<오라클 성능 고도화 원리와 해법2> Ch06-03 인덱스 파티셔닝
오라클 성능 고도화 원리와 해법2 - Ch06-03 인덱스 파티셔닝
(1) 인덱스 파티션 유형
테이블 파티셔닝에 대해 살펴봤고, 이제는 인덱스 파티셔닝에 대해 설명하려고 한다. 인덱스 파티셔닝은 테이블 파티셔닝과 맞물려 다양한 구성이 존재한다. 따라서 테이블을 다음과 같이 구분하고서 인덱스 파티션 유형에 대한 설명을 시작해야 한다.
- 비파티션 테이블 (Non-Partitioned Table)
- 파티션 테이블 (Partitioned Table)
인덱스도 테이블처럼 파티션 여부에 따라 비파티션 인덱스와 파티션 인덱스로 나뉘며, 파티션 인덱스는 각 인덱스 파티션이 담당하는 테이블 파티션 범위에 따라 글로벌과 로컬로 나뉜다.
- 비파티션 인덱스 (Non-Partitioned Index)
- 글로벌 파티션 인덱스 (Global Partitioned Index)
- 로컬 파티션 인덱스 (Local Partitioned Index)
뒤에서 다시 설명하겠지만 로컬 파티션 인덱스는 각 테이블 파티션과 인덱스 파티션이 서로 1:1 대응 관계가 되도록 오라클이 자동으로 관리하는 파티션 인덱스를 말한다. 로컬이 아닌 파티션 인덱스는 모두 글로벌 파티션 인덱스에 속하며, 테이블 파티션과 독립적인 구성(파티션 키, 파티션 기준 값)을 갖는다.
참고로, 인덱스를 글로벌과 로컬로 먼저 나누고, 글로벌을 다시 파티션과 비파티션으로 나누는 분류 방식도 있다. 이때는 비파티션 인덱스를 ‘글로벌 비파티션 인덱스 (Global Non-Partitioned Index)’라고 부른다.
이 책에서는 처음 설명한 분류 방식을 사용하지만, 편의상 ‘글로벌 인덱스 (Global Index)’라고 줄여 부를 때는 비파티션 인덱스와 글로벌 파티션 인덱스를 같이 일컫는 말임을 미리 밝힌다.
- 글로벌 인덱스 = 비파티션 인덱스 + 글로벌 파티션 인덱스
이제 테이블과 인덱스 파티셔닝 구분을 서로 조합해보면 아래와 같은 구성이 생긴다.
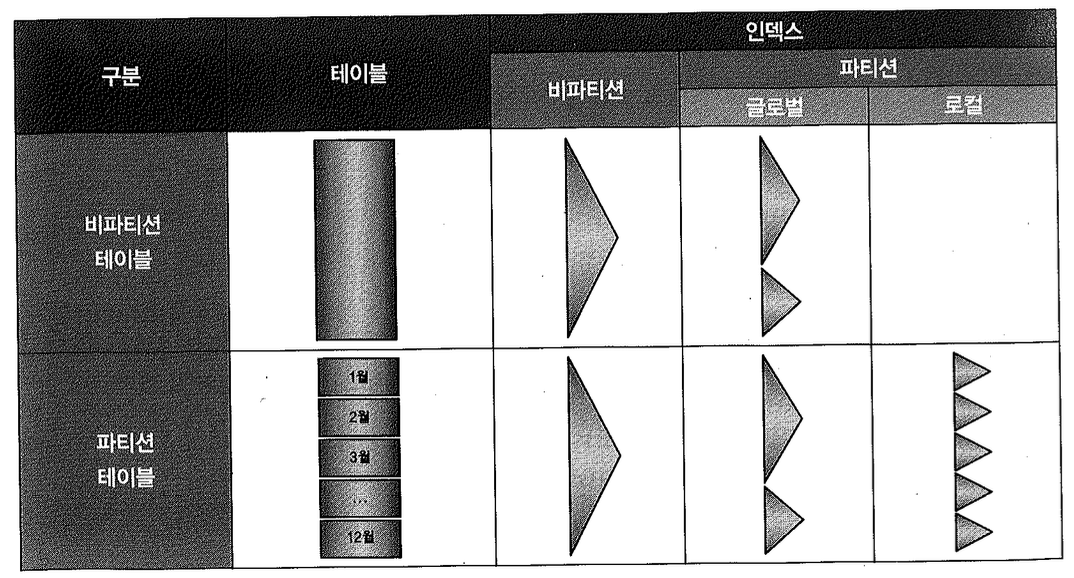
- 비파티션 테이블은 비파티션 인덱스와 글로벌 파티션 인덱스를 가질 수 있다.
- 파티션 테이블은 비파티션 인덱스, 글로벌 파티션 인덱스, 로컬 파티션 인덱스를 가질 수 있다.
참고로, 비파티션 테이블에 대한 비트맵 인덱스는 파티셔닝이 허용되지 않으며, 파티션 테이블에 대한 비트맵 인덱스는 로컬 파티셔닝만 허용된다.
(2) 로컬 파티션 인덱스
이 장을 시작하면서 테이블 파티션을 계절별로 옷을 관리하는 서랍장에 비유했는데, 로컬 파티션 인덱스(Local Partitioned Index)는 계절별로 별도 색인을 다는 것과 같다. 따라서 각 인덱스 파티션이 테이블 파티션과 1:1 대응 관계를 가지며, 테이블 파티션 속성을 그대로 상속받는다. 파티셔닝을 전제로 하므로 흔히 ‘로컬 인덱스’라고 줄여서 부른다.
