<오라클 성능 고도화 원리와 해법2> Ch06-02 파티션 Pruning
오라클 성능 고도화 원리와 해법2 - Ch06-02 파티션 Pruning
‘Prune’은 ‘쓸데없는 가지를 치다’, ‘불필요한 부분을 제거하다’라는 뜻이다. 용어에서 알 수 있듯이, 파티션 프루닝(Pruning)은 하드 파싱이나 실행 시점에 SQL 조건절을 분석하여 읽지 않아도 되는 파티션 세그먼트를 액세스 대상에서 제외시키는 기능이다. 파티션 테이블에 대한 쿼리나 DML을 수행할 때 극적인 성능 개선을 가져다주는 핵심 원리가 파티션 프루닝에 있다.
기본 파티션 프루닝 기법을 먼저 설명하고, 고급 파티션 프루닝 기법으로서 서브쿼리 프루닝(Subquery Pruning)과 조인 필터 프루닝(Join Filter Pruning)을 이어서 설명한다.
(1) 기본 파티션 프루닝
기본 파티션 프루닝 기법으로는 아래 두 가지가 있다.
- 정적(Static) 파티션 프루닝: 파티션 키 컬럼을 상수 조건으로 조회하는 경우에 작동하며, 액세스할 파티션이 쿼리 최적화 시점에 미리 결정되는 것이 특징이다. 실행 계획의 pstart (partition start)와 pstop (partition stop) 컬럼에는 액세스할 파티션 번호가 출력된다.
- 동적(Dynamic) 파티션 프루닝: 파티션 키 컬럼을 바인드 변수로 조회하면 쿼리 최적화 시점에는 액세스할 파티션을 미리 결정할 수 없다. 실행 시점이 돼서야 사용자가 입력한 값에 따라 결정되며, 실행 계획의 pstart와 pstop 컬럼에는 ‘KEY’라고 표시된다. NL 조인할 때도 Inner 테이블이 조인 컬럼 기준으로 파티셔닝돼 있다면 동적 프루닝이 작동한다.
동적 파티션 프루닝 시 테이블 레벨 통계 사용
바인드 변수를 사용하면 최적화 시점에 파티션을 확정할 수 없어 동적 파티션 프루닝이 일어난다. 같은 이유로 쿼리 최적화에 테이블 레벨 통계가 사용된다. 반면, 정적 파티션 프루닝일 때는 파티션 레벨 통계가 사용된다.
테이블 레벨 통계는 파티션 레벨 통계보다 다소 부정확하기 때문에 옵티마이저가 가끔 잘못된 실행 계획을 수립하는 경우가 생기며, 이는 바인드 변수 때문에 생기는 대표적인 부작용 중 하나다.
(2) 서브쿼리 Pruning
조인에 사용되는 고급 파티션 프루닝 기법으로는 아래 두 가지가 있다.
- 서브쿼리 프루닝(8i~)
- 조인 필터 프루닝(11g~)
우선 서브쿼리 프루닝부터 살펴보겠다. 아래와 같은 쿼리가 있다고 하자.
1
2
3
4
SELECT d.분기, o.주문일자, o.고객ID, o.상품ID, o.주문수량, o.주문금액
FROM 일자 d, 주문 o
WHERE o.주문일자 = d.일자
AND d.분기 >= 'Q20071';
NL 조인할 때 Inner 테이블이 조인 컬럼 기준으로 파티셔닝돼 있다면 동적 프루닝이 작동한다고 했다. 주문은 대용량 거래 테이블이므로 주문 일자 기준으로 월별 Range 파티셔닝돼 있을 것이고, 일자 테이블을 드라이빙해 NL 조인하면 분기 >= ‘Q20071’ 기간에 포함되는 주문 레코드만 읽을 수 있다.
하지만 대용량 주문 테이블을 랜덤 액세스 위주의 NL 방식으로 조인한다면 결코 좋은 성능을 기대하기 어렵다. 그렇다고 해시 조인이나 소트 머지 조인으로 처리하기도 부담스럽다. 2007년 1분기 이후 주문 데이터만 필요한데도 주문 테이블로부터 모든 파티션을 읽어 조인하고 나중에 분기 조건을 필터링해야 하기 때문이다.
