<오라클 성능 고도화 원리와 해법2> Ch07-02 병렬 Order By와 Group By
오라클 성능 고도화 원리와 해법2 - Ch07-02 병렬 Order By와 Group By
앞 절에서 강조했던 PP 데이터 재분배는 주로 병렬 ORDER BY, 병렬 GROUP BY, 병렬 조인을 포함한 SQL에서 나타난다. 아주 단순한 SQL이 아니고서야 대부분 이들 오퍼레이션을 포함하므로 거의 모든 병렬 SQL에서 Inter-Operation Parallelism이 일어난다고 보면 틀림없다.
병렬 ORDER BY에 대해서는 이미 1절에서 충분히 설명하였으므로 간단히 다루고, 본절에서는 주로 병렬 GROUP BY에 대해 설명하려고 한다. 병렬 조인은 3절과 4절에서 자세히 다룬다.
(1) 병렬 ORDER BY
병렬 ORDER BY와 병렬 GROUP BY를 설명하기 위해 사용할 테스트 데이터를 먼저 만들어보자. (스크립트 Ch7_02.txt 참조).
1
2
3
4
5
6
7
8
CREATE TABLE 고객 AS
SELECT rownum 고객ID,
dbms_random.string('U', 10) 고객명,
mod(rownum, 10) + 1 고객등급,
to_char(to_date('20090101', 'YYYYMMDD') + (rownum - 1), 'YYYYMMDD') 가입일
FROM dual
CONNECT BY level <= 1000;
EXEC dbms_stats.gather_table_stats(user, '고객');
방금 만든 고객 테이블을 병렬로 읽어 고객명 순으로 정렬하는 쿼리와 실행 계획은 다음과 같다.
1
2
3
4
5
SET autotrace traceonly explain
SELECT /*+ full(고객) parallel(고객, 2) */
고객ID, 고객명, 고객등급
FROM 고객
ORDER BY 고객명;
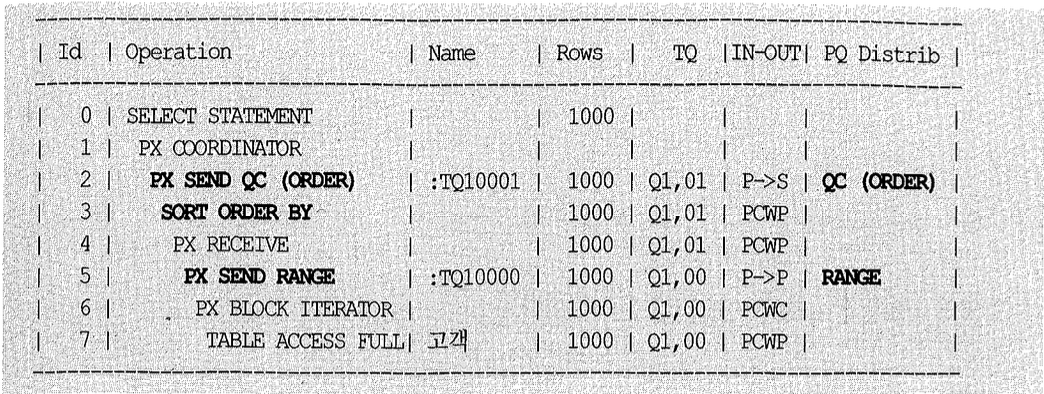
병렬 ORDER BY 처리 과정과 실행 계획 해석 방법에 대해서는 1절에서 이미 다루었으므로 부연 설명하지 않겠다. 대신 여기서는 앞절에서 설명하지 않았던 v$PQ_TQSTAT 뷰(Parallel Query Table Queue Statistics)의 활용법을 소개하려고 한다.