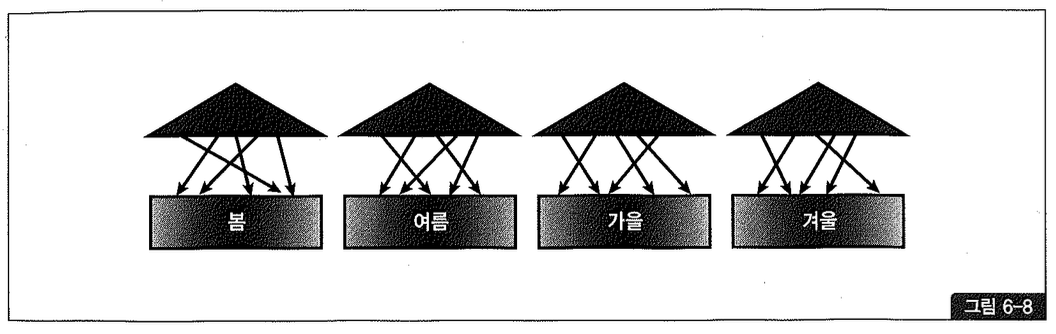
파티션 키를 사용자가 따로 정의하지 않아도 오라클이 자동으로 관리한다는 것이 특징이다. 테이블 파티션과 1:1 관계가 되도록 사용자가 수동으로 인덱스 파티션을 구성하더라도 이를 로컬 파티션 인덱스라고 부르지 않는 이유가 여기에 있다.
로컬 파티션 인덱스는 항상 테이블 파티션과 1:1 관계를 형성하므로 만약 테이블이 결합 파티셔닝(Composite Partitioning)되어 있다면 인덱스도 같은 단위로 파티셔닝된다.
로컬 파티션 인덱스가 갖는 장점은 무엇보다 관리적 편의성에 있다. 테이블 파티션 구성에 변경(drop, exchange, split 등)이 생기더라도 인덱스를 재생성할 필요가 없어 관리 비용이 아주 적다.
(3) 비파티션 인덱스
비파티션 인덱스(Non-Partitioned Index)는 말 그대로 파티셔닝하지 않은 인덱스를 말한다. 테이블이 파티셔닝돼있다면 그림 6-9에서 보듯이 1:M 관계에 놓인다. 즉, 하나의 인덱스 세그먼트가 여러 테이블 파티션 세그먼트와 관계를 갖는다. 그런 의미에서 비파티션 인덱스를 ‘글로벌 비파티션 인덱스’라고 부르기도 한다.
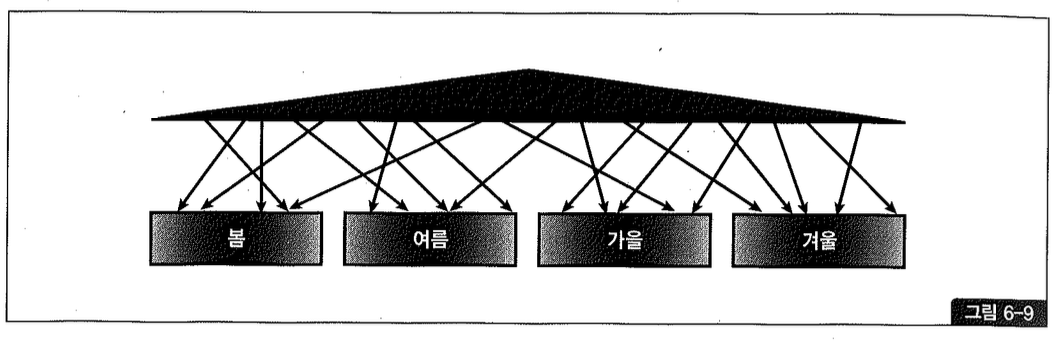
(4) 글로벌 파티션 인덱스
글로벌 파티션 인덱스(Global Partitioned Index)는 그림 6-10에서 보는 것처럼 테이블 파티션과 독립적인 구성을 갖도록 파티셔닝하는 것을 말한다. 테이블은 파티셔닝돼있지 않을 수도 있다.
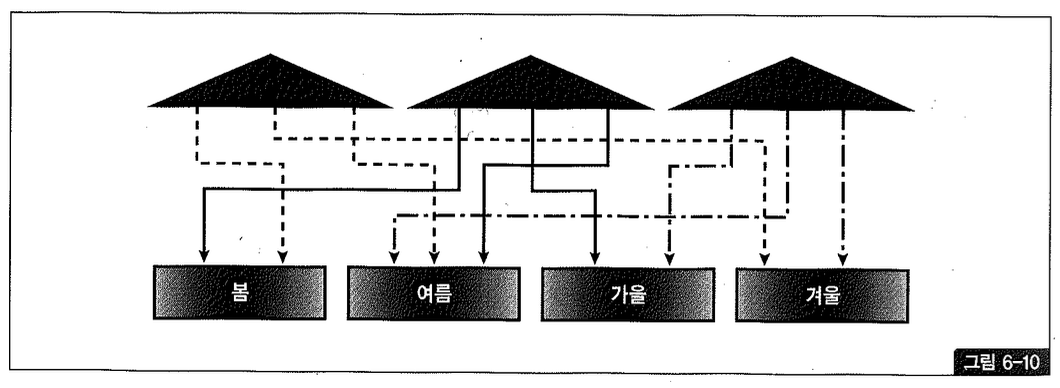
독립적 구성이라는 점에서 효용성이 높을 것처럼 보이지만, 몇몇 제약 사항 때문에 오히려 효용성이 낮은 편이다. 글로벌 파티션 인덱스 사용을 불편하게 만드는 가장 큰 제약은 기준 테이블의 파티션 구성에 변경(drop, exchange, split 등)이 생길 때마다 인덱스가 unusable 상태로 바뀌고 그때마다 인덱스를 재생성해야 한다는 것이다. 이 제약은 비파티션 인덱스일 때도 똑같이 나타난다.