이럴 때 오라클은 리커시브 서브쿼리를 이용한 동적 파티션 프루닝을 고려한다. 이른바 ‘서브쿼리 프루닝’이라고 불리는 메커니즘으로, 위 쿼리에 대해 내부적으로 아래와 같은 서브쿼리가 수행된다. (수행 가능한 쿼리이므로 직접 테스트해보기 바란다.)
1
2
3
SELECT DISTINCT DBMS_ROWID.rowid_partition('주문', o.rowid)
FROM (SELECT 일자 FROM 일자 WHERE 분기 >= 'Q20071') a
ORDER BY 1;
이 쿼리를 수행하면 액세스해야 할 파티션 번호 목록이 구해지며, 이를 이용해 필요한 주문 파티션만 스캔할 수 있다.
이 방식으로 파티션을 프루닝하려면 드라이빙 테이블을 한 번 더 읽게 되므로 경우에 따라 총 비용이 오히려 증가할 수 있다. 따라서 서브쿼리 프루닝 적용 여부는 옵티마이저가 비용을 고려해 내부적으로 결정한다. 옵티마이저 결정에 영향을 미치는 히든 파라미터는 아래와 같다.
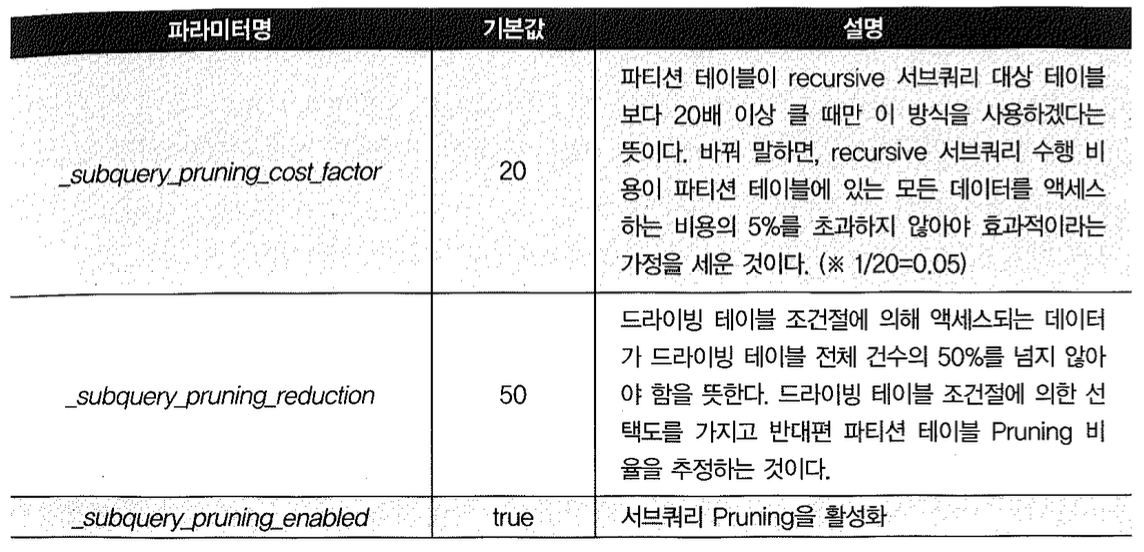
제거될 것으로 예상되는 파티션 개수가 상당히 많고(기본값에 의하면 50%), where 조건절을 가진 드라이빙 테이블이 파티션 테이블에 비해 상당히 작을 때만 서브쿼리 프루닝이 작동한다.
참고로, 아래와 같이 설정하면 옵티마이저에 의해 계산된 비용과 상관없이 항상 서브쿼리 프루닝을 실시한다.
_subquery_pruning_cost_factor = 1_subquery_pruning_reduction = 10
(3) 조인 필터 Pruning
서브쿼리 프루닝은 드라이빙 테이블을 한 번 더 액세스하는 추가 비용이 발생한다. 그래서 11g부터 오라클은 블룸 필터(Bloom Filter) 알고리즘을 기반으로 한 조인 필터(Join Filter, Bloom Filter) 프루닝 방식을 도입하였다.
블룸 필터(Bloom Filter) 알고리즘
먼저 블룸 필터 알고리즘에 대해 살펴보자. 아래 내용은 스위스 취리히 Trivadis에서 컨설턴트로 활약 중인 Christian Antognini의 설명을 바탕으로 재구성한 것이다. 블룸 필터에 대한 더 자세한 설명은 Wikipedia - Bloom_filter에서 얻을 수 있다.