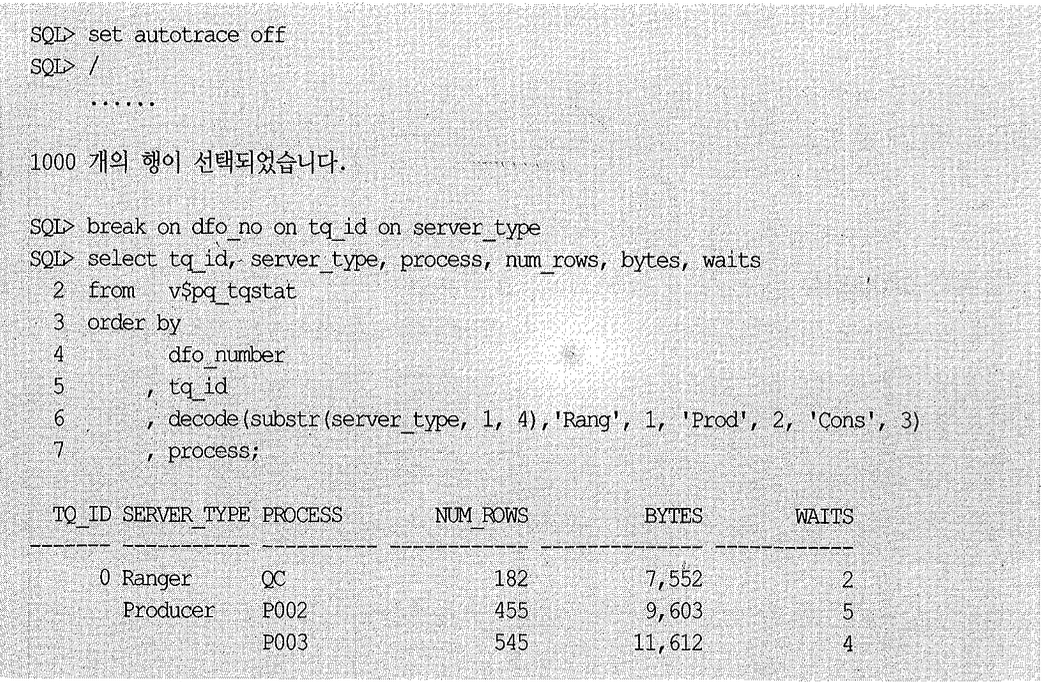
ORDER BY를 병렬로 수행하려면 테이블 큐를 통한 데이터 재분배가 필요한데, 쿼리 수행이 완료된 직후에 같은 세션에서 v$PQ_TQSTAT를 쿼리해보면 아래와 같이 테이블 큐를 통한 데이터 전송 통계를 확인해볼 수 있다.

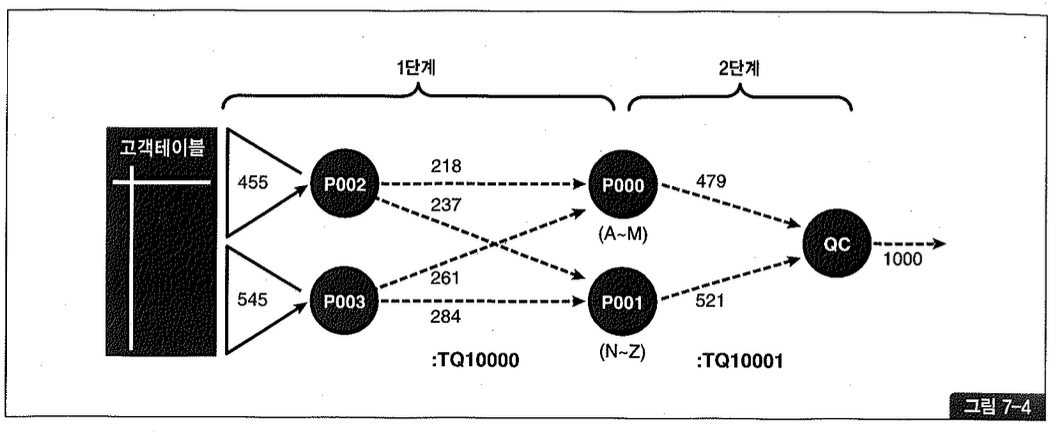
위 처리 과정을 도식화하면 그림 7-4와 같다.
병렬 쿼리 수행 속도가 예상만큼 빠르지 않다면 테이블 큐를 통한 데이터 전송량에 편차가 크지 않은지 확인해볼 필요가 있는데, 그럴 때 v$PQ_TQSTAT 뷰가 유용하게 쓰인다.
(2) 병렬 Group By
병렬 Group By가 어떻게 수행되는지 바로 앞서 만들어둔 고객 테이블을 이용해 살펴보자.


5장 소트 튜닝에서 설명했듯이 10gR2에서 hash group by가 소개되었고, 위 쿼리에 ORDER BY를 추가하면 아래와 같이 sort group by로 바뀐다.