9i부터는 아래와 같이 update global indexes 옵션을 주면 파티션 DDL 작업에 의해 영향을 받는 인덱스 레코드를 자동으로 갱신해주므로 인덱스가 unusable 상태로 빠지지 않는다.
1
2
3
ALTER TABLE ...
SPLIT PARTITION ...
UPDATE GLOBAL INDEXES;
하지만, 파티션 DDL로 인해 영향을 받는 레코드가 전체의 5% 미만일 때만 유용하다. 다시 말해, 5% 이상일 때는 인덱스를 재생성하는 것보다 오히려 늦다는 뜻이다. (항상 들어맞는 수치는 아니며, 평균적으로 그렇다는 것이다. 인덱스 손익분기점과 같은 개념으로 이해하면 된다.)
테이블 파티션과의 관계
“오라클이 자동으로 관리해주는 1:1 관계”가 아닌 파티션 인덱스는 모두 글로벌 파티션 인덱스라고 설명했다.
인덱스를 테이블 파티션과 같은 키 컬럼으로 글로벌 파티셔닝한다면 파티션 기준값을 어떻게 정의하느냐에 따라 1:M, M:1, M:M 관계가 모두 가능하다. 그렇더라도 본질적인 관계는 M:M으로 이해해야 한다. 즉, 하나의 인덱스 파티션이 여러 테이블 파티션과 관계를 갖고, 반대로 하나의 테이블 파티션이 여러 인덱스 파티션과 관계를 갖는다. M:M은 다른 모든 관계를 포함한다는 사실을 상기하기 바란다.
참고로, 로컬 파티션 인덱스(그림 6-8)처럼 테이블과 1:1 관계가 되도록 수동으로 구성하더라도 여느 글로벌 파티션과 마찬가지로 기준 테이블 구성에 변경이 발생할 때마다 인덱스를 재생성해야 한다.
인덱스를 테이블 파티션과 다른 키 컬럼으로 글로벌 파티셔닝할 수도 있는데, 예를 들어 테이블은 주문일자, 인덱스는 배송일자에 따라 파티셔닝할 수 있다. 이때는 테이블 파티션과 인덱스 파티션 간에는 항상 M:M 관계가 형성된다.
글로벌 해시 파티션 인덱스
글로벌 파티션 인덱스의 경우, 9i까지는 글로벌 Range 파티션만 가능했지만 10g부터는 글로벌 해시 파티션도 가능해졌다. 즉, 테이블과 독립적으로 인덱스만 해시 키 값에 따라 파티셔닝할 수 있게 되었다. 글로벌 해시 파티션 인덱스는 Right Growing 인덱스처럼 Hot 블록이 발생하는 인덱스의 경합을 분산할 목적으로 주로 사용된다. 글로벌 결합(Composite) 인덱스 파티셔닝은 여전히 불가능하다.
(5) Prefixed vs. Non-Prefixed
파티션 인덱스를 Prefixed와 Non-Prefixed로 나눌 수 있다. 이는 인덱스 파티션 키 컬럼이 인덱스 구성상 왼쪽 선두 컬럼에 위치하는지에 따른 구분이다.
- Prefixed: 파티션 인덱스를 생성할 때, 파티션 키 컬럼을 인덱스 키 컬럼 왼쪽 선두에 두는 것을 말한다.
- Non-Prefixed: 파티션 인덱스를 생성할 때, 파티션 키 컬럼을 인덱스 키 컬럼 왼쪽 선두에 두지 않는 것을 말한다. 파티션 키가 인덱스 컬럼에 아예 속하지 않을 때도 여기에 속한다.
로컬과 글로벌, Prefixed와 Non-Prefixed를 조합하면 아래 4가지 구성이 나온다.

글로벌 파티션 인덱스는 Prefixed 파티션만 지원되므로 결과적으로 세 개의 파티션 인덱스가 있고, 비파티션 인덱스를 포함해 아래 네 가지 유형으로 최종 정리할 수 있다.
- 비파티션 인덱스
- 글로벌 Prefixed 파티션 인덱스
- 로컬 Prefixed 파티션 인덱스
- 로컬 Non-Prefixed 파티션 인덱스
(6) 파티션 인덱스 구성 예시
파티션 인덱스 유형별 구성 예시를 요약하면 아래 표와 같다.

글로벌 Non-Prefixed 파티션 인덱스는 지원되지 않지만, 지원된다면 아래와 같은 구성일 것이다.

인덱스 파티셔닝을 공부할 때면 누구나 어렵고 복잡하다고 느낀다. 처음에는 로컬, 글로벌을 구분하기도 쉽지 않은데 여기에 Prefixed, Non-Prefixed 개념까지 더해지니 그럴 수밖에 없다. 이들 구성과 액세스 유형에 따라 성능에 많은 차이가 생기므로, 반드시 넘어야 할 산이라는 각오로 이 기회에 개념과 구조를 정확히 이해하기 바란다.
