을 일 단위로 파티셔닝했을 때 유용하다.
1
2
3
4
5
6
7
8
9
10
CREATE TABLE 주문 (
주문번호 NUMBER,
주문일시 DATE
)
PARTITION BY RANGE (주문일시)
INTERVAL (NUMTOYMINTERVAL(1, 'MONTH')) (
PARTITION p200908 VALUES LESS THAN (TO_DATE('2009/09/01', 'yyyy/mm/dd')),
PARTITION p200909 VALUES LESS THAN (TO_DATE('2009/10/01', 'yyyy/mm/dd')),
PARTITION p200910 VALUES LESS THAN (TO_DATE('2009/11/01', 'yyyy/mm/dd'))
);
아래와 같이 가입 고객 수가 10만 명을 넘을 때마다 고객 테이블에 파티션이 추가되도록 할 수도 있다.
1
2
3
4
5
6
7
8
9
10
CREATE TABLE 고객 (
고객번호 NUMBER,
고객명 VARCHAR2(20)
)
PARTITION BY RANGE (고객번호)
INTERVAL (100000) (
PARTITION p_cust1 VALUES LESS THAN (100001),
PARTITION p_cust2 VALUES LESS THAN (200001),
PARTITION p_cust3 VALUES LESS THAN (300001)
);
이 외에도 시스템 파티셔닝, 가상(Virtual) 컬럼 기반 파티셔닝 등이 11g에 추가되었는데, 이들 기능에 대한 자세한 설명은 오라클 매뉴얼을 참고하기 바란다.