아래처럼 A, B 두 개의 집합이 있고, 두 집합 간의 교집합을 찾으려고 한다.
집합 A = { 175, 442, 618 } 집합 B = { 175, 327, 432, 548 }
여기서는 원소가 각각 3개, 4개밖에 없어서 육안으로도 쉽게 찾을 수 있지만, 각각 10,000개씩이라면 어떻게 할까? 집합 B에 있는 각 원소마다 집합 A를 뒤지면서 같은 값을 가진 원소가 있는지 확인해봐야 한다. 교집합이 크다면 많은 일량에도 불구하고 비효율은 없다고 할 수 있다. 하지만 교집합이 매우 작다면 이 방식은 비효율적이다. 지금 설명하려는 블룸 필터는 교집합이 작을 때 큰 효과를 발휘하며, 기본 알고리즘은 다음과 같다.
- n 비트 배열을 할당하고(각 비트를 0으로 설정한다.
- 1개의 값을 리턴하는 m개의 해시 함수를 정의하며, 서로 다른 해시 알고리즘을 사용한다. m개의 해시 함수는 다른 입력 값에 대해 우연히 같은 출력 값을 낼 수도 있다. 심지어 같은 알고리즘을 사용하더라도 다른 입력 값에 대해 같은 출력 값을 낼 수 있는 것이 해시 함수의 특징이다.
- 집합 A의 각 원소마다 차례로 1개의 해시 함수를 모두 적용한다. 그리고 각 해시 함수에 리턴된 값에 해당하는 비트를 모두 1로 설정한다.
- 교집합을 찾을 준비가 끝났다. 이제 집합 B의 각 원소마다 차례로 1개의 해시 함수를 모두 적용한다. 그리고 원소별로 해시 함수에서 리턴된 값에 해당하는 비트를 모두 확인한다.
- 하나라도 0으로 설정돼있으면 그 원소는 집합 A에 없는 값이다. 잘못된 음수(false negative)는 불가능하기 때문이다. 즉, 집합 A에 있는 값인데 0으로 남았을 리가 없다.
- 모두 1로 설정돼있으면 그 원소는 집합 A에 포함될 가능성이 있는 값이므로 이때만 집합 A를 찾아가 실제 같은 값을 가진 원소가 있는지 찾아본다. 모두 1로 설정돼있는데도 집합 A에 실제 그 값이 있는지 확인해야 하는 이유는 잘못된 양수(false positive)가 가능하기 때문이다. 즉, 집합 A에 없는 값인데 모두 1로 설정될 수 있다.
블룸 필터 알고리즘에서 false positive를 줄이는 방법
집합 B의 원소 548에서 false positive가 발생해 불필요하게 집합 A를 확인해야만 했다. 10비트보다 큰 100비트 배열을 사용하면 어떤 결과가 나올까?
이처럼 더 많은 비트를 할당(더 많은 공간 필요)하거나 더 많은 해시 함수를 사용(더 많은 시간을 소비)하면 false positive 발생 가능성은 줄어든다. 공간/시간의 효율성과 false positive 발생 가능성은 서로 트레이드오프(Trade-off) 관계이므로 적정한 개수의 비트와 해시 함수를 사용하는 것이 과제다.
조인 필터(=블룸 필터) Pruning
지금까지 블룸 필터 알고리즘에 대해 비교적 자세히 설명하였다. 오라클은 성능 향상을 위해 여러 곳에 이 알고리즘을 사용하고 있는데, 그중 대표적인 것이 파티션 프루닝이다. 11g부터 적용되기 시작한 이 기능은 파티션 테이블과 조인할 때, 읽지 않아도 되는 파티션을 제거해주는 것으로서 ‘조인 필터 Pruning’ 또는 ‘블룸 필터 Pruning’이라고 부른다.
앞에서 서브쿼리 파티션 프루닝에서 보았던 쿼리에 이 기능을 적용하면 실행 계획에 어떤 변화가 생기는지 살펴보자.
1
2
3
4
SELECT d.분기, o.주문일자, o.고객ID, o.상품ID, o.주문수량, o.주문금액
FROM 일자 d, 주문 o
WHERE o.주문일자 = d.일자
AND d.분기 >= 'Q20071';
실행 계획은 다음과 같다.