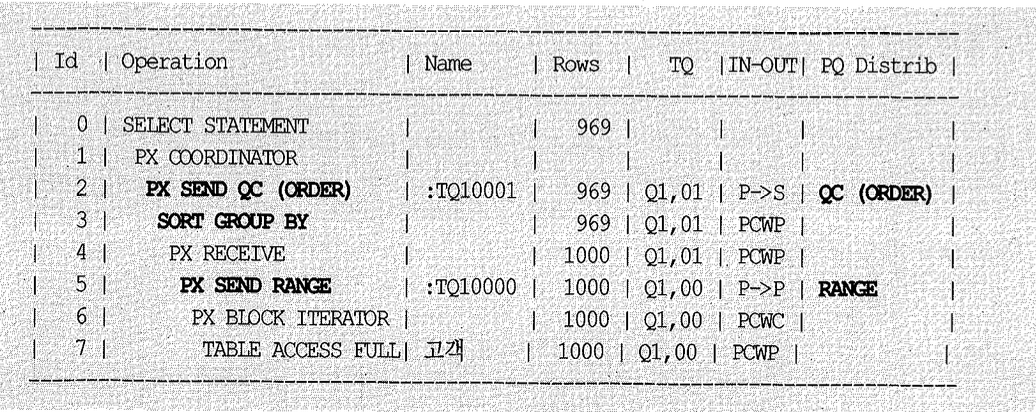
(1)항에서 본 병렬 ORDER BY 실행 계획을 방금 것과 비교해보면, 3번 단계의 ‘Sort order by’가 ‘Sort group by’로 바뀌는 것 말고는 모두 같다. 즉, ORDER BY와 GROUP BY를 병렬로 처리하는 내부 수행 원리는 기본적으로 같다는 뜻이다.
그리고 ‘병렬 sort group by’와 ‘병렬 hash group by’의 차이점은 데이터 분배 방식에 있다. 즉, group by 키 정렬 순서에 따라 분배하느냐 해시 함수 결과값에 따라 분배하느냐의 차이다. group by 결과를 QC에게 전송할 때도, sort group by는 값 순서대로(QC ORDER) 진행하지만 hash group by는 먼저 처리가 끝난 순서대로(QC RANDOM) 진행한다.
그림 7-2를 설명하면서 예로 들었던 명함 관리를 다시 생각해보자. 이번에는 명함을 그룹핑해서 고객사별로 연락 가능한 담당자가 몇 명인지를 집계하려고 한다.
우선, 8명의 영업사원이 각자 관리하던 명함을 집계하고 나면 그 결과를 영업부장(QC에 해당)이 최종적으로 집계하는 경우를 보자. 00물산 고객이 첫 번째 영업사원에게서 10명, 두 번째 영업사원에게서 5명으로 집계된다면 영업부장은 이를 합쳐 15명으로 최종 합계를 구해야 한다. 만약 각 영업사원이 집계한 고객사에 중복이 없다면(즉, 고객사별로 명함이 한 장씩만 있다면) 영업사원들이 한 것과 같은 일량의 집계 작업을 영업부장이 한 번 더 수행하는 셈이 된다. 병렬 ORDER BY도 각각 정렬된 결과집합을 최종 머지(Merge)하는 작업의 복잡성 때문에 이와 같은 방식은 그다지 효과적이지 않다고 설명한 것을 기억할 것이다.
ORDER BY와 마찬가지로, 병렬 GROUP BY도 두 집합으로 나눠 한쪽은 명함을 읽어서 분배하고 다른 한쪽은 그것을 받아 집계하도록 해야 병렬 처리 효과를 극대화할 수 있다.
바로 앞서 보았던 GROUP BY 쿼리 예제로 다시 돌아와, 직접 쿼리를 수행하고서 v$PQ_TQSTAT 결과를 통해 병렬 GROUP BY 과정을 설명해보자. (hash group by를 기준으로 설명한다.)