인덱스 파티셔닝 예제
1
2
3
4
5
SQL> create unique index t_idx1 on t(gubun, seq2) LOCAL;
create unique index t_idx1 on t(gubun, seq2) LOCAL
ERROR at line 1:
ORA-14039: partitioning columns must form a subset of key columns of a UNIQUE index
위 CREATE INDEX 문에 에러가 발생한 이유가 무엇일까? 뒤에서 다시 설명하겠지만 Unique 파티션 인덱스를 만들 때는 파티션 키 컬럼이 인덱스 컬럼에 포함돼 있어야 하기 때문이다. 방금 생성하려 한 인덱스는 로컬 파티션 인덱스이므로 테이블 파티션 키 컬럼을 상속받아 seg가 파티션 키 컬럼인데, 이 컬럼이 인덱스 컬럼에 포함되지 않아 에러가 발생한 것이다.
1
CREATE INDEX t_idx4 ON t (seg, name) LOCAL;
위 CREATE INDEX 문은 로컬 Non-Prefixed 파티션 인덱스를 만드는 예시이다. 로컬 인덱스이므로 파티션 키가 seg이지만 이 컬럼이 인덱스 선두에 위치하지 않은 것을 확인하기 바란다. 앞서 생성한 t_idx2 Unique 인덱스도 마찬가지다.
지금까지 로컬 파티션 인덱스를 생성하는 예시를 보았고, 이제는 글로벌 파티션 인덱스를 생성해 보자.
방금 보았듯이 로컬 파티션 인덱스에는 Non-Prefixed가 허용되지만 글로벌 파티션 인덱스에는 허용되지 않는다.
인덱스 파티션 키인 seg를 인덱스 선두 컬럼에 두었더니 인덱스가 정상적으로 만들어졌다. 글로벌 Prefixed 파티션 인덱스가 생성된 것이다. 위와 같이 테이블 파티션과 같게 정의하더라도 이를 ‘로컬 파티션 인덱스’라고 부르지 않는다고 설명한 내용을 상기하기 바란다.
(7) 글로벌 파티션 인덱스의 효용성
결론부터 말하면 글로벌 파티션 인덱스는 경합을 분산시키려고 글로벌 해시 파티셔닝하는 경우 외에는 거의 사용되지 않는 실정이다.
‘비파티션 테이블에 대한 글로벌 파티션 인덱스’, ‘파티션 테이블에 대한 글로벌 파티션 인덱스’로 나누어 생각해볼 수 있는데, 전자의 경우 테이블을 파티셔닝하지 않을 정도로 중소형급 테이블이면 굳이 인덱스만을 따로 파티셔닝할 이유는 별로 없다.
후자, 즉 ‘파티션 테이블에 대한 글로벌 파티션 인덱스’의 효용성은 어떤가? 파티션 테이블에 대해서도 글로벌 파티션 인덱스보다는 로컬 파티션 인덱스와 비파티션 인덱스가 주로 사용되고 있으며, 그 이유를 아래 두 가지로 나누어 살펴보자.
1. 테이블과 같은 컬럼으로 파티셔닝하는 경우
테이블은 날짜 컬럼 기준으로 월별 파티셔닝하고, 인덱스는 분기별 파티셔닝하는 경우를 예로 들어보자. 글로벌 파티션 인덱스에는 Prefixed 파티션만 허용되므로 날짜 컬럼을 선두에 둬야 하는데, 날짜 조건은 대개 범위 검색 조건(between, 부등호)이 사용되므로 인덱스 스캔 효율 면에서 불리하다. 특히 NL 조인에서 Inner 테이블 액세스를 위해 자주 사용되는 인덱스라면 비효율이 더 크게 작용한다.
다른 조건 컬럼을 인덱스 선두에 둘 수 있다는 측면에선 로컬 Non-Prefixed 파티션 인덱스가 훨씬 유리하다.
두 달 이상의 넓은 범위 조건을 가지고 Inner 테이블 액세스를 위해 사용될 때는 로컬 Non-Prefixed 파티션 인덱스에도 비효율이 생긴다. 조인 액세스가 일어나는 레코드마다 여러 인덱스 파티션을 탐색해야 하기 때문이다. 따라서 NL 조인에서 넓은 범위 조건을 가지고 Inner 테이블 액세스를 위해 자주 사용된다면 비파티션 인덱스가 가장 좋은 선택이다.
2. 테이블과 다른 컬럼으로 파티셔닝하는 경우
테이블 파티션 기준인 날짜 이외의 컬럼으로 인덱스를 글로벌 파티셔닝할 수 있는데, (인덱스 경합을 분산하려는 경우가 아니라면) 그런 구성은 대개 인덱스를 적정 크기로 유지하려는 데에 목적이 있다. 인덱스가 너무 커지면 관리하기 힘들고 인덱스 높이(height)가 증가해 액세스 효율도 나빠지기 때문이다.
하지만 그런 장점도 로컬 파티션 인덱스 때문에 무색해진다. 글로벌 파티션이 비파티션보다 관리상 이점이 있다고는 하나 로컬 파티션만 못하고, 인덱스 높이 조절 측면에서도 그렇다.
(8) 로컬 Non-Prefixed 파티션 인덱스의 효용성
로컬 Non-Prefixed 파티션 인덱스는 이력성 데이터를 효과적으로 관리할 수 있게 해주며, 인덱스 스캔 효율성을 높이는 데에도 유리하다. 따라서 그 특성을 잘 파악하고 있어야 인덱스 및 파티션 설계 시 효과적인 전략을 구사할 수 있다.
일별 계좌별 거래 테이블을 예로 들어보자. (테이블명을 짧게 하려고 ‘일별 계좌별 거래’라고 명하였으나 일자와 계좌번호 외에 주문 매체, 거래 유형 등 다른 PK 속성들도 더 가지고 있다. 따라서 한 계좌당 거래 데이터가 하루에 한 개 이상일 수 있다.)