1
2
3
4
5
6
7
Rows Row Source Operation
------ -------------------------------------------------
480591 HASH JOIN (cr=3827 pr=0 pw=0 time=4946 us cost=655 size=21002700 ... )
12 PART JOIN FILTER CREATE :BF0000 (cr=4 pr=0 pw=0 time=18 us cost=4 ... )
12 TABLE ACCESS FULL (cr=4 pr=0 pw=0 time=6 us cost=4 size=10388)
480591 PARTITION RANGE JOIN-FILTER :BF0000 :BF0000 (cr=3823 pr=0)
TABLE ACCESS FULL PARTITION :BF0000 :BF0000 (cr=3823 pr=0)
part join filter create와 partition range join-filter를 포함하는 두 개의 오퍼레이션 단계가 눈에 띈다. 전자는 블룸 필터를 생성하는 단계이고, 후자는 블룸 필터를 이용해 파티션 Pruning하는 단계를 나타낸다. 좀 더 풀어서 설명하면 다음과 같다.
- 일자 테이블로부터
분기 >= 'Q20071'조건에 해당하는 레코드를 읽어 해시 테이블을 만들면서 블룸 필터를 생성한다. 즉, 조인 컬럼인 일자 값에 매핑되는 주문 테이블 파티션 번호를 찾아 n개의 해시 함수에 입력하고, 거기서 출력된 값을 이용해 비트 값을 설정한다. - 일자 테이블을 다 읽고 나면 주문 테이블의 파티션 번호별로 비트 값을 확인함으로써 읽지 않아도 되는 파티션 목록을 취합한다.
- 취합된 파티션을 제외한 나머지 파티션만 읽어 조인한다.
다시 말하지만 블룸 필터의 역할은 교집합이 아님이 확실한 원소를 찾는 데 있다. 이 알고리즘을 사용하는 조인 필터 Pruning도 조인 대상 집합을 확실히 포함하는 파티션을 찾는 것이 아니라, 확실히 포함하지 않는 파티션을 찾는다. 그런 후 그 파티션 목록을 제외한 나머지 파티션만 스캔한다.
위 쿼리는 기본적으로 2007년 1월부터 현재까지의 파티션만 읽지만, false positive가 발생해 그 이전 파티션 중 일부를 불필요하게 읽을 가능성은 있다. 하지만 이런 고급 파티션 프루닝 기법을 활용하지 않았을 때 모든 파티션을 읽는 것에 비하면 훨씬 효율적이다. 서브쿼리 프루닝과 비교해보면, 드라이빙 테이블이 클수록 조인 필터 Pruning이 유리하다.
만약 조인 필터 Pruning 기능을 비활성화하고 싶다면, bloom_pruning_enabled 파라미터를 false로 설정하면 된다.
(4) SQL 조건절 작성 시 주의사항
고객 테이블을 아래처럼 가입일 기준으로 Range 월 파티셔닝하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
CREATE TABLE 고객 (
고객ID NUMBER,
고객명 VARCHAR2(20),
가입일 DATE
)
PARTITION BY RANGE(가입일) (
PARTITION m01 VALUES LESS THAN ('20090201'),
PARTITION m02 VALUES LESS THAN ('20090301'),
PARTITION m03 VALUES LESS THAN ('20090401'),
PARTITION m04 VALUES LESS THAN ('20090501'),
PARTITION m05 VALUES LESS THAN ('20090601'),
PARTITION m06 VALUES LESS THAN ('20090701'),
PARTITION m07 VALUES LESS THAN ('20090801'),
PARTITION m08 VALUES LESS THAN ('20090901'),
PARTITION m09 VALUES LESS THAN ('20091001'),
PARTITION m10 VALUES LESS THAN ('20091101'),
PARTITION m11 VALUES LESS THAN ('20091201'),
PARTITION m12 VALUES LESS THAN ('20100101')
) AS
SELECT ROWNUM 고객ID,
DBMS_RANDOM.STRING('a', 20) 고객명,
TO_CHAR(TO_DATE('20090101', 'yyyymmdd') + (ROWNUM - 1), 'yyyymmdd') 가입일
FROM dual
CONNECT BY LEVEL <= 365;
아래처럼 2009년 10월에 가입한 고객을 조회할 때 like 연산자를 사용했더니 두 개(9~10번) 파티션을 스캔하는 것을 볼 수 있다. 왜 m10 파티션만 읽지 않고 m09 파티션까지 읽은 것일까?