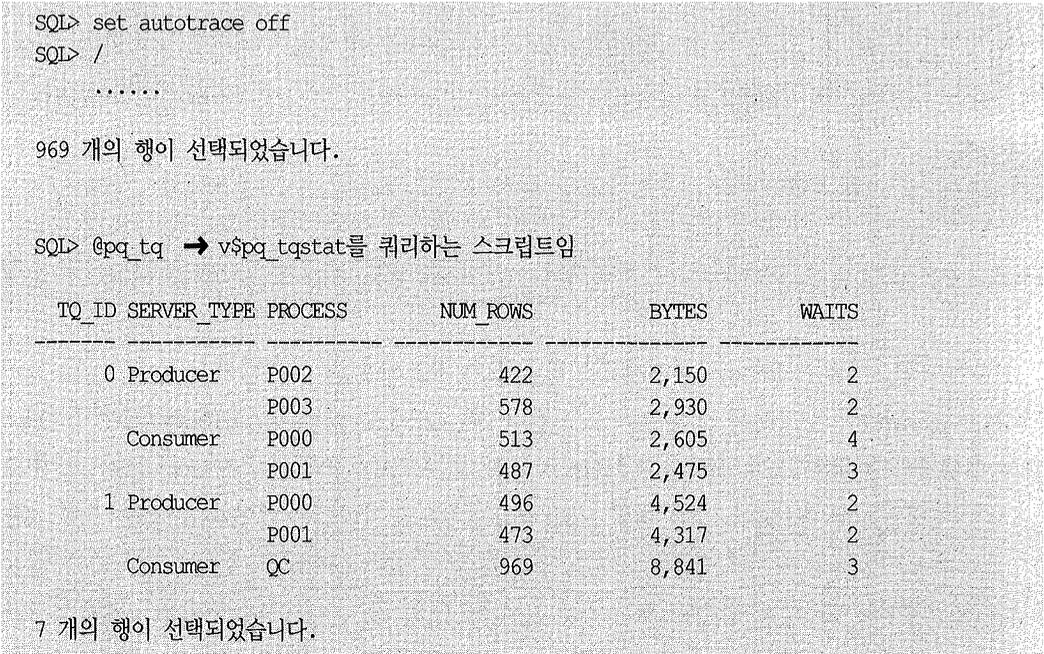
P002와 P003은 각각 422와 578개의 로우를 읽어 해시 함수를 적용하고, 거기서 반환된 값에 따라 두 번째 서버 집합으로 데이터를 분배하였다. 그 과정에서 P000은 513개 로우를 받아 GROUP BY한 결과 496개 로우를 QC에게 전송하였다. P001도 487개 로우를 받아 GROUP BY한 결과 473개 로우를 QC에게 전송하였다.
그림 7-5는 이런 과정을 도식화한 것이다.
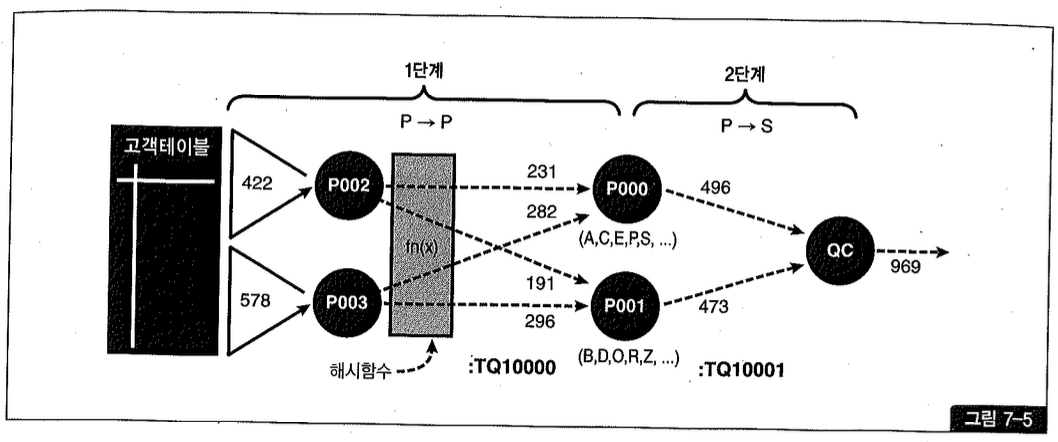
해시 값에 따라 데이터를 분배하였으므로 P000과 P001은 서로 배타적인 집합을 가지고 GROUP BY를 수행했다. 따라서 QC가 한 번 더 집계하는 과정 없이 받은 데이터를 그대로 클라이언트에게 전송하면 된다.
GROUP BY가 두 번 나타날 때의 처리 과정
병렬 GROUP BY 실행 계획에 아래와 같이 GROUP BY가 두 번(D3, D6) 나타나는 경우가 있다. GROUP BY를 두 번 수행하는 것일까?