이력성 테이블은 거의 대부분 날짜 컬럼을 파티션 키로 사용하므로 여기서도 날짜 컬럼(거래 일자)을 기준으로 월 단위 Range 파티셔닝했다고 가정하자. 그리고 아래와 같은 조건절을 가진 쿼리가 자주 수행된다.
1
2
3
4
select sum(거래량), sum(거래금액)
from 일별계좌별거래
where 계좌번호 = :acnt_no
and 거래일자 between :d1 and :d2
로컬 Prefixed 파티션 인덱스와 비교
위와 같은 조건에 최적화된 인덱스를 만들려면 1장에서 설명했듯이 등치(=) 조건 컬럼을 선두에 두고 between 같은 범위 검색 조건 컬럼은 뒤쪽에 위치시켜야 한다. 그런 측면에서 거래 일자를 선두에 둔 로컬 Prefixed 파티션 인덱스는 스캔 효율이 나쁜데, 그림 6-11을 보면서 이해해보자.
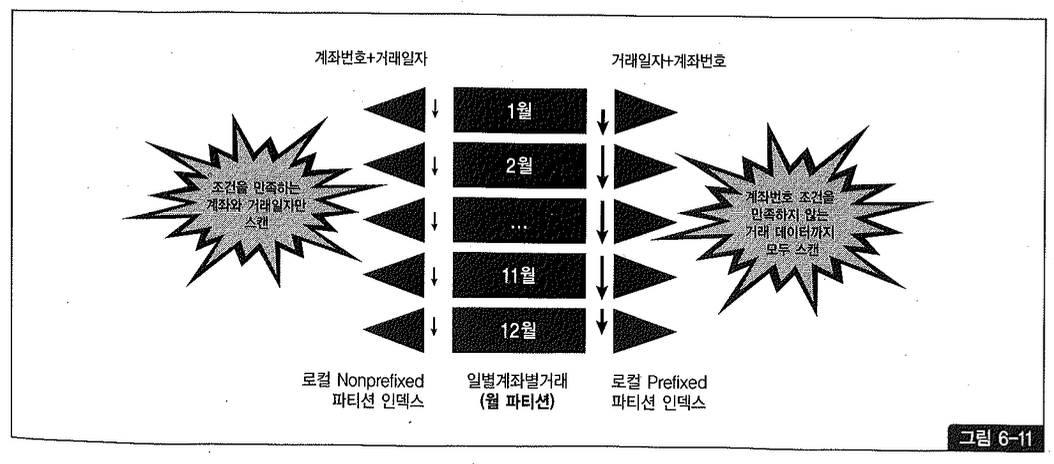
그림 6-11에 표시한 화살표는 특정 계좌에 대한 1월 15일부터 12월 15일까지 거래 데이터를 조회할 때의 인덱스 스캔 범위이다. 그림 우측 로컬 Prefixed 파티션 인덱스는 계좌번호 조건을 만족하지 않는 거래 데이터까지 모두 스캔하지만, 좌측처럼 계좌번호를 선두에 둔 로컬 Non-Prefixed 파티션 인덱스로 만들면 각 인덱스 파티션마다 필요한 최소 범위만 스캔하고 멈출 수 있다.
테스트를 통해 로컬 Prefixed 파티션과 로컬 Non-Prefixed 파티션 인덱스의 성능을 비교해보자. 테이블 생성 스크립트는 다운로드받아 확인하기 바라며(스크립트 ch6_09.kt 참조), 거래 일자 기준으로 테이블을 Range 월 파티셔닝했고, 10,000개 계좌번호로부터 1월부터 12월까지 매월 한 번씩 거래가 발생하도록 데이터를 입력했다. 그리고 로컬 Prefixed 파티션 인덱스(local_prefix_index)와 로컬 Non-Prefixed 파티션 인덱스(local_nonprefix_index)를 각각 생성했다.
글로벌 Prefixed 파티션 인덱스와 비교
글로벌 파티션 인덱스는 Prefixed 파티션만 허용되므로 거래 일자처럼 범위 검색 조건으로 자주 사용되는 컬럼이 선두일 때 로컬 Prefixed 파티션과 마찬가지로 인덱스 스캔 효율이 나쁘다(그림 6-12 우측 참조). 더욱이 과거 파티션을 제거(rolling-out)하고 신규 파티션을 추가(rolling-in)하는 등의 파티션 단위 작업 시 매번 인덱스를 재생성해야 하므로 관리적 부담이 크다.