1
2
SELECT * FROM 고객
WHERE 가입일 LIKE '200910%';
실행 계획은 다음과 같다.
1
2
3
4
5
6
7
----------------------------------------------------------------------
Id | Operation | Name | Rows | Bytes | Pstart | Pstop
----------------------------------------------------------------------
0 | SELECT STATEMENT | | 31 | 62651 | |
1 | PARTITION RANGE ITERATOR | | 31 | 62651 | 9 | 10
2 | TABLE ACCESS FULL | 고객 | 31 | 62651 | 9 | 10
----------------------------------------------------------------------
20091001보다 작은 여러 문자열이 존재할 수 있다. 예를 들어, 다음과 같은 값들이 있다면 이 값들이 입력될 경우 파티션 정의상 2009년 10월 파티션(m09)에 저장된다.
- 200910, 20091000, …
- 2009100+, 2009100-, 2009100*, 2009100/, …
- 2009100%, 2009100$, 2009100#, …
이 상태에서 LIKE '200910%' 조건으로 검색하면 이러한 값들까지 모두 결과 집합에 포함시켜야 하므로 옵티마이저는 m09 파티션을 스캔할 수밖에 없다. 사용자가 이러한 값들을 입력하지 않더라도 옵티마이저 입장에서는 알 수 없는 일이다.
따라서 위와 같이 (월이 아닌) 일자로 파티션 키 값을 정의했다면 아래와 같이 BETWEEN 연산자를 이용해 정확한 값 범위를 주고 쿼리해야 한다.
1
2
SELECT * FROM 고객
WHERE 가입일 BETWEEN '20091001' AND '20091031';
실행 계획은 다음과 같다.
1
2
3
4
5
6
7
----------------------------------------------------------------------
Id | Operation | Name | Rows | Bytes | Pstart | Pstop
----------------------------------------------------------------------
0 | SELECT STATEMENT | | 31 | 62651 | |
1 | PARTITION RANGE SINGLE | | 31 | 62651 | 10 | 10
2 | TABLE ACCESS FULL | 고객 | 31 | 62651 | 10 | 10
----------------------------------------------------------------------
1장 7절 인덱스 스캔 효율화 원리에서 like 보다 between이 유리한 이유를 설명했는데, 지금 본 것처럼 파티션 Pruning을 위해서라도 LIKE보다는 가급적 BETWEEN 연산자를 이용해 정확한 검색 구간을 지정하는 것이 바람직하다.
위와 같은 상황에서, 만약 SQL을 일일이 수정하기 어렵다면 아래처럼 연월(yyyymm)로 파티션 키 값을 다시 정의해 주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
CREATE TABLE 고객 (
고객ID NUMBER,
고객명 VARCHAR2(20),
가입일 VARCHAR2(6)
)
PARTITION BY RANGE(가입일) (
PARTITION m01 VALUES LESS THAN ('200902'),
PARTITION m02 VALUES LESS THAN ('200903'),
...,
...,
PARTITION m11 VALUES LESS THAN ('200912'),
PARTITION m12 VALUES LESS THAN ('201001')
) AS
SELECT ROWNUM 고객ID,
DBMS_RANDOM.STRING('a', 20) 고객명,
TO_CHAR(TO_DATE('20090101', 'yyyymmdd') + (ROWNUM - 1), 'yyyymm') 가입일
FROM dual
CONNECT BY LEVEL <= 365;
이제 LIKE로 검색하더라도 아래처럼 정확히 m10 파티션만 스캔한다. BETWEEN 연산자는 이때도 정확한 파티션 프루닝이 일어난다. 다시 강조하지만, 파티션 설계와 상관없이 옵티마이저가 효율적인 선택을 할 수 있도록 하려면 BETWEEN 연산자를 사용하기 바란다.
1
2
SELECT * FROM 고객
WHERE 가입일 LIKE '200910%';
| Id | Operation | Name | Rows | Bytes | Pstart | Pstop |
|---|---|---|---|---|---|---|
| 0 | SELECT STATEMENT | 31 | 62651 | |||
| 1 | PARTITION RANGE SINGLE | 31 | 62651 | 10 | 10 | |
| 2 | TABLE ACCESS FULL | 고객 | 31 | 62651 | 10 | 10 |