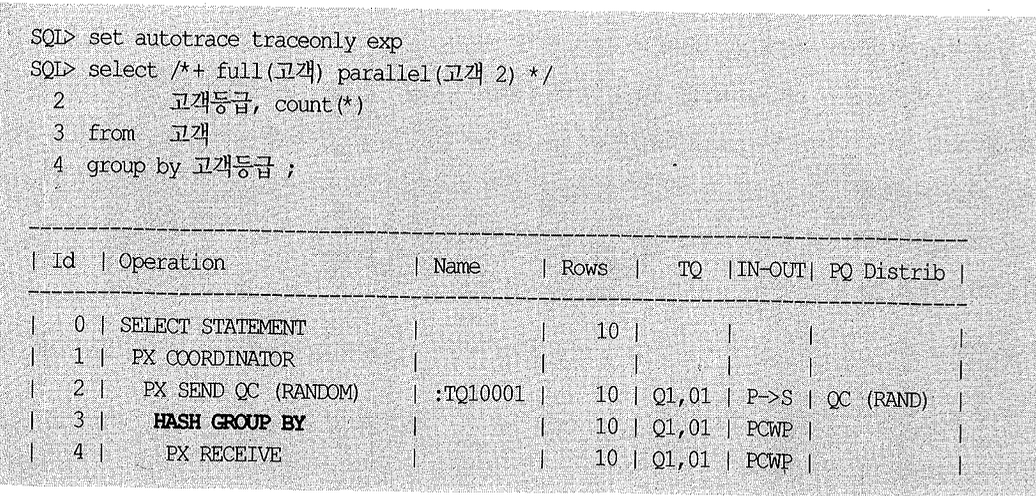

비밀은 GROUP 기준 컬럼의 선택도(selectivity)에 있다.
고객명의 선택도는 0.001(0.1%)로서 매우 낮고, 고객등급의 선택도는 0.1(10%)로서 비교적 높다. 즉, 고객등급으로 GROUP BY한 결과 집합은 원래의 데이터 집합과 비교하면 1/10 크기다. 따라서 첫 번째 서버 집합이 읽은 데이터를 먼저 GROUP BY하고 나서 두 번째 서버 집합에 전송한다면 프로세스 간 통신량이 1/10로 줄어 그만큼 병렬 처리 과정에서 생기는 병목을 줄일 수 있다. (1절 마지막 항에 설명한 ‘병렬 처리 과정에서 발생하는 대기 이벤트’를 참고하기 바란다.)
앞에서 GROUP BY가 한 번 나타날 때와 비교했을 때 프로세스 간에 주고받은 데이터 건수가 현격히 준 것을 확인할 수 있다. 그림 7-6은 그 처리 과정을 도식화한 것이다.
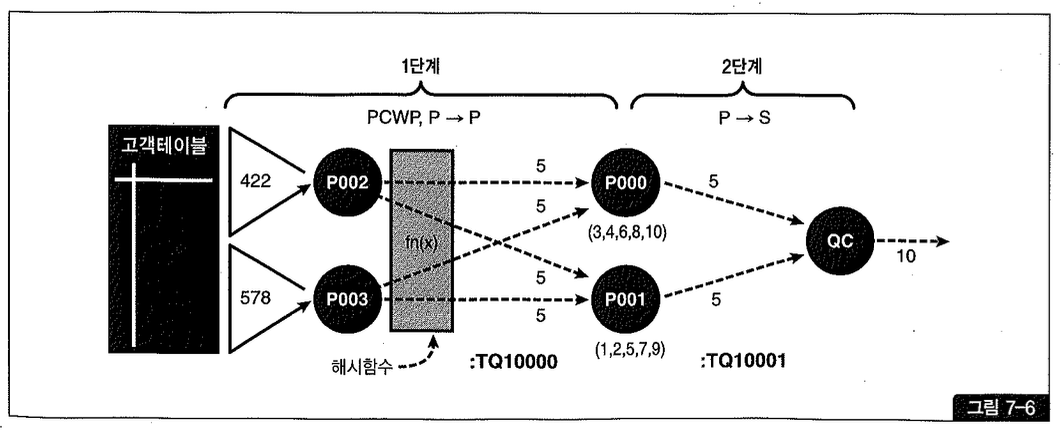
P002와 P003이 GROUP BY한 결과 집합을 해시 값에 따라 분배하고 나면 P000과 P001은 서로 배타적인 집합을 갖게 된다. 하지만 받은 데이터가 최종 집계된 값이 아니므로 P000과 P001 프로세스는 한 번 더 GROUP BY를 수행해야만 한다. 예를 들어, P000 프로세스가 6등급 데이터를 P002와 P003 프로세스 모두로부터 받을 수 있기 때문이다.
두 번째 서버 집합의 최종 집계가 끝나고 나면 QC는 이를 받아서 그대로 클라이언트에게 전송하면 된다.