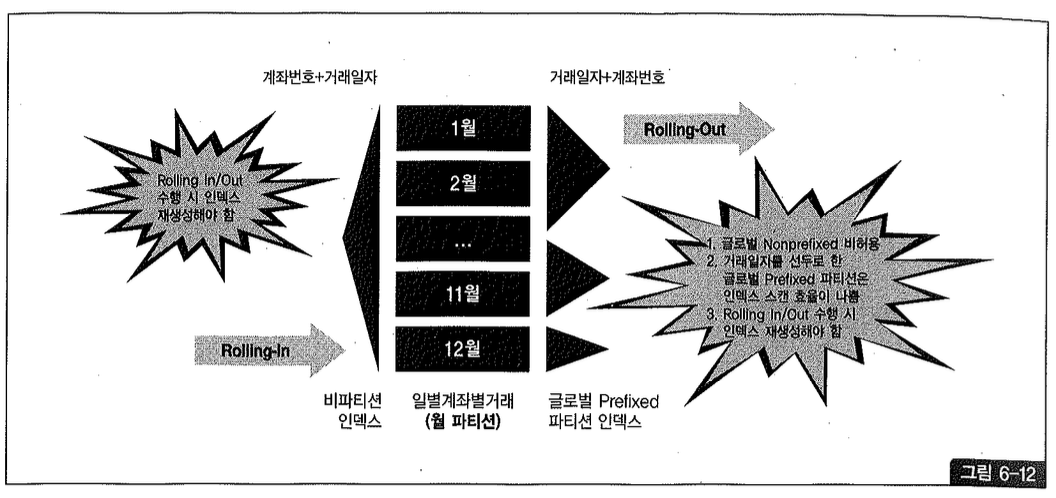
비파티션 인덱스와 비교
그림 6-12 좌측처럼 비파티션 인덱스를 이용하더라도 관리적 부담은 글로벌 파티션과 동일하게 발생한다. 따라서, 관리적 비용 측면에서는 그림 6-11 좌측과 같은 로컬 Non-Prefixed 파티션 인덱스가 훨씬 낫다.
조회 측면에서 로컬 Non-Prefixed 파티션 인덱스는, 두 달 이상에 걸친 넓은 범위의 거래 일자 조건으로 조회할 때 여러 인덱스를(수직적으로) 탐색해야 하는 비효율이 있다. 반면, 계좌번호를 선두에 둔 비파티션 인덱스는 여러 달에 걸친 거래 일자로 조회하더라도 인덱스 스캔 상 비효율은 없다. 하지만 아주 넓은 범위(예를 들어, 10년 치)의 거래 일자로 조회하거나 아래처럼 계좌번호만으로 조회할 때는 테이블 Random 액세스 부하 때문에 비파티션 인덱스도 제 성능을 내기 어렵다.
1
2
3
select sum(거래량), sum(거래금액)
from 일별계좌별거래
where 계좌번호 = :acnt_no
이럴 때 병렬 쿼리가 필요할 수 있는데, 아쉽게도 비파티션 인덱스에는 병렬 쿼리가 허용되지 않는다. 로컬 Non-Prefixed 파티션 인덱스라면 여러 병렬 프로세스가 각각 하나의 인덱스 세그먼트를 스캔하도록 함으로써 위 쿼리의 응답 속도를 크게 향상시킬 수 있다.
일 단위 파티셔닝
만약 테이블이 일 파티션되어 있다면, 그림 6-13 우측처럼 계좌번호만으로 로컬 Non-Prefixed 파티션 인덱스를 생성함으로써 인덱스 저장 공간을 줄이는 효과까지 얻을 수 있다. 인덱스 스캔 효율은 거래 일자를 포함한 좌측과 똑같다.
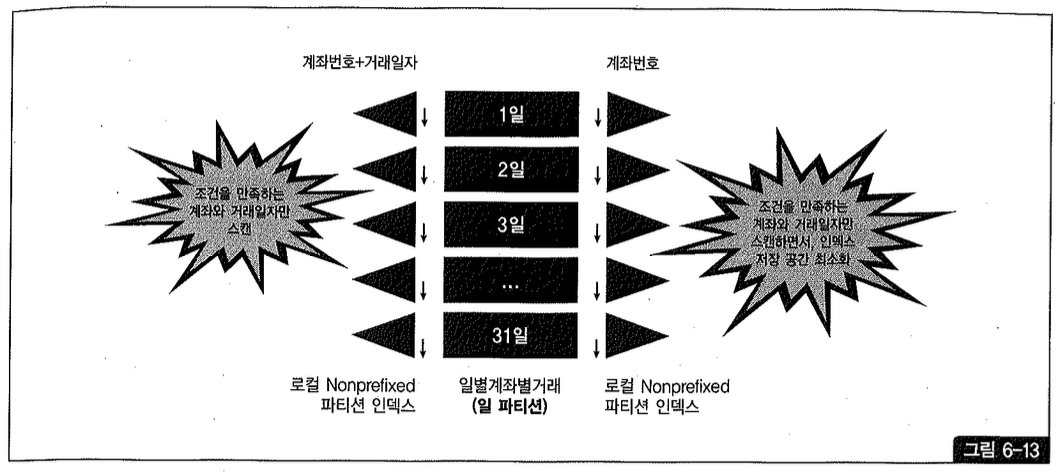
하지만 아래와 같은 쿼리를 수행할 때 계좌번호만으로 인덱스를 생성하면(그림 6-13 우측) 거래 일자를 읽기 위한 테이블 액세스가 발생하므로 불리하다.
1
2
3
4
select 계좌번호, count(*)
from 일별계좌별집계
where 거래일자 between '20090101' and '20090115'
group by 계좌번호
인덱스에 거래 일자가 포함돼 있을 때는(그림 6-13 좌측) 테이블을 액세스하지 않고 index fast full scan 방식으로 처리할 수 있다. index fast full scan에 대해서는 1강 3절(5)항을 참조하기 바란다.
(9) 액세스 효율을 고려한 인덱스 파티셔닝 선택 기준
지금까지 설명한 내용을 바탕으로 인덱스 파티셔닝 선택 기준을 정리해보자.
DW 성 애플리케이션 환경
DW/DSS 애플리케이션에는 날짜 컬럼 기준으로 파티셔닝된 이력성 대용량 테이블이 많다. 따라서 관리적 측면뿐만 아니라 병렬 쿼리 활용 측면에서도 로컬 파티션 인덱스가 좋은 선택이다. (비파티션 인덱스는 index fast full scan이 아닌 한 병렬 쿼리에 활용할 수 없다.)
로컬 인덱스 중에서는 Non-Prefixed 파티션 인덱스가 성능 면에서 유리할 때가 많다.
OLTP 성 애플리케이션 환경
OLTP 성 애플리케이션 환경에서는 비파티션 인덱스가 대개 좋은 선택이다. Right Growing 인덱스에 대한 동시 Insert 경합을 분산할 목적으로 해시 파티셔닝하는 경우가 아니라면 글로벌 파티션 인덱스는 효용성이 낮다.
OLTP 성이라도 테이블이 파티셔닝돼 있다면 인덱스 파티셔닝을 고려할 수 있는데, 특히 로컬 파티션 인덱스는 테이블 파티션에 대한 DDL 작업 후 인덱스를 재생성하지 않아도 되므로 가용성 측면에서 유리하다.
OLTP 환경에서는 로컬 인덱스 중 Prefixed 파티션이 Non-Prefixed 파티션보다 유리하다고 오라클 매뉴얼을 포함한 여러 문서에 설명돼 있는데, 필자는 이 말에 동의하기 어렵다. 그런 주장은, 파티션 키 컬럼이 검색 조건에서 빠졌을 때 로컬 Non-Prefixed 인덱스가 모든 인덱스 파티션을 스캔하는 데서 비롯된 것 같다. 예를 들어 아래와 같은 로컬 Non-Prefixed 파티션 인덱스를 말하며, 아래 조회 조건을 처리할 때는 파티션 키 컬럼이 조건절에 없어 모든 인덱스 파티션을 스캔하는 비효율이 생긴다.

반면, Prefixed 파티션 인덱스는 파티션 키 컬럼, 즉 인덱스 선두 컬럼이 검색 조건에 사용될 때만 사용되기 때문에 모든 파티션을 읽는 비효율은 발생하지 않는다.
그렇다면 파티션 키 컬럼에 대한 조건 없이 위와 같이 고객 번호만으로 조회하려 할 때는 인덱스를 어떻게 구성해야 하는가? OLTP 환경에서 로컬 Prefixed 파티션이 유리하다는 권고에 따라 인덱스를 아래와 같이 구성하면 인덱스가 아예 사용되지 않는다. 인덱스가 사용되도록 옵티마이저 힌트로 강제한다면 인덱스를 풀 스캔하므로 로컬 Non-Prefixed 파티션일 때보다 더 비효율적이다.

파티션 키에 대한 조건절이 없을 때 로컬 Prefixed 인덱스는 아예 사용이 안 되는 반면, Non-Prefixed 인덱스는 비효율이 있을지언정 잘 사용된다. 이 비효율이 문제라면 비파티션 인덱스가 대안이지 로컬 Prefixed 파티션 인덱스가 대안일 수 없다.
아래와 같이 파티션 키 컬럼에 대한 조건이 사용됐을 때를 기준으로 비교하면 로컬 Non-Prefixed 파티션이 Prefixed 파티션보다 확실히 유리하다.
1
2
select * from 고객 where 고객번호 = :cust_no and 거주지역 = :region;
select * from 주문 where 고객번호 = :cust_no and 주문일자 between :odt1 and :odt2;
거주 지역을 조건으로 검색하는 위쪽 쿼리는 Prefixed와 Non-Prefixed 간에 차이가 없다. 주문일자를 between 범위 검색 조건으로 검색하는 아래쪽 쿼리는 읽어야 할 파티션 개수는 똑같지만 인덱스 스캔 효율 면에서 Non-Prefixed 파티션이 낫다. 그림 6-11에 대한 설명을 참조하기 바란다.
Range 파티션 키가 주로 날짜 조건이고 부등호, between 같은 범위 검색 조건으로 자주 사용된다는 점을 감안하면, 로컬 Prefixed 파티션 인덱스가 유리하다는 권고안은 범위 검색 조건 컬럼을 항상 선두에 두라는 뜻이 돼버린다. 범위 검색 조건이 선두에 놓일 때 인덱스 스캔 과정에서 비효율이 발생하는 원리에 대해서는 1장에서 충분히 설명하였다.
아래와 같이 파티션 키 컬럼만으로 주로 조회한다면 로컬 Prefixed 파티션 인덱스를 만들면 된다. 이 경우 로컬 Non-Prefixed 인덱스는 고려 대상이 아니다. 고객 번호만으로 조회할 때, 즉 파티션 키에 대한 조건절이 없을 때 로컬 Prefixed 인덱스가 그랬던 것처럼 말이다.
1
2
select from 고객 where 거주지역 = :region;
select * from 주문 where 주문일자 between :odt1 and :odt2;
정리하면, OLTP 환경에서 로컬 인덱스를 선택했다면 Prefixed 파티션이든 Non-Prefixed 파티션이든 검색 조건에 항상 사용되는 컬럼(대개 날짜 컬럼)을 파티션 키로 선정하려고 노력해야 한다.
파티션 키가 범위 검색 조건으로 자주 사용된다면 Non-Prefixed 인덱스가 유리하고, 될 수 있으면 좁은 범위 검색이어야 한다. 특히, NL 조인에서 파티션 키에 대한 넓은 범위 검색 조건을 가지고 Inner 테이블 액세스 용도로 사용된다면 비파티션 인덱스를 사용해야 한다.
(10) 인덱스 파티셔닝 제약을 고려한 데이터베이스 설계
인덱스 파티셔닝에 대한 몇 가지 제약이 있는데, 그중 아래 두 가지는 반드시 기억해야 한다.
- Unique 파티션 인덱스를 정의할 때는 인덱스 파티션 키가 모두 인덱스 구성 컬럼에 포함되어야 한다. 이 제약이 없다면 인덱스 키 값을 변경하거나 새로운 값을 입력할 때마다 중복 값 체크를 위해 많은 인덱스 파티션을 탐색해야 하므로 DML 성능이 저하된다. 따라서 당연히 필요한 제약이라고 할 수 있다.
- 글로벌 파티션 인덱스는 Prefixed 파티션이어야 한다.
관리상 목적으로 대용량 테이블을 파티셔닝할 때도 있지만 많은 경우 성능 향상을 목적으로 한다. 즉, 인덱스를 통해 액세스할 데이터량이 아주 많아 빠른 성능을 내기 어렵고, Full Table Scan으로 처리하기에는 너무 많은 양을 읽어야 할 때 주로 파티셔닝을 실시하게 된다. 따라서 파티셔닝은 인덱스 전략 수립과 병행해야 한다. 자주 사용되는 액세스 패턴과 데이터 분포를 고려해 인덱스 전략을 수립하고, 인덱스만으로 빠른 성능을 내기 어려운 액세스 경로를 파악해 테이블 파티셔닝과 인덱스 파티셔닝 전략을 수립해야 한다.
이 과정에서, 방금 설명한 인덱스 파티셔닝 제약을 도외시한 채 설계를 진행한다면 실제 구현하는 단계에서 예상치 못한 문제에 직면할 수 있다.
한 가지 예를 들어보자. 여러 엔티티 타입을 하나로 통합해 슈퍼(Super)/서브(Sub) 타입 관계로 모델링하고, 물리적으로도 하나의 테이블로 통합할 때는 구분자(discriminator) 컬럼을 둔다. 그리고 통합한 테이블이 대용량일 때는 구분자 컬럼을 기준으로 파티셔닝하는 전략을 자주 사용한다.
이때 구분자 컬럼을 PK에 포함시키지 않고 일반 속성으로 두더라도 테이블을 파티셔닝하는 데에는 전혀 문제가 없지만, 인덱스를 파티셔닝하려는 순간 위에서 설명한 제약 때문에 원하는 형태로 구현하지 못하는 일이 발생할 수 있다.
따라서 테이블 파티셔닝을 고려하고 있다면 파티션 기준이 되는 구분자 컬럼을 물리 설계 단계에서 PK 컬럼에 포함시키는 것이 좋다. PK 컬럼은 엔티티를 식별하는 데 필요한 최소 컬럼 집합(minimal set of attributes)으로 구성해야 한다는 원칙에도 불구하고 말이다.
설명만으로 이해하기 어려운 내용이므로 구체적인 사례를 들어보자.
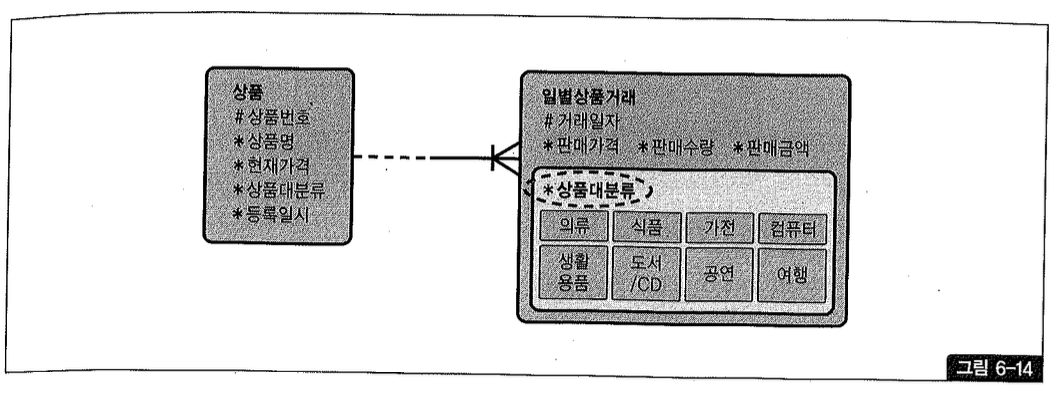
그림 6-14와 같은 데이터 모델에서 일별 상품 거래 엔티티에 있는 상품 대분류는 상품 엔티티로부터 반정규화한 컬럼이다. PK 속성 중 하나인 상품 번호로 상품 테이블과 조인하면 각 거래 데이터가 어느 시장에 속한 것인지 알 수 있지만 서브타입을 구분하려고 가져다 놓은 것이다.
논리적인 서브타이핑(Subtyping) 목적뿐만 아니라 여기서는 이 값을 기준으로 나중에 리스트 파티셔닝하려는 의도를 표현한 것이기도 하다. 엔티티를 하나로 통합하긴 했지만 MD(merchandiser) 조직이 상품 대분류를 기준으로 구성되다 보니 애플리케이션도 상품 대분류 조건을 항상 가지면서 독립적으로 데이터를 액세스한다. 그래서 물리적으로는 별도 세그먼트에 저장되도록 구현하려는 것이다.
물론 이런 고민은 물리 설계 단계에서 하는 것이 맞지만 논리 데이터 모델링 단계에서 이미 서브타이핑을 위한 구분자 컬럼이 필요해 미리 반정규화해 둔 것으로 이해하면 된다.
일별 상품 거래는 상품 번호와 거래 일자 두 컬럼만으로 Unique하므로 논리 모델 단계에서는 상품 대분류를 그림 6-14처럼 일반 속성으로 정의하는 것이 타당